Science of Science — Paper Curation
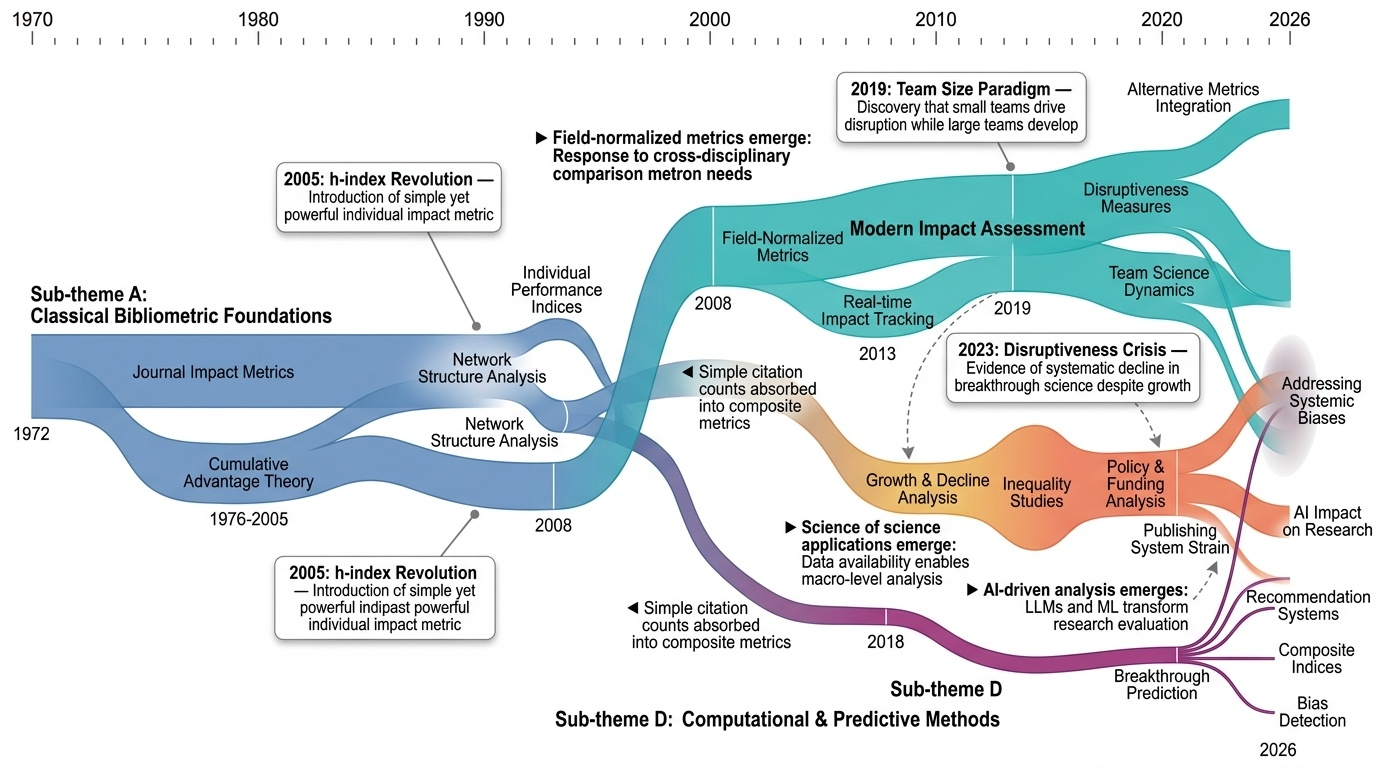
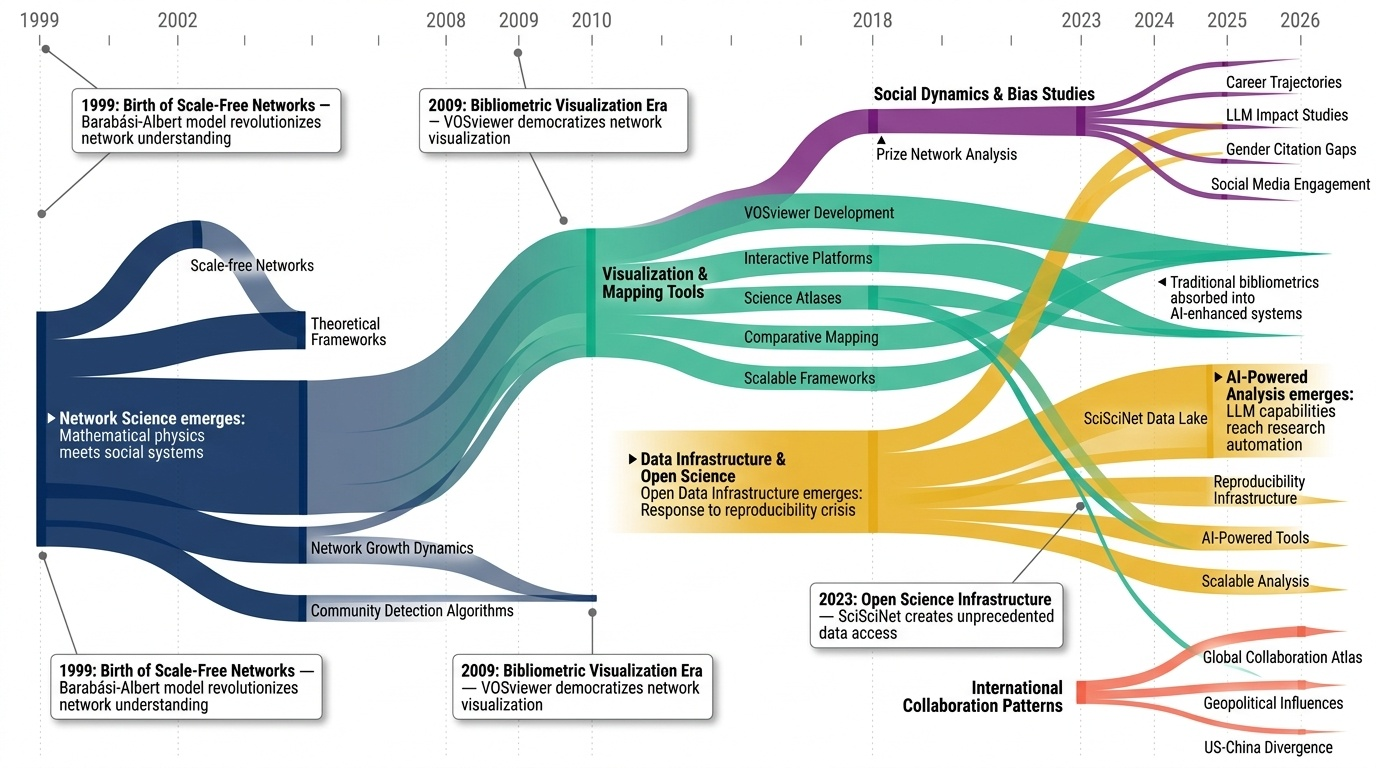
Research Timeline
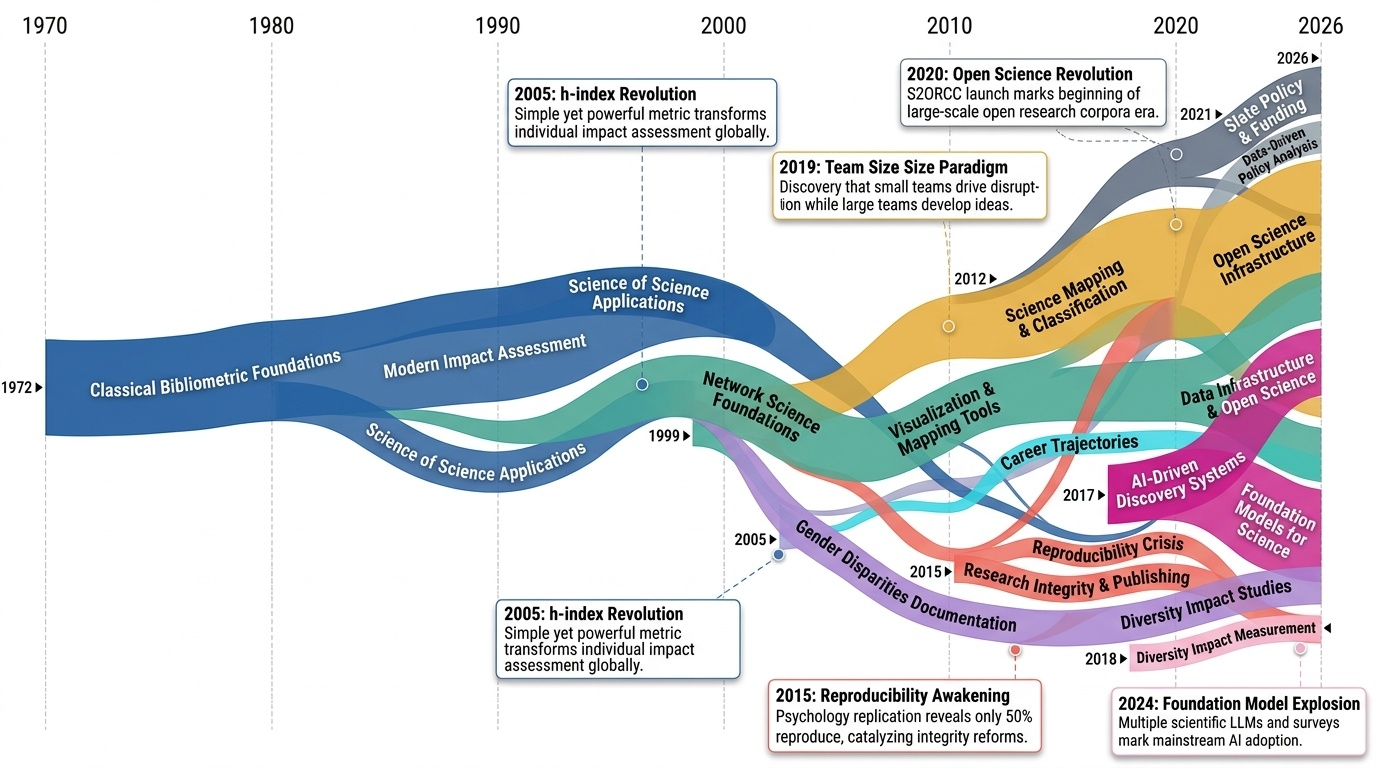
과학의 과학(Science of Science) 분야는 1972년 과학인용색인(Science Citation Index) 분석에서 시작하여 현재 AI 기반 자동화 연구 시스템에 이르기까지 반세기에 걸쳐 급격한 변화를 겪어왔다. 초기에는 Hirsch(2005)의 h-index와 같은 단순한 계량서지학적 지표 개발에 집중했으나, 2010년대 들어 대규모 데이터와 계산 방법론의 발전으로 연구의 패러다임이 전환되었다. 특히 Barabási와 Albert(1999)의 척도 없는 네트워크(scale-free network) 발견은 과학 협력 네트워크 분석의 이론적 토대를 마련했고, 이후 VOSviewer(2009) 같은 시각화 도구의 등장으로 복잡한 연구 네트워크를 직관적으로 이해할 수 있게 되었다.
2015년을 전후로 재현성 위기(reproducibility crisis)가 대두되면서 연구 무결성에 대한 관심이 급증했다. 심리학 재현 프로젝트는 연구의 50%만이 재현 가능하며 효과 크기도 절반에 불과하다는 충격적인 결과를 보여주었다. 이는 Ioannidis(2005)가 제기한 "왜 발표된 연구 결과의 대부분이 거짓인가"라는 문제의식을 실증적으로 확인한 것이었다. 동시에 과학계의 다양성과 형평성 문제도 주목받기 시작했는데, 2018년 최초로 인종적 다양성이 인용 영향력에 미치는 긍정적 효과가 대규모로 입증되었고, 2022년에는 120만 명의 박사학위자 분석을 통해 소수집단이 더 혁신적인 연구를 수행하지만 인정받지 못한다는 다양성 역설이 밝혀졌다.
2020년대 들어 가장 주목할 만한 변화는 AI와 대규모 언어모델(LLM)의 과학 연구 통합이다. S2ORC(2020)와 OpenAlex(2022) 같은 개방형 연구 데이터 인프라의 구축은 전례 없는 규모의 분석을 가능하게 했고, 2024년 OLMo와 같은 과학 특화 기반 모델(foundation model)의 등장은 자동화된 가설 생성과 검증의 시대를 열었다. 특히 AI Scientist 프레임워크는 연구의 전 과정을 자동화하려는 야심찬 시도로, MOLIERE 같은 가설 생성 시스템에서 시작된 흐름이 완전한 연구 자동화로 진화하고 있음을 보여준다.
현재 이 분야는 여러 중요한 전환점에 직면해 있다. 첫째, 과학적 혁신성이 체계적으로 감소하고 있다는 증거가 축적되면서 대규모 팀 과학과 소규모 혁신적 연구 간의 균형 문제가 대두되었다. Wu 등(2019)은 소규모 팀이 파괴적 혁신을 주도하는 반면 대규모 팀은 기존 아이디어를 발전시킨다는 것을 밝혔다. 둘째, AI의 급속한 발전이 연구 평가와 수행 방식을 근본적으로 변화시키면서 동시에 새로운 형태의 편향과 검증 문제를 야기하고 있다. 2026년 A-lab 검증 논란은 자동화된 과학 시스템의 신뢰성 문제를 부각시켰다. 셋째, 지정학적 요인이 국제 협력 패턴에 미치는 영향이 커지면서, 특히 미중 간 연구 협력의 분기가 관찰되고 있다.
향후 이 분야는 AI 기반 메타과학 분석의 성숙, 시간적 동태를 고려한 동적 지식 표현 시스템의 발전, 그리고 과학 정책과 펀딩 전략의 증거 기반 최적화로 나아갈 것으로 전망된다. 특히 AI가 과학 자체에 미치는 영향을 AI로 분석하는 재귀적 연구가 체계화되면서, 과학의 과학은 단순한 관찰과 측정을 넘어 과학 활동의 능동적 설계와 개선을 위한 도구로 진화하고 있다.
Research Insights 5 findings
Category Overview
# AI for Science 카테고리: Citation & Impact Analysis 개요 본 카테고리는 과학 연구의 인용도(Citation Metrics & Measurement) 측정과 연구 영향력(Research Impact & Innovation) 평가에 관한 31편의 논문을 포괄한다. 핵심 주제는 h-지수, g-지수, 상대인용비율(Relative Citation Ratio) 등 다양한 bibliometric 지표 개발 [1047][1009][928] 및 논문의 장기적 과학적 영향력 정량화 [1003]이다. 자금 지원 및 연구 산출(Funding & Research Outputs) 차원에서는 공공 자금의 과학 활용 현황 [1002], 실제 증거(Real-World Evidence) 기반 정책 영향 [1006], 그리고 연구 실패의 동역학 [1005]을 다룬다. 과학 협력 및 네트워크(Scientific Collaboration & Networks) 영역에서는 학술 출판 생태계(Scholarly Knowledge Ecosystem) [1042], 과학 협력 네트워크의 구조 [1046], 및 커뮤니티 구조를 가진 네트워크의 성장 모델 [1040]을 분석한다. 형평성 및 다양성(Equity & Diversity in Science) 측면에서는 COVID-19 팬데믹의 불균등한 과학자 영향 [1048], 저널 인용 편향(Journal Citation Bias) [1008], 오픈 액세스의 인용 이점(Open Access Citation Advantage) [932]을 검토하며, 추가로 출판 부담[1045], 정책 수립에서의 학제간 지식 활용 [1043], 그리고 거대 언어모델(Large Language Models)의 과학 영향 방향 [1041]을 다룬다.
- Citation Metrics & Measurement: 인용 지표 및 측정(Citation Metrics & Measurement)은 학술 출판물의 영향력과 기여도를 정량적으로 평가하는 학문 분야입니다. 이 분야의 연구들은 h-index, g-index, Relative Citation Ratio(RCR) 등 다양한 인용 지표의 이론적 토대와 실제 적용 방법을 다루고 있습니다[1009], [1047]. 특히 저널의 명성이 인용 편향(citation bias)에 미치는 영향[1008], 개방 접근(open access)이 인용 이점에 미치는 영향[932], 그리고 인용 분포의 보편성(universality of citation distributions)에 관한 연구들이 포함되어 있습니다[1049]. 또한 누적 이득 이론(cumulative advantage theory)의 일반 이론과 학술 출판 체계의 구조적 문제점을 분석한 연구들[928], [1045]도 이 분야의 중요한 기초를 이루고 있으며, 저자의 공개 프로필이 인용 측정에 미치는 영향을 다룬 연구[1001]도 포함됩니다. 이러한 연구들은 학술 커뮤니티의 영향력 평가를 더욱 객관적이고 신뢰할 수 있게 만드는 데 기여하고 있습니다.
- Research Impact & Innovation: **Research Impact & Innovation (연구 영향력과 혁신)** 이 부문은 학술 연구가 과학, 기술, 정책 분야에서 미치는 실질적인 영향력과 혁신성을 정량적으로 분석하는 연구들을 다룬다. [1003]과 [1005]는 장기적 과학적 영향(Long-term Scientific Impact)과 실패의 역학(Dynamics of Failure)을 정량화하여 연구 성과의 지속성을 측정한다. 또한 [934], [954], [995]는 논문의 혁신성(Disruptiveness)과 새로움(Novelty)이 기술 채택, 사회적 관심, 특허 영향력에 미치는 영향을 실증적으로 검증한다. [1042]와 [1043]은 학술 지식 생태계(Scholarly Knowledge Ecosystem)의 구조적 문제점과 학제 간(Interdisciplinary) 지식이 정책 결정에 활용되는 메커니즘을 분석하여, 연구 영향력을 극대화하기 위한 제도적 개선 방안을 제시한다. 이러한 연구들은 논문의 질적 가치를 평가하고 사회적 임팩트(Impact)를 최적화하는 데 중요한 학술적 기초를 제공한다.
- Funding & Research Outputs: # Citation & Impact Analysis: Funding & Research Outputs 공공 자금으로 지원되는 과학 연구의 산출물과 영향력을 분석하는 분야입니다. [1002]에서 다루는 공공 자금(public funding)과 과학의 공공성(public use of science)은 연구 투자의 효율성과 사회적 가치 창출을 평가하는 핵심 지표입니다. [1006]과 [1041]은 각각 실증적 증거(real-world evidence)와 대형 언어 모델(large language models)의 등장이 연구 방향성과 임팩트(impact)에 어떠한 영향을 미치는지 분석합니다. 이러한 연구들은 정부 R&D 투자의 책임성(accountability)과 함께 신기술이 학문 분야의 발전에 미치는 변혁적 영향을 이해하는 데 중요한 역할을 합니다. 궁극적으로 연구 자금과 산출물의 관계를 통해 과학 혁신의 경로(trajectory)와 사회적 수익성(social return on investment)을 체계적으로 평가할 수 있습니다.
- Scientific Collaboration & Networks: 과학적 협력과 네트워크(Scientific Collaboration & Networks)는 현대 과학 연구의 핵심 특성으로, 연구자들 간의 상호작용과 협력 구조를 분석하는 분야입니다. [1046]은 과학 협력 네트워크의 구조적 특징을 규명하여 연구자들이 어떻게 상호연결되어 있는지를 보여줍니다. [979]는 팀 규모와 혁신 사이의 관계를 탐구하며, 대규모 팀(Large teams)은 기존 과학을 발전시키고 소규모 팀(Small teams)은 파괴적 혁신(Disruptive innovation)을 주도한다는 패턴을 제시합니다. [1040]은 커뮤니티 구조(Community structure)를 포함한 네트워크 성장 모델을 분석하여 협력 네트워크가 어떻게 형성되고 진화하는지를 설명합니다. 이러한 연구들은 과학 생태계에서 협력의 역할과 효과를 이해하는 데 중요한 통찰력을 제공합니다.
- Equity & Diversity in Science: # Equity & Diversity in Science (2편) 과학 연구 분야에서 인용 및 영향력 분석은 학문적 성과를 측정하는 중요한 지표입니다. 본 주제는 이러한 인용 지표(citation metrics)가 과학자 집단 간에 얼마나 불평등하게 분포되어 있는지를 다룹니다. [1048]은 COVID-19 팬데믹이 서로 다른 배경의 과학자들에게 미친 차별적 영향을 분석하여, 특정 집단이 더 큰 학술적 피해를 입었음을 보여줍니다. [966]은 글로벌 차원에서 인용 불평등(citation inequality)이 지속적으로 증가하고 있는 추세를 규명하며, 이는 학문적 기여도의 정량적 평가에서 체계적인 편향(bias)이 존재함을 의미합니다. 이러한 연구들은 과학 생태계(scientific ecosystem) 내 다양성과 공평성을 확보하기 위한 구조적 개선의 필요성을 강조합니다.
⚠ 갭: 학문분야별 특성을 반영한 맞춤형 인용 분석 지표와 평가 모델이 부족하다
🏛 정책: 다차원적 연구영향력 평가를 위한 새로운 지표 개발과 평가체계 개선이 필요하다
Public Profile Matters: A Scalable Integrated Approach to Recommend Citations in the Wild

 *Figure 2: The architecture of our two-stage citation recommendation system. (1) The non-learnable Profiler* 논문은 인용문헌 추천을 위해 연구자의 인용 행동 패턴을 효율적으로 포착하는 경량 Profiler 모듈과 이를 통합한 DAVINCI 재순위 모델을 제안한다. 또한 현실을 반영하는 귀납적 평가 설정(inductive evaluation)을 도입하여 기존 평가 프로토콜의 한계를 지적한다.
논문은 인용문헌 추천의 현실적 문제(편향, 효율성, 평가 프로토콜)를 명확히 진단하고 경량성과 공정성을 갖춘 실용적 해결책을 제시한다. 귀납적 평가 설정의 도입은 학계에 의미 있는 기여이며, 공개 프로필의 중요성 강조는 새로운 관점을 제공한다.
Reinforcing Prestige: Journal Citation Biases in Astronomy
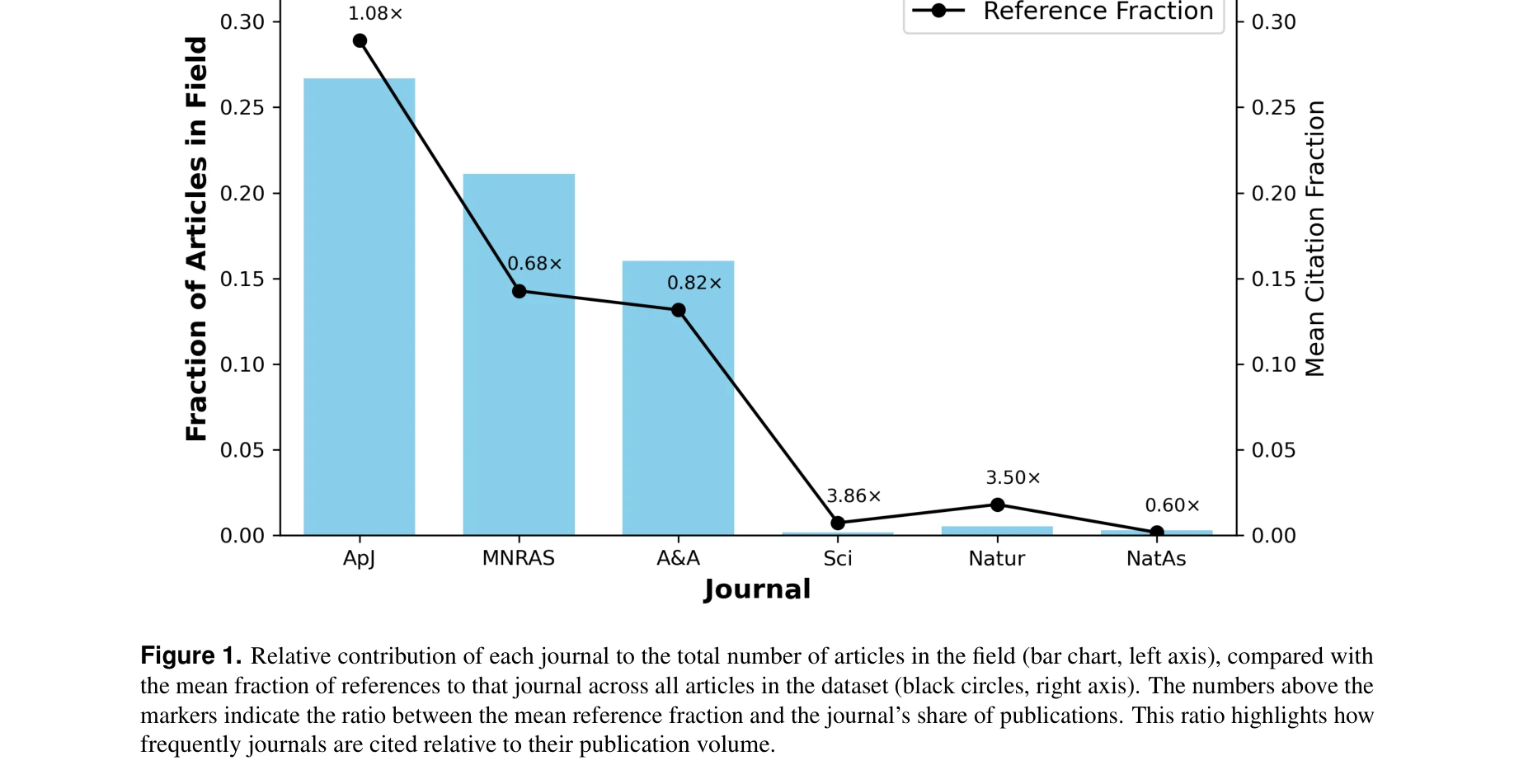
Figure 1. Relative contribution of each journal to the total number of articles in the field (bar chart, left axis), com
 *Figure 1. Relative contribution of each journal to the total number of articles in the field (bar chart, left axis), com* 천문학 분야의 약 255,000개 논문을 분석하여 저널 인용 편향을 조사했으며, 다학제 저널이 출판량 대비 최대 9배 높은 인용을 받는 반면 분야 특화 저널은 불리함을 발견했다.
이 연구는 과학 출판 생태계에 내재한 구조적 인용 편향을 대규모 데이터로 처음 체계적으로 입증한 중요한 작업이며, Matthew Effect를 정량적으로 확인하여 인용 기반 평가의 오용 위험성을 경고한다. 특히 저자의 자체 저널 선호도 편향은 개인 및 기관 수준의 출판 결정 과정에 대한 새로운 통찰을 제공한다.
Relative Citation Ratio: A New Metric That Uses Citation Rates to Measure Influence at the Article Level
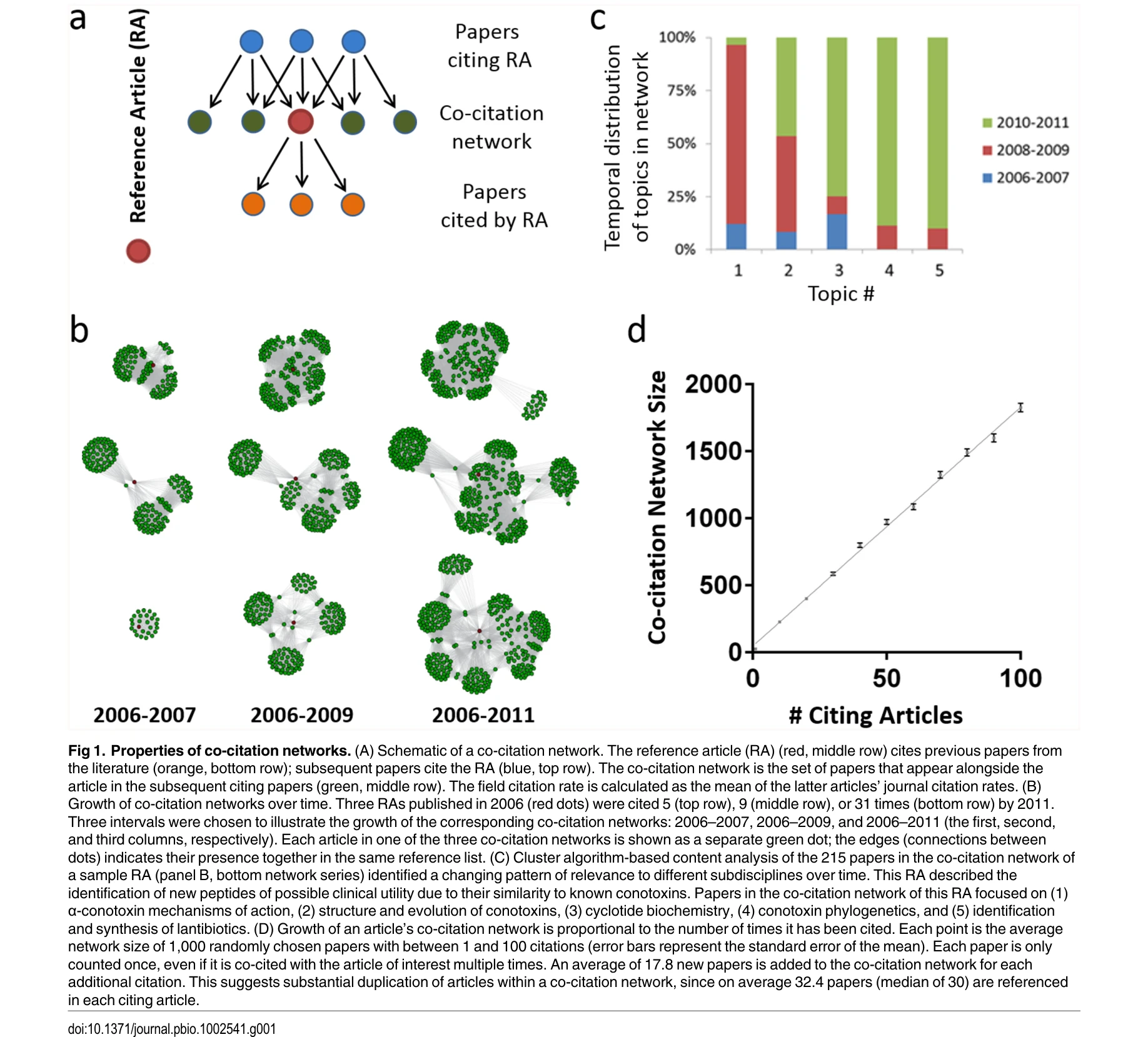
Fig 1. Properties of co-citation networks. (A) Schematic of a co-citation network. The reference article (RA) (red, midd
 *Fig 3. Algorithm for calculating the Relative Citation Ratio (RCR). (A) Article citation rate (ACR) is calculated as the* 공동인용 네트워크(co-citation network)를 활용하여 논문의 인용 수를 분야별로 정규화한 상대인용률(RCR: Relative Citation Ratio)을 제안하고, 이를 통해 저널임팩트팩터(JIF)를 대체할 수 있는 논문 수준의 영향력 평가 지표를 개발했다.
본 논문은 공동인용 네트워크를 활용한 혁신적 정규화 기법과 실용적 벤치마킹 시스템을 통해 학술 영향력 평가의 오랜 과제를 해결하는 중요한 기여를 한다. 공개 도구(iCite)를 통한 즉시 접근성과 전문가 의견과의 높은 상관성으로 인해 학술 평가 관행 개선에 실질적 영향을 미칠 수 있는 우수한 연구다.
The strain on scientific publishing
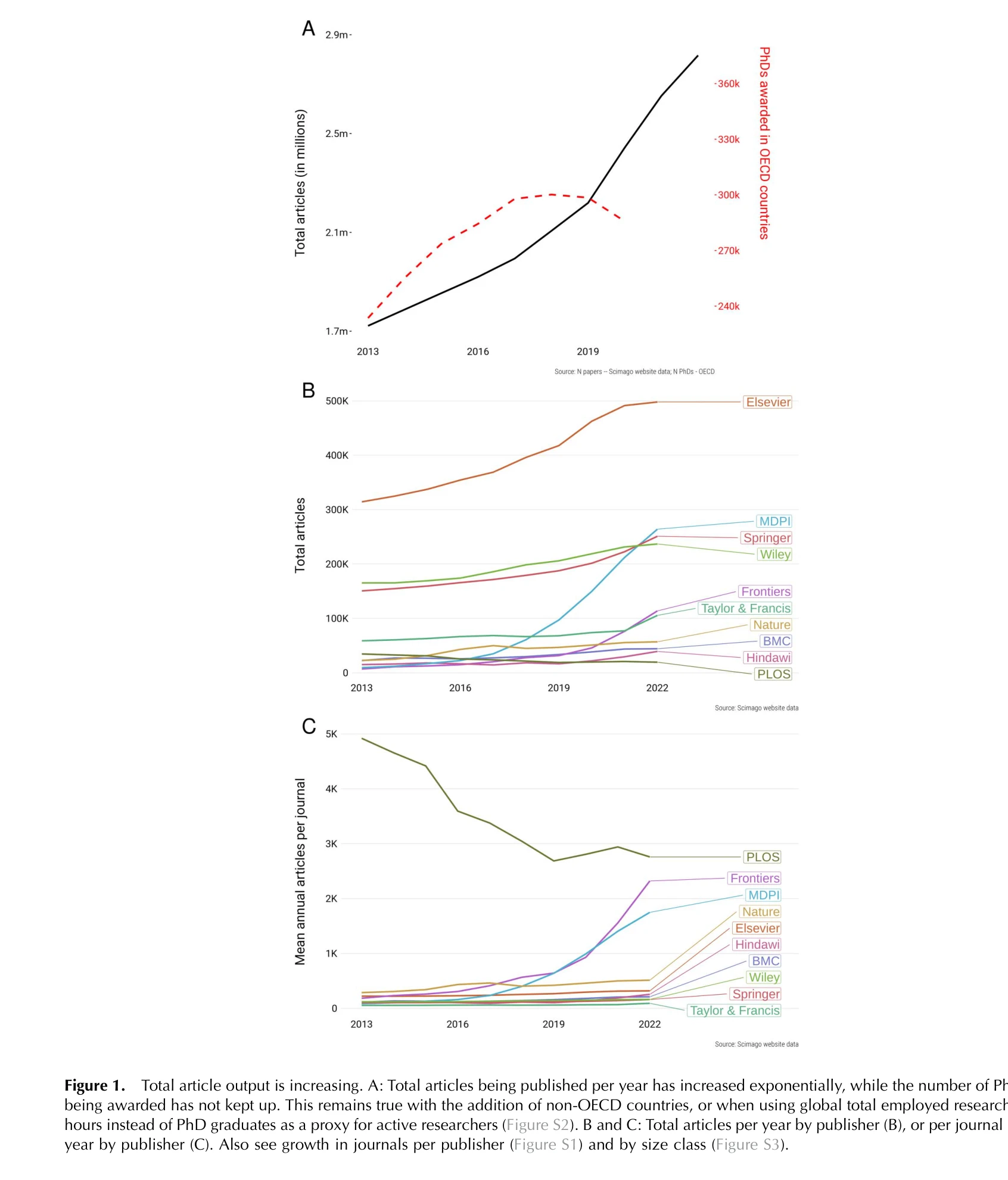
Scopus와 Web of Science 데이터 분석을 통해 2016-2022년 과학 논문 출판량이 47% 증가하면서 과학자당 출판 부담(strain on scientific publishing)이 급증했으며, 이를 5가지 데이터 기반 지표로 정량화하고 출판사 비즈니스 모델과의 연관성을 분석했다.
본 논문은 학술 출판의 지수적 성장이라는 알려진 현상을 5가지 정량적 메트릭으로 체계화하고, Love Triangle 프레임워크로 출판 시스템의 구조적 인센티브를 규명하여, 정책 입안자와 출판사에게 actionable한 진단을 제공한다. 특히 impact inflation 지표와 비즈니스 모델별 차별 분석이 핵심 기여이나, 인과 메커니즘 규명과 글로벌 포함성 영향 분리는 후속과제로 남겨진다.
Theory and Practice of the g-index
h-지수의 개선된 버전인 g-지수를 제안하며, g-지수는 상위 g개 논문의 총 인용 수가 g²개 이상인 최대값 g로 정의된다. Lotka 법칙 기반의 수학적 이론을 제시하고 Price 메달리스트의 데이터로 검증한다.
본 논문은 h-지수의 명확한 한계를 진단하고 우아한 수학적 정의(g²)로 개선한 g-지수를 제시하며, Lotka 법칙과의 연결을 통해 이론적 깊이를 부여했다. 실제 데이터 검증과 존재성 증명으로 신뢰성을 확보하여 scientometrics 분야에 중요한 기여를 한다.
Universality of citation distributions: Toward an objective measure of scientific impact
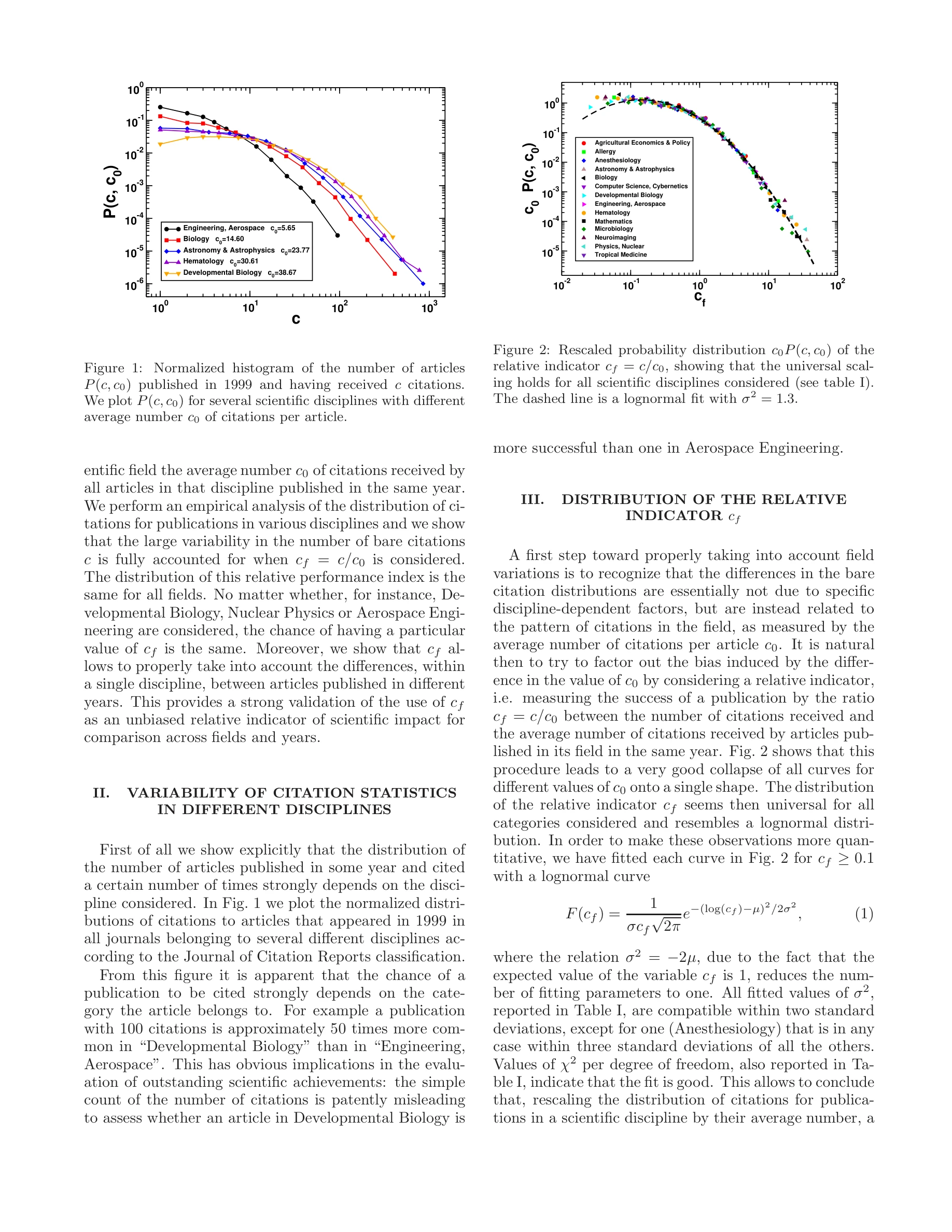
Figure 1: Normalized histogram of the number of articles
 *Figure 2: Rescaled probability distribution c0P(c, c0) of the* 다양한 학문 분야의 인용 분포(Citation Distribution)가 평균 인용 수로 정규화하면 보편적(Universal) 곡선을 따르며, 이를 통해 학문 간 과학적 영향력을 객관적으로 비교할 수 있는 지표 cf = c/c₀를 제시한다.
인용 분포의 보편성을 실증적으로 입증하고 객관적 비교 지표 cf를 제시한 획기적 연구로, 과학 성과 평가의 공정성 개선에 중요한 기여를 한다. 다만 실제 적용 시 다층적 편향 요소의 추가 고려가 필요하다.
A General Theory of Bibliometric and Other Cumulative Advantage Processes
누적 이득(Cumulative Advantage) 원리를 따르는 확률 분포 이론을 제시하여 '성공이 성공을 낳는' 현상을 설명하고, 이것이 베타 함수로 지배되며 문헌계량학의 다양한 경험 법칙들의 기초가 됨을 보임.
누적 이득의 수학적 기초를 엄밀하게 제시하여 문헌계량학과 사회과학 현상의 왜곡 분포들을 통일적으로 설명하는 획기적인 이론 제시. 베타 함수의 우아함과 광범위한 적용 가능성으로 인해 학문적 가치가 높으나, 실증 검증과 매개변수 추정의 구체적 방법에 대한 보완이 필요함.
An empirical analysis of open access citation advantages in library and information science
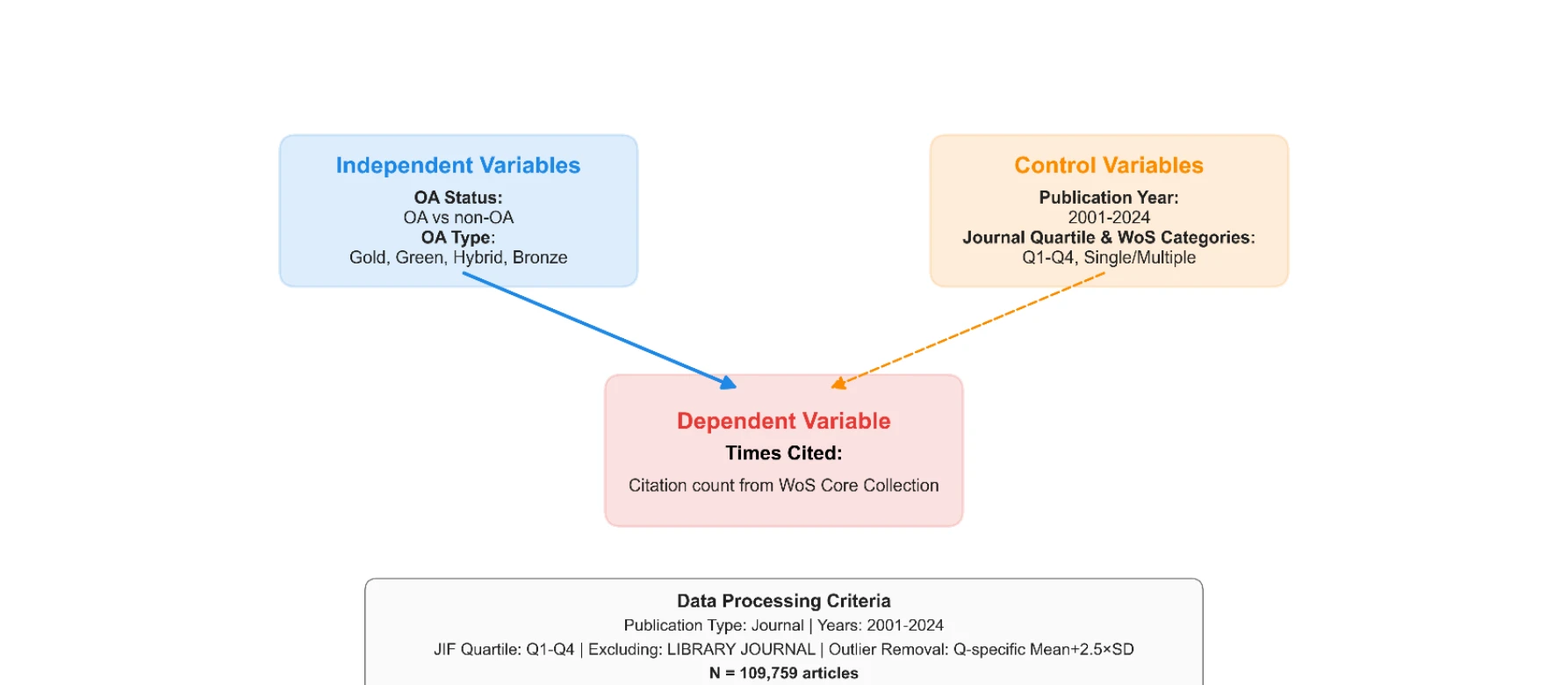
Figure 1. Research framework
 *Figure 5. OA vs non-OA Publication & Citation Comparison* 본 연구는 Web of Science 데이터베이스의 109,759개 도서관정보학(LIS) 학술논문(2001-2024)을 분석하여 오픈액세스(Open Access, OA) 논문의 인용 이점이 OA 유형, 학문분야, 출판년도에 따라 조건부로 나타남을 실증적으로 규명했다.
본 연구는 LIS 분야에서 부족했던 대규모 실증적 OA 연구로서, 의학·생명과학에서 관찰된 OA 인용 이점이 LIS에서는 시간 경과에 따라 소멸되고 OA 유형에 따라 조건부로 작동함을 처음 체계적으로 입증하여 학술커뮤니케이션 정책 수립에 중요한 실증적 근거를 제공한다.
An index to quantify an individual's scientific research output
개별 연구자의 과학적 성과를 정량화하기 위해 h-index를 제안한다. h-index는 h편 이상의 인용을 받은 논문의 수로 정의되며, 연구 영향력을 종합적으로 평가하는 단일 지표이다.
h-index는 연구자의 종합적 과학적 영향력을 측정하는 획기적인 단일 지표를 제시한다. 수학적 모형을 통한 이론적 기초 제공과 실증 데이터로의 검증을 통해 높은 실용성과 설득력을 갖추었으며, 이후 과학 평가의 표준 지표로 광범위하게 채택될 가능성이 크다.
Authorship, titles and open access as drivers of citation performance in orthopaedics: a scientometric analysis
정형외과 분야에서 저자 수, 논문 제목 특성, 개방 접근(Open Access) 여부가 인용 성과에 미치는 영향을 scientometric 분석으로 평가한 연구.
정형외과 분야의 대규모 scientometric 분석으로 협업, 개방 접근, 제목 구조가 인용 성과에 미치는 영향을 실증적으로 규명한 가치 있는 연구이며, 저자들이 윤리적 기준 유지의 중요성을 강조함으로써 단순한 메트릭 최적화를 넘는 균형잡힌 관점을 제시했다.
Citation Analysis as a Tool in Journal Evaluation
Science Citation Index(SCI) 데이터베이스를 이용하여 저널 인용 패턴을 체계적으로 분석하고, 인용 빈도와 영향력으로 저널을 평가하는 방법론을 제시한다.
본 논문은 Science Citation Index의 대규모 기계 가독 데이터를 처음으로 체계적으로 활용하여 과학 저널 평가의 새로운 방법론을 제시하였으며, 컴퓨터 기반 분석으로 기존의 수작업 한계를 극복하여 과학 정보학 분야에 매우 높은 기여도를 갖는다.
Growth Rates of Modern Science: Bibliometric Analysis Based on the Number of Publications and Cited References

Figure 1 shows the exponential growth of global scientific publication output for the
 *Figure 2 shows the segmented growth of the annual number of cited references* 본 연구는 1650년부터 2012년까지 인용 참고문헌(cited references) 데이터를 기반으로 현대 과학의 성장률을 분석하여, 과학이 세 개의 명확한 성장 단계를 거쳐 왔음을 밝혔다.
본 논문은 장기간 인용 데이터와 고급 통계 기법을 결합하여 현대 과학의 성장 패턴을 정밀하게 규명한 우수한 연구이며, 과학정책 수립과 학문 발전 이해에 중요한 기여를 한다.
Introducing multiverse analysis to bibliometrics: The case of team size effects on disruptive research

Figure 1 shows the range and the density of estimates from the multiverse of 180 equally
 *Figure 1 shows the range and the density of estimates from the multiverse of 180 equally* 본 논문은 통계적 모델 불확실성을 체계적으로 측정하는 다중우주분석(multiverse analysis)을 서지학에 처음 도입하여, 팀 규모가 혁신적 연구에 미치는 영향에 대한 기존 연구들의 상충하는 결과를 재평가한다.
본 논문은 서지학에 다중우주분석을 도입함으로써 모델 불확실성을 체계적으로 다루는 새로운 방법론을 제시하며, 상충된 선행 연구를 통합적으로 평가하여 서지학 연구의 투명성과 신뢰성을 크게 향상시킨다.
Predicting Scientific Breakthroughs Based on Structural Dynamic of Citation Cascades

 *Figure 4. The new approach proposed in this study to constructing citation cascade networks for* 인용 네트워크의 동적 구조 진화를 추적하여 과학적 돌파(breakthrough) 논문을 예측하는 새로운 방법을 제안. 시계열 인용 캐스케이드(citation cascades)를 구성하고 위상 지표, PageRank, von Neumann 그래프 엔트로피의 동적 궤적을 활용하여 정적 방법 대비 7% 성능 향상을 달성.
본 연구는 인용 네트워크의 동적 진화를 처음으로 체계적으로 모델링하여 과학적 돌파 예측 정확도를 향상시킨 의미 있는 기여를 제시한다. 다만 노벨상 데이터셋 의존성과 일반화 가능성 측면에서 추가 검증이 필요하며, 실무 적용을 위해서는 더 광범위한 도메인과 시간 규모에서의 실험이 요구된다.
Redefining Academic Performance: The Development of the NK Composite Scholarly Performance Index
본 연구는 기존 h-지수 등의 한계를 극복하기 위해 학술 경력 기간, 출판 지속성, 저자 기여도를 조정하는 NK 지수(NK Composite Scholarly Performance Index)를 제안한다.
NK 지수는 h-지수의 구조적 한계를 명확히 진단하고 경력 길이, 출판 지속성, 저자 기여도를 통합 조정하는 포괄적 성과 지표를 제안하여 학술 평가의 공정성을 크게 향상시킬 수 있는 잠재력이 있다. 다만 구체적 계산 알고리즘, 경험적 검증, 학제 간 적용성에 대한 상세 논의가 필요하다.
Polymer Science Research in India: A Scientometrics Study
2010-2020년 Web of Science 데이터베이스를 활용하여 인도의 고분자과학(Polymer Science) 연구 출판물 25,044건을 분석한 scientometrics 연구로, 중국에 이어 인도가 급속한 성장을 보이고 있음을 입증했다.
인도의 고분자과학 연구 성장을 scientometrics로 정량화한 유용한 정책 자료이나, 분석 범위의 모순, 제한된 데이터베이스 활용, 기관별 분석 부재 등으로 인해 연구의 완성도가 다소 미흡하다.
Public use and public funding of science

Fig. 1 | Diversity in public use. a–t, Different scientific fields experience
 *Fig. 1 | Diversity in public use. a–t, Different scientific fields experience* 공개 자금으로 지원된 과학 연구가 실제로 공중의 이익과 일치하는지 검증하기 위해 5개의 대규모 데이터셋을 연계하여 과학 논문의 자금 지원과 공개 영역에서의 사용을 분석했다.
공공 과학 투자의 정당성에 대한 오랜 의문을 대규모 데이터 분석으로 실증적으로 답변한 혁신적 연구로, 과학 정책 수립과 과학-사회 인터페이스 이해에 중요한 기여를 한다.
Real-World Evidence in the First Round of the US Inflation Reduction Act Drug Price Negotiations: A Citation Analysis of CMS Maximum Fair Price Explanation Documents
본 연구는 미국 인플레이션 감축법(IRA)에 따른 첫 번째 Medicare 약가 협상에서 인용된 실제 임상 근거(RWE, Real-World Evidence)를 체계적으로 분석하여, CMS의 최고공정가격(MFP) 설명문서에서 RWE 활용의 투명성과 방법론적 일관성을 평가한 최초의 정량적 연구이다.
본 연구는 새로운 Medicare 약가 협상 체계의 증거 기반을 최초로 체계적으로 평가한 중요한 정책 분석이며, RWE 활용의 광범위한 편차와 투명성 부재를 실증적으로 입증함으로써 보건경제학 실무와 정책 개선에 직접적인 함의를 제공한다.
The Rise of Large Language Models and the Direction and Impact of US Federal Research Funding
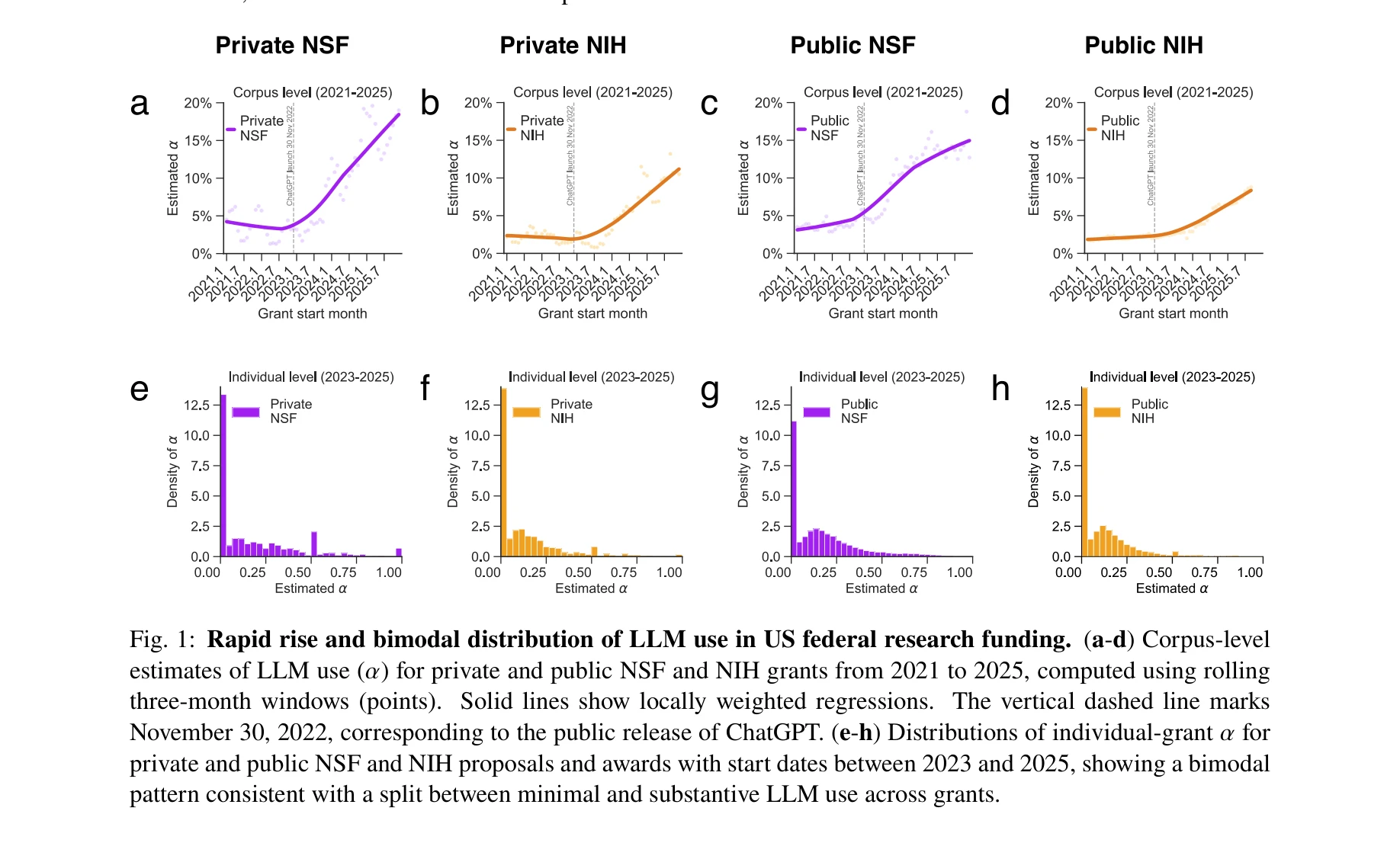
Fig. 1: Rapid rise and bimodal distribution of LLM use in US federal research funding. (a-d) Corpus-level
 *Fig. 1: Rapid rise and bimodal distribution of LLM use in US federal research funding. (a-d) Corpus-level* 대규모 언어모델(LLM)의 급속한 확산이 미국 연방 연구비 지원 구조를 어떻게 재편하고 있는지 분석한 연구로, LLM 사용이 2023년부터 급증하며 제안서의 의미적 다양성을 감소시키지만 NIH에서는 자금 획득 확률을 높이는 현상을 발견했다.
이 연구는 LLM이 과학 자금 지원 시스템에 미치는 영향을 처음으로 대규모로 문서화한 중요한 기여로, 기밀 데이터 접근을 통해 독특한 증거를 제시하며 기관별 상이한 결과는 정책 입안자들의 맥락-의존적 개입 필요성을 강조한다.
Funding the Frontier: Visualizing the Broad Impact of Science and Science Funding
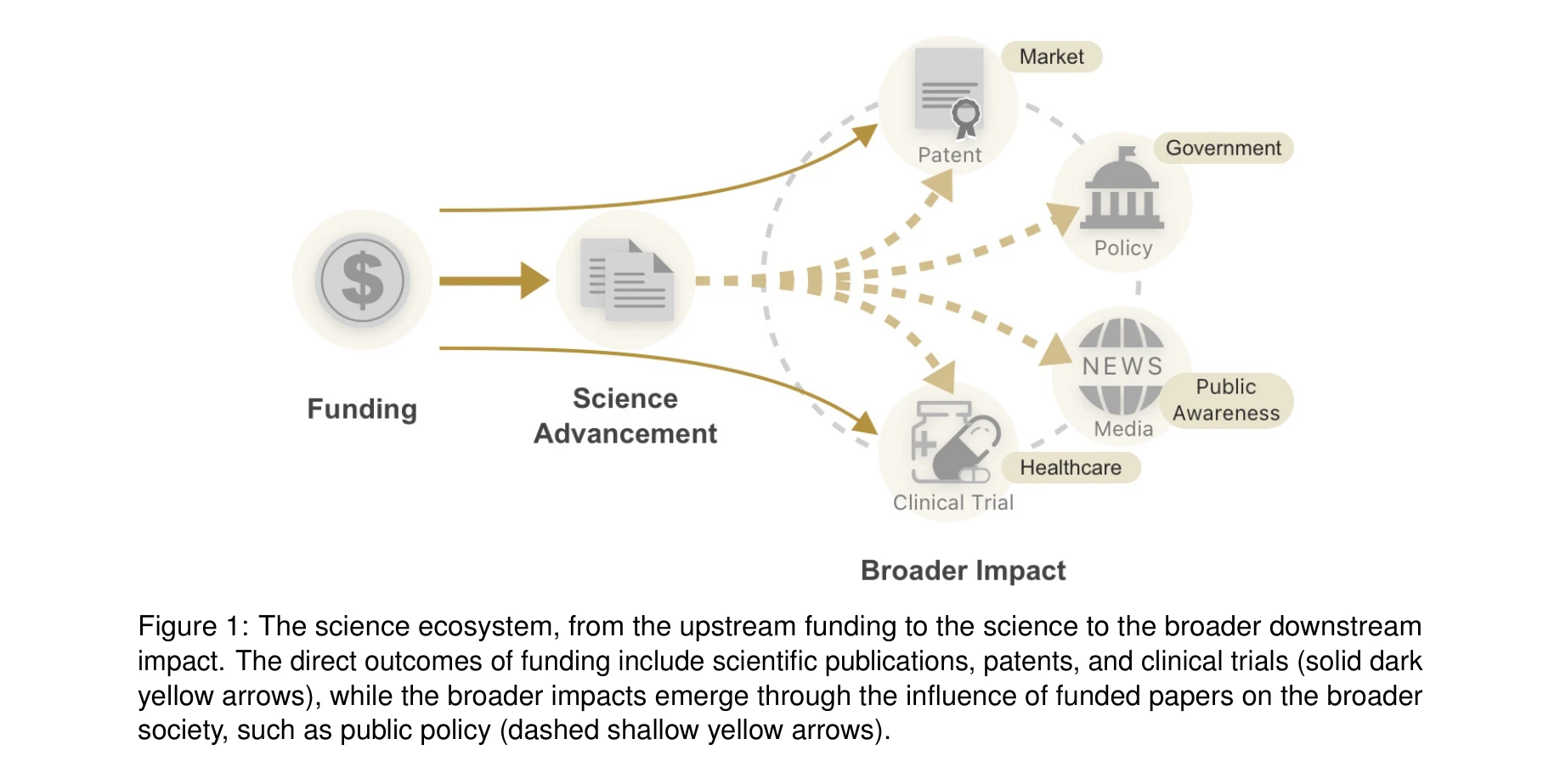
Figure 1: The science ecosystem, from the upstream funding to the science to the broader downstream
 *Figure 1: The science ecosystem, from the upstream funding to the science to the broader downstream* 과학 펀딩의 다차원적 영향을 시각적으로 분석하기 위해 700만 개 연구비, 1억 4천만 개 논문, 1억 6천만 개 특허 등을 연결한 대규모 데이터 기반 시각분석 시스템(FtF)을 개발했다.
이 논문은 Science of Science와 Visual Analytics를 결합하여 펀딩의 다차원적 사회 영향을 체계적으로 분석하는 최초의 포괄적 플랫폼을 제시했으며, 180억 규모의 이질적 네트워크 데이터 통합과 공개 웹 도구 제공을 통해 학술계뿐 아니라 정책 실무에서의 즉각적 활용 가치를 입증하는 뛰어난 연구다.
Interdisciplinary papers supported by disciplinary grants garner deep and broad scientific impact
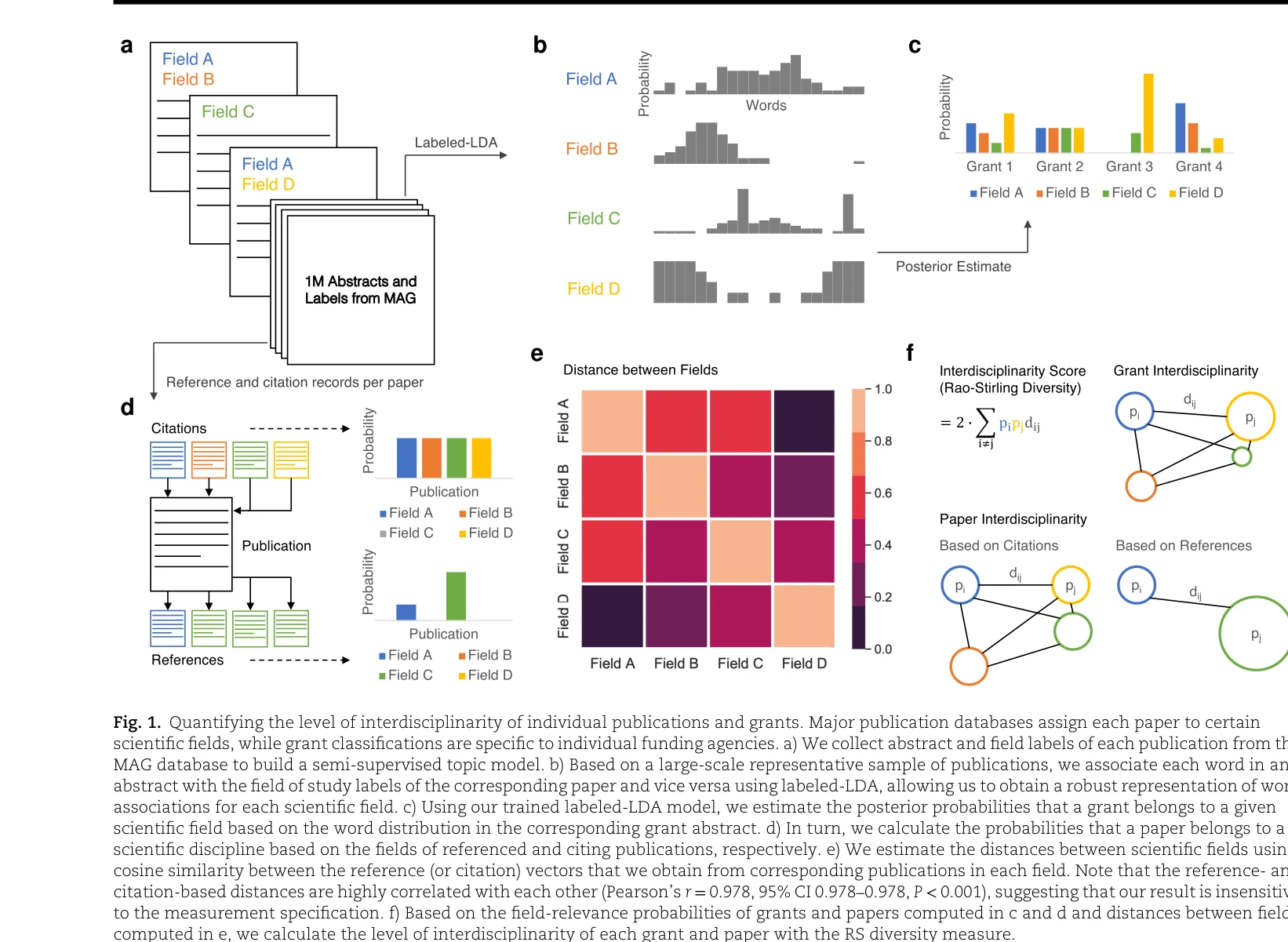
Fig. 1. Quantifying the level of interdisciplinarity of individual publications and grants. Major publication databases
 *Fig. 3. Impact of interdisciplinary papers as a function of grant interdisciplinarity. a) Interdisciplinary papers from * 350,000개 국제 연구비 데이터를 분석한 결과, 학제간(interdisciplinary) 연구비보다 학문분야 중심(disciplinary) 연구비가 높은 영향력의 학제간 논문을 생산하는 것으로 나타났다.
학제간 연구비 지원 정책의 효과를 대규모 실증 데이터로 처음 체계적으로 검증한 중요한 연구이다. 깊은 학문기초와 학제간 혁신의 상보성을 보여주며 과학정책 입안에 직접적인 함의를 제공한다.
Linking Global Science Funding to Research Publications
 *Figure 2: Overview of the funder name disambiguation pipeline.* 전 세계 과학 펀딩 조직을 연구 논문과 연결하기 위해 740만 개의 펀딩 인정 문자열을 체계적으로 명확화하고 190만 개의 고유 펀더를 표준화된 식별자로 매핑한 대규모 데이터셋을 구축했다.
본 연구는 과학 펀딩의 글로벌 투명성과 비교 가능성을 크게 향상시키는 실질적이고 포괄적인 데이터 인프라를 제공하며, 다단계 명확화 방법론과 체계적 교차 데이터베이스 검증을 통해 과학-정책 연구의 신뢰성을 높이는 중요한 기여를 한다.
Mapping Research Funding and Outputs at the Topic Level in the Nordic Countries
북유럽 국가들의 연구 자금 지원과 출판 성과 간의 관계를 주제 수준에서 분석하여, 자금이 출판량은 증가시키지만 인용 영향도(citation impact)는 오히려 감소시키는 질-량 간 트레이드오프 현상을 발견했다.
북유럽의 연구 자금과 출판 성과 간의 관계를 주제 수준에서 체계적으로 분석한 우수한 연구로, 자금이 출판량은 증가시키지만 인용 영향도는 오히려 감소시킨다는 중요한 정책적 시사점을 제시한다. 다만 지역 한정성과 인과 메커니즘에 대한 더 깊은 분석이 필요하다.
Quantifying Long-term Scientific Impact

Figure 1: Characterizing citation dynamics. (A) Yearly citation ci(t) for 200
 *Figure 1: Characterizing citation dynamics. (A) Yearly citation ci(t) for 200* 논문은 개별 논문의 인용 역학(citation dynamics)에 대한 메커니즘 모델을 도출하여, 서로 다른 저널과 학문 분야의 인용 이력을 단일 곡선으로 통합하고 과학적 영향력의 보편적 시간 패턴을 규명했다.
이 논문은 과학 인용의 무질서해 보이는 현상 속에서 보편적 동역학 법칙을 발견하여 과학 측정학(scientometrics)에 획기적 기여를 했으며, 저널 무관적 영향력 평가 방법론은 학술 평가 체계 개선에 직접적 정책적 함의를 제공한다.
Quantifying the dynamics of failure across science, startups and security

 *Figure 3: Phase diagram of the model. (a) Analytical solution of the model reveals that the* 과학, 스타트업, 보안 등 다양한 분야에서 반복된 실패 역학을 설명하는 일반화된 수학 모델을 제시하고, 성공과 실패를 구분하는 임계점(phase transition)을 발견했다.
복잡한 실패 현상을 우아한 수학 모델로 통합하고, 세 개의 거대한 실증 데이터셋으로 검증한 기념비적 논문이다. 상 전이를 통한 성공-실패 경계의 정량화는 혁신과 학습 분야에 새로운 분석 틀을 제시한다.
The Scholarly Knowledge Ecosystem: Challenges and Opportunities for the Field of Information
학술 지식 생태계의 연구 과제를 다학제적으로 분석하여 과학적 이해, 개선, 거버넌스를 위한 핵심 연구 문제와 공통된 해결 방안을 체계적으로 종합한 리뷰 논문.
학술 지식 생태계 연구를 처음으로 통합적으로 조망한 중요한 메타 리뷰로, 분산된 문헌을 체계적으로 종합하고 인간 가치 기반의 연구 방향을 제시했다는 점에서 높은 학문적 기여도를 갖는다.
The selective use of physics knowledge in policy: how interdisciplinary physics bridges subfields and shapes policy influence

 *Figure 2: Distribution of scientific supply versus policy demand. The blue bars represent the full APS corpus (scientifi* 이 연구는 물리학 지식이 정책 문서에 어떻게 선택적으로 인용되는지 분석하며, 학제간 물리학이 정책 담론 진입은 용이하게 하지만 정책 영향력으로는 이어지지 않는 현상을 규명했다.
과학-정책 인터페이스에서 지식의 선택적 활용을 체계적으로 분석한 창의적이고 중요한 연구로, 학제간 연구의 가시성과 실제 영향력의 차이를 규명함으로써 과학 정책 수립의 복잡한 메커니즘을 깊이 있게 조명했다.
Are disruptive papers more likely to impact technology and society?
CD index(논문의 상대적 파괴성)는 기술 및 사회 영향과 약한 관계를 보이지만, 새롭게 제안된 '파괴적 인용(disruptive citation)' 지표는 기술·사회 임팩트와 강한 긍정 관계를 나타낸다.
약 4천만 개 논문의 대규모 분석으로 기존 CD index의 한계를 실증하고, 절대적 파괴 임팩트 개념을 새롭게 제시하여 과학 평가 방식에 중요한 질문을 던지는 고가치 연구이다. 다만 새로운 지표의 정의가 더 명확하고 인과 관계 규명이 필요하다.
Atypical Combinations and Scientific Impact
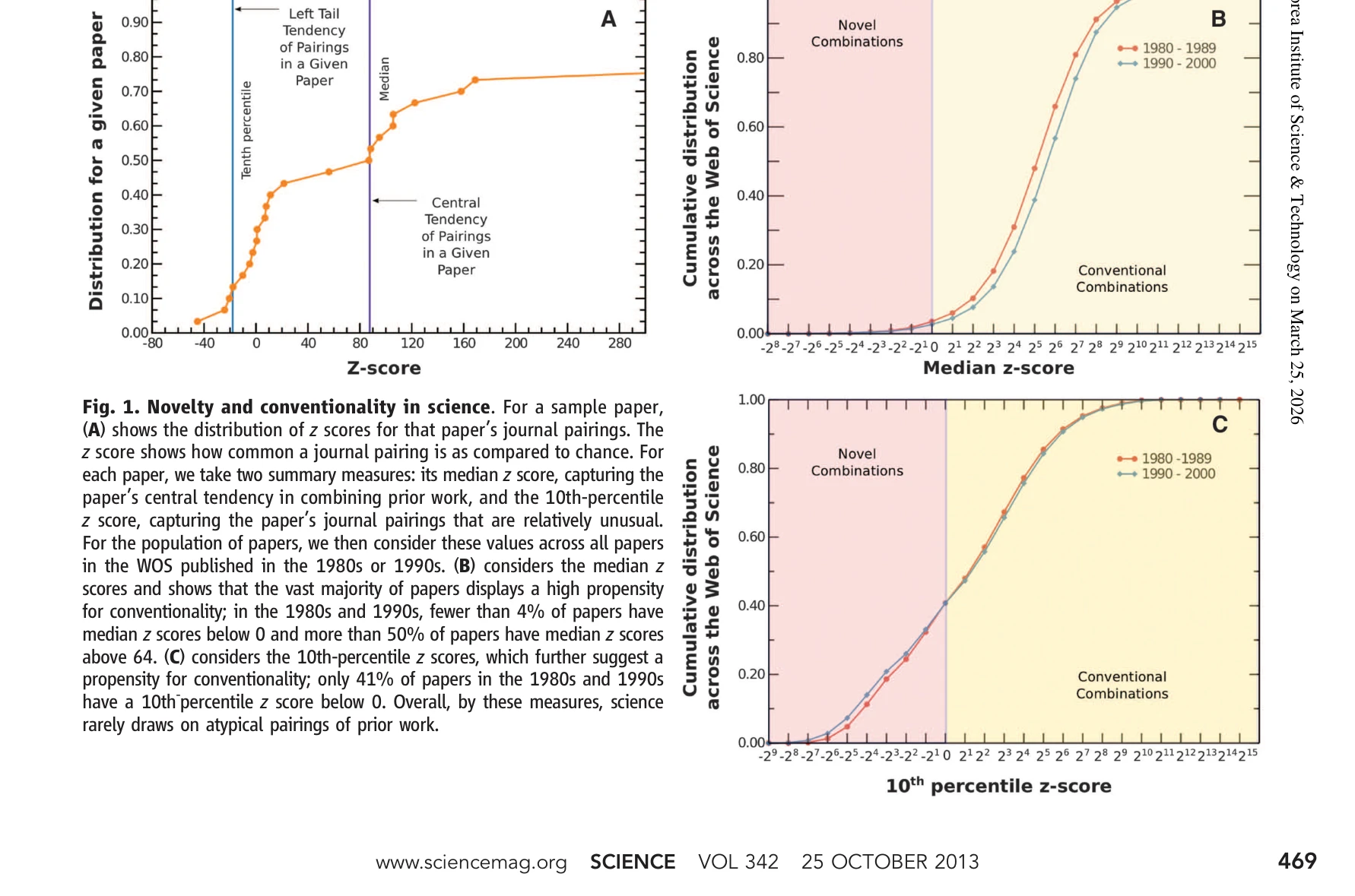
Fig. 1. Novelty and conventionality in science. For a sample paper,
 *Fig. 2. The probability of a “hit” paper, conditional on novelty and conventionality. This figure* 1,790만 편의 논문 분석을 통해 높은 영향력을 가진 과학 논문은 기존의 일반적인 지식 조합에 기초하면서도 비전형적(atypical) 조합을 포함할 때 2배 높은 인용률을 보인다는 것을 발견했다.
이 논문은 참고문헌 조합이라는 객관적 지표를 통해 과학적 혁신과 영향력의 관계를 최초로 대규모로 규명한 중요한 연구이며, 팀 과학의 우월성을 실증적으로 입증함으로써 과학 정책과 연구 전략 수립에 직접적인 시사점을 제공한다.
Do novel papers attract more social attention?
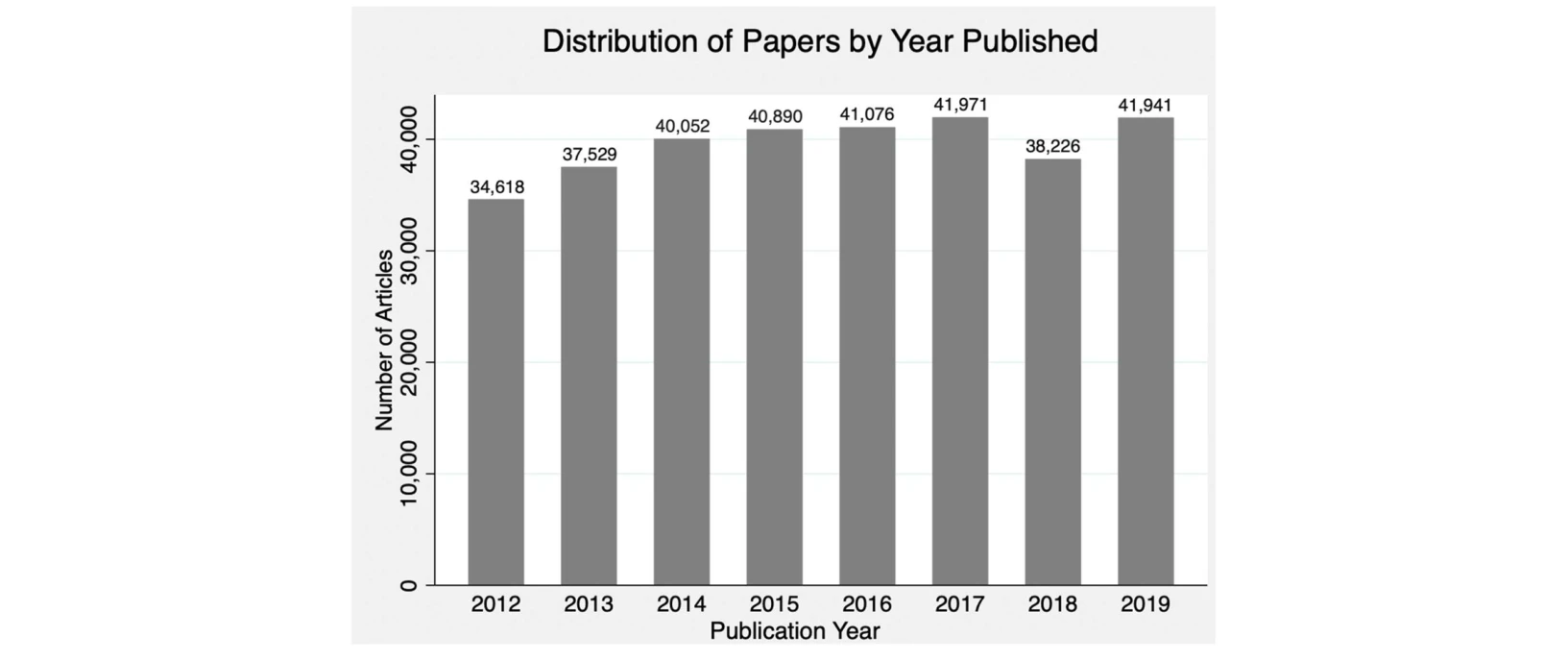
Fig. 1. Distribution of paper by year published.
 *Fig. 2. Mean of Altmetrics of papers by whether they are classified as novel paper. AAScore represents the Altmetric Att* 본 연구는 310,000개 이상의 경제학 및 경영학 논문을 분석하여 혁신적(Novel)인 연구가 소셜 미디어, 트위터, 블로그 등 Altmetrics를 통해 더 많은 사회적 관심을 받는지 실증적으로 검증했다.
본 연구는 혁신적 연구가 학술 인용도 외에도 사회적 미디어 플랫폼에서 실질적인 공중의 관심을 끌 수 있음을 대규모 실증 데이터로 처음 입증했으며, 과학의 사회적 영향 평가에 새로운 관점을 제시한 의미 있는 기여를 한다.
Papers and patents are becoming less disruptive over time

Fig. 1: Overview of the measurement approach.
 *Fig. 2: Decline of disruptive science and technology.* 지난 60년간 45백만 편의 논문과 390만 개의 특허를 분석한 결과, 과학과 기술 논문/특허들이 시간이 지남에 따라 과거와의 단절을 추구하지 않는 경향(disruptiveness 감소)을 보이고 있다. 이는 새로운 지식이 축적되었음에도 불구하고 혁신의 속도가 둔화되고 있음을 시사한다.
본 논문은 과학과 기술의 진보 패턴을 정량적으로 규명하는 획기적 연구로, 새로운 CD 지수 개발과 초대규모 데이터 분석을 통해 '디스럽션의 역설'을 설득력 있게 입증했다. 결과는 과학 정책과 혁신 전략 수립에 중요한 시사점을 제공하지만, 인과관계 규명과 메커니즘 심화 분석은 향후 연구 과제로 남아있다.
The Preeminence of Ethnic Diversity in Scientific Collaboration
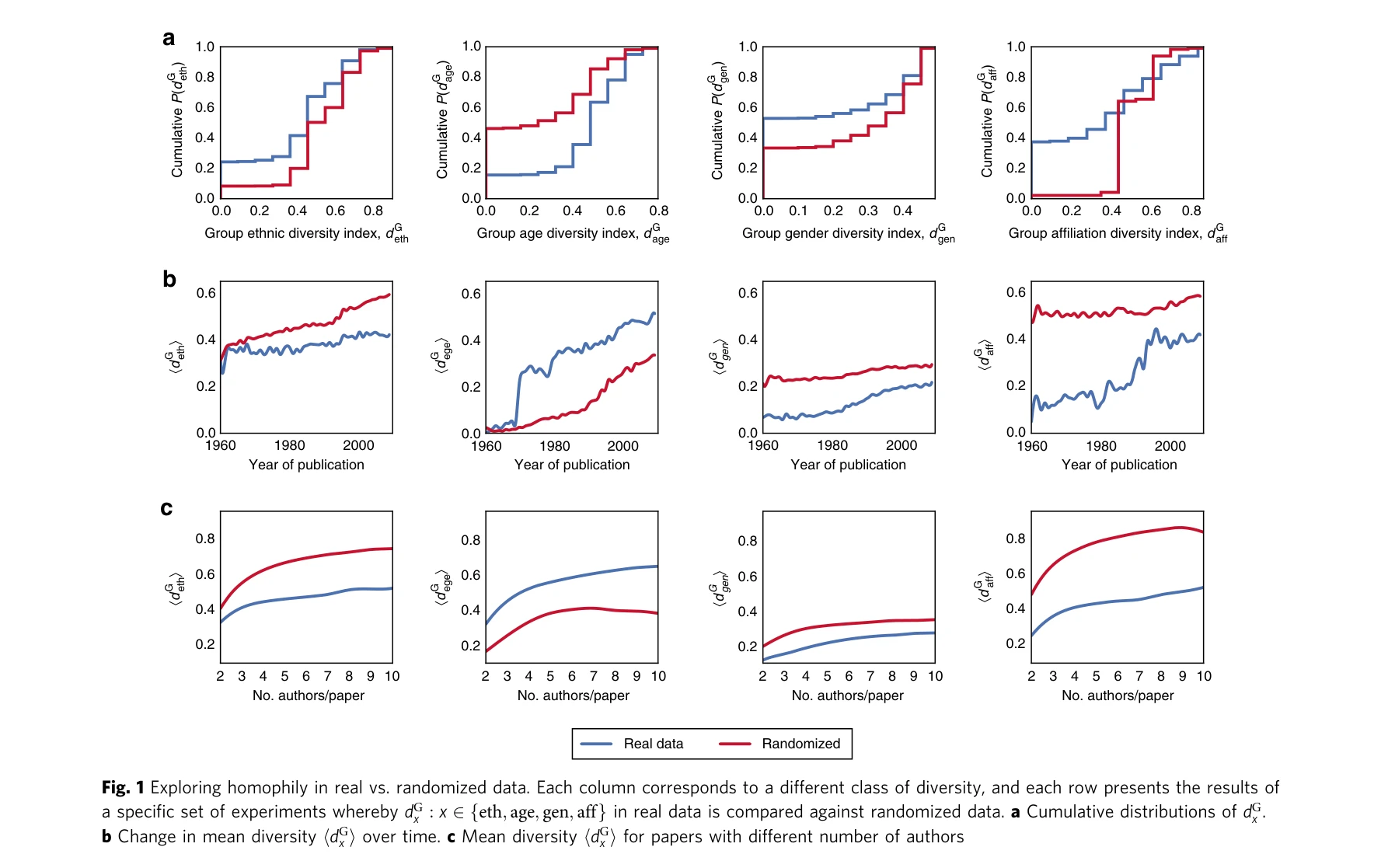
Fig. 1 Exploring homophily in real vs. randomized data. Each column corresponds to a different class of diversity, and e
 *Fig. 3 Group and individual diversity vs. impact in each subfield. In each subplot, the points correspond to subfields, th* 900만 개 논문과 600만 명의 과학자를 분석하여 인종(ethnic) 다양성이 과학적 협력의 영향력(citation impact)과 가장 강하게 상관관계를 가지며, 인종 다양성이 높은 논문은 10.63%, 과학자는 47.67%의 영향력 증가를 보임을 입증했다.
본 논문은 대규모 데이터와 엄밀한 통계방법으로 인종 다양성이 다른 형태의 다양성보다 과학적 영향력에 훨씬 강한 긍정적 상관관계를 가짐을 처음으로 체계적으로 입증했으며, 다양성 정책의 과학적 근거를 제공하는 중요한 공헌이다. 다만 명명화 인종 분류의 한계와 인과성 미보장 등 방법론적 제약이 있다.
The Price-Pareto growth model of networks with community structure
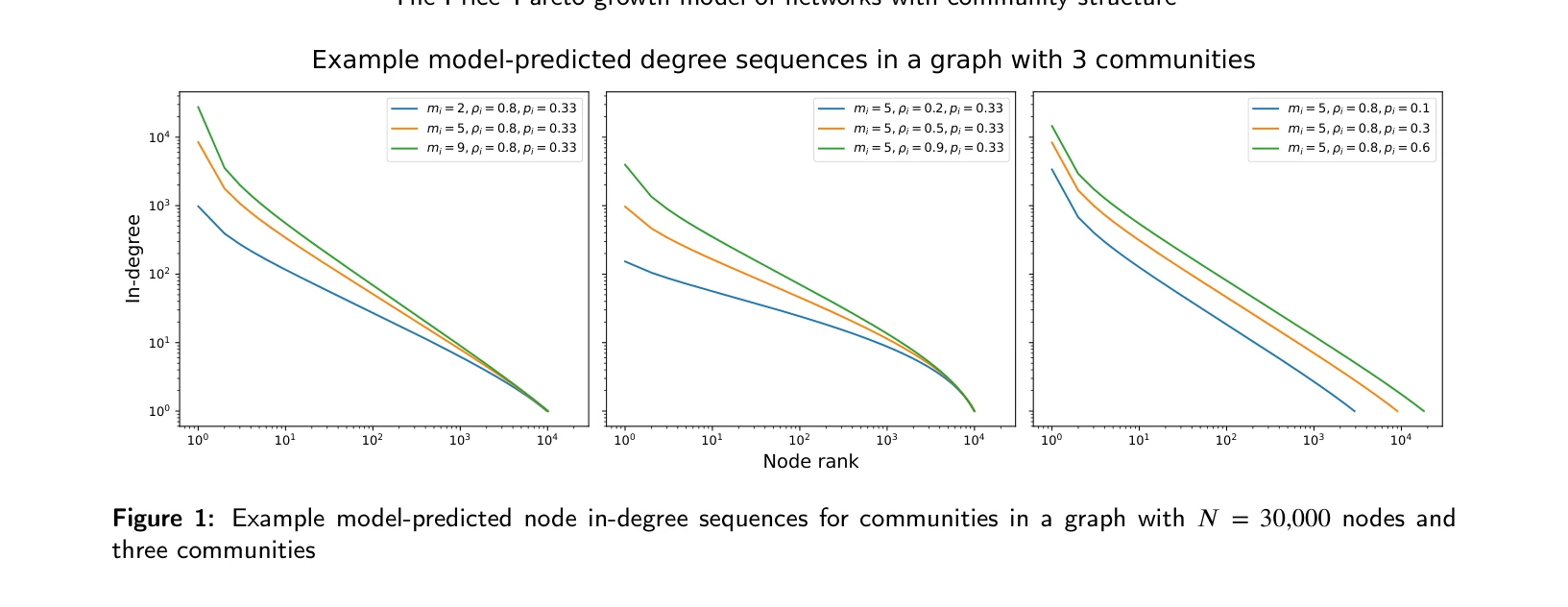
Figure 1: Example model-predicted node in-degree sequences for communities in a graph with 𝑁= 30,000 nodes and
 *Figure 1: Example model-predicted node in-degree sequences for communities in a graph with 𝑁= 30,000 nodes and* 커뮤니티 구조를 가진 네트워크의 차수 분포를 모델링하기 위해 Price 모델을 확장한 Price-Pareto 성장 모델을 제시하며, 각 커뮤니티별 이질적인 인용 역학을 분석한다.
이 논문은 커뮤니티 구조와 해석 가능성을 동시에 갖춘 최초의 분석적 인용 네트워크 성장 모델을 제시하며, 과학계량학과 복잡계 네트워크 연구에 중요한 기여를 한다. 엄격한 수학적 유도와 실제 적용성의 균형이 우수하다.
The structure of scientific collaboration networks
과학자들의 공동저작 네트워크 구조를 분석하여 MEDLINE, Los Alamos Archive, SPIRES, NCSTRL 데이터베이스로부터 100만 명 이상의 과학자들이 형성하는 '소규모 세계(small world)' 특성을 입증했다.
과학 협력 네트워크를 대규모 실제 데이터로 처음 체계적으로 분석한 선구적 연구로, 소규모 세계 가설을 실증하고 분야별 협력 패턴의 차이를 규명했다. 사회 네트워크 연구의 중요한 이정표가 되는 논문이다.
Atlas of Science Collaboration, 1971–2020
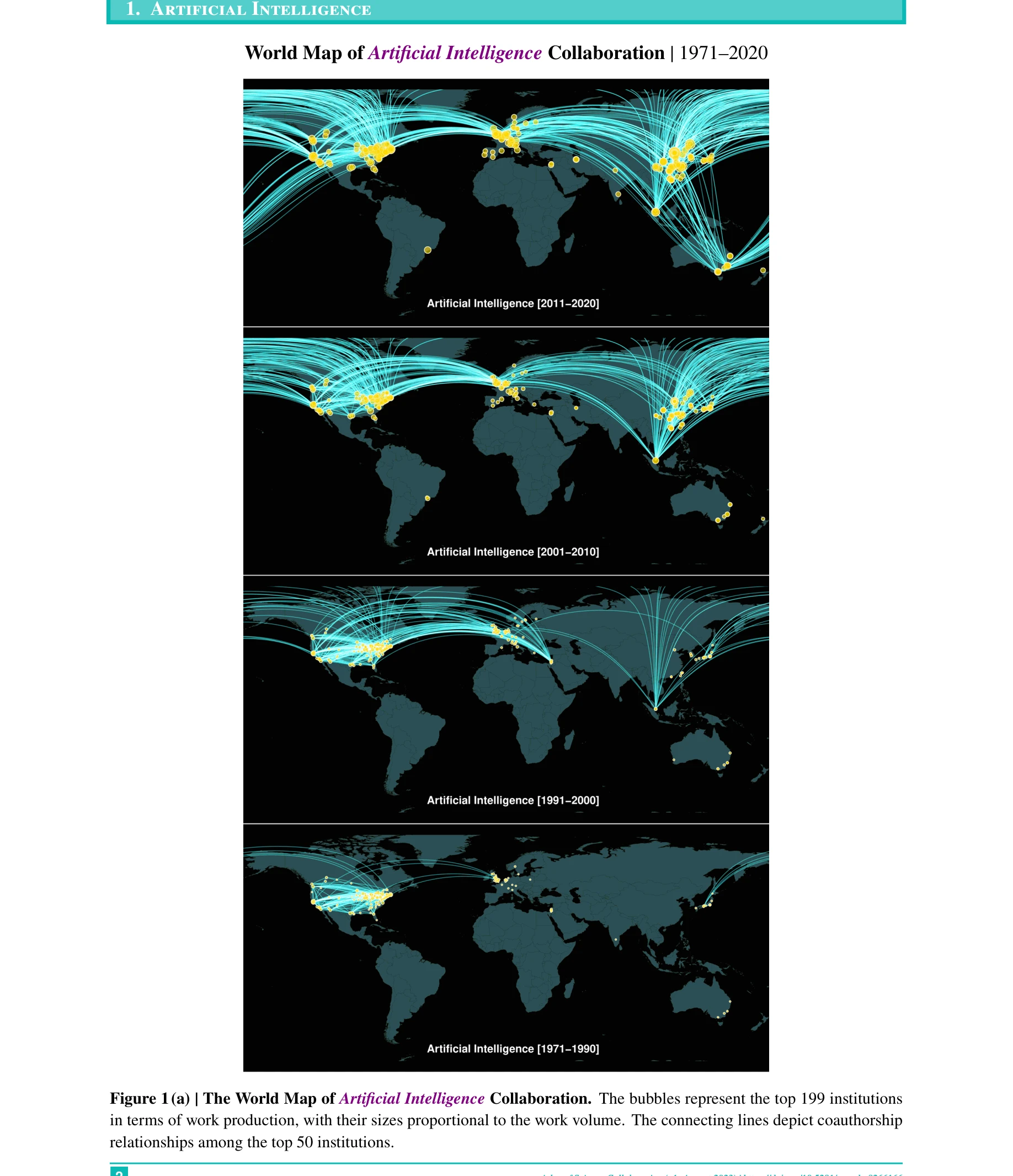
Figure 1(a) | The World Map of Artificial Intelligence Collaboration. The bubbles represent the top 199 institutions
 *Figure 1(a) | The World Map of Artificial Intelligence Collaboration. The bubbles represent the top 199 institutions* 1971년부터 2020년까지 50년간 OpenAlex 데이터를 활용하여 15개 자연과학 분야의 국제 및 기관 간 연구 협력 현황과 진화를 시각화한 종합 지도책(Atlas)이다.
OpenAlex의 오픈 데이터를 활용하여 50년간 15개 과학 분야의 국제 협력 현황을 종합적으로 시각화한 선도적 자료로, 정책 입안자 및 연구 관리자에게 직관적이고 실용적인 인사이트를 제공한다. 다만 데이터 완전성과 공저자 관계의 한계를 인식하고 활용하면 과학 외교 및 R&D 정책 수립의 중요한 참고 자료가 될 수 있다.
Impacts of inter-institutional mobility on scientific performance from research capital and social capital perspectives
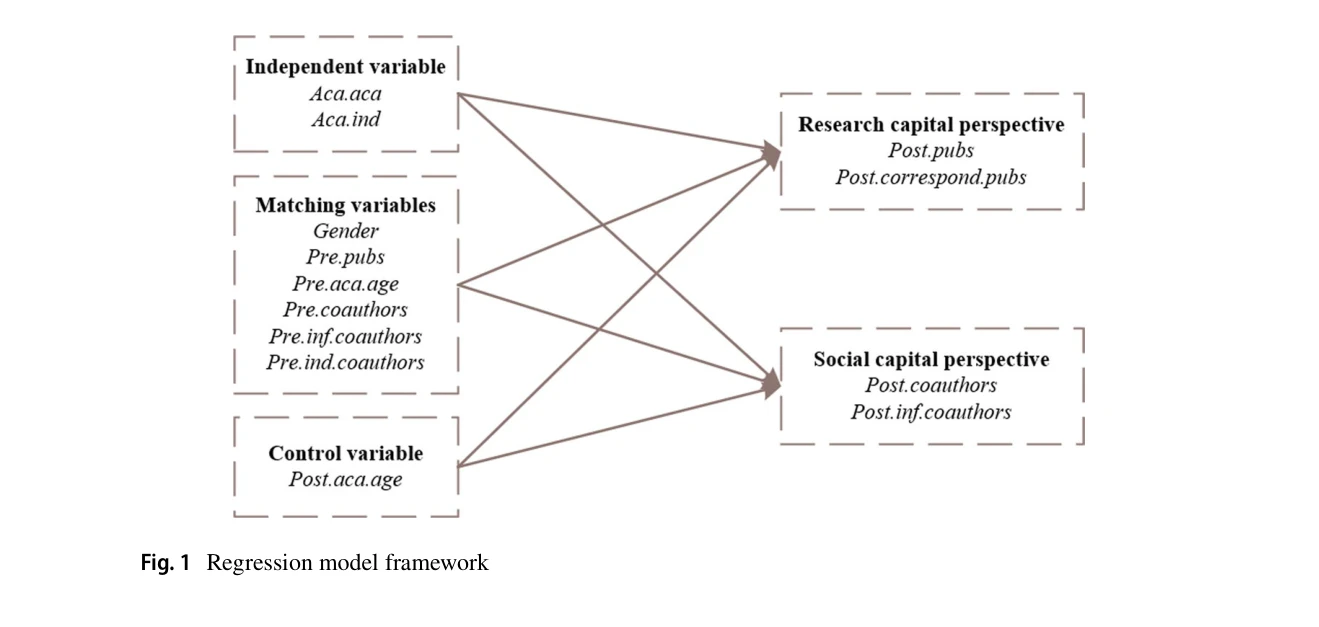
Fig. 1 Regression model framework
 *Fig. 1 Regression model framework* 본 논문은 인공지능(AI) 분야에서 연구자의 학술기관-산업체 이동(aca.ind mobility)이 연구자의 과학적 성과에 미치는 영향을 연구자본과 사회자본 관점에서 분석한다. PSM(propensity score matching) 방법을 활용하여 인과관계를 규명하고 학술기관 간 이동(aca.aca mobility)과의 비교를 통해 정책적 시사점을 제시한다.
본 논문은 PSM을 활용한 인과추론으로 학산 이동의 실제 효과를 정량화하고, 연구자본 vs 사회자본의 차등적 축적을 실증함으로써 기존 문헌의 중요한 갭을 채웠다. AI 분야의 시의적절한 선택과 명확한 분석 설계는 강점이나, 단일 분야 분석과 성과 측정의 협소함은 개선이 필요하다.
Large teams develop and small teams disrupt science and technology
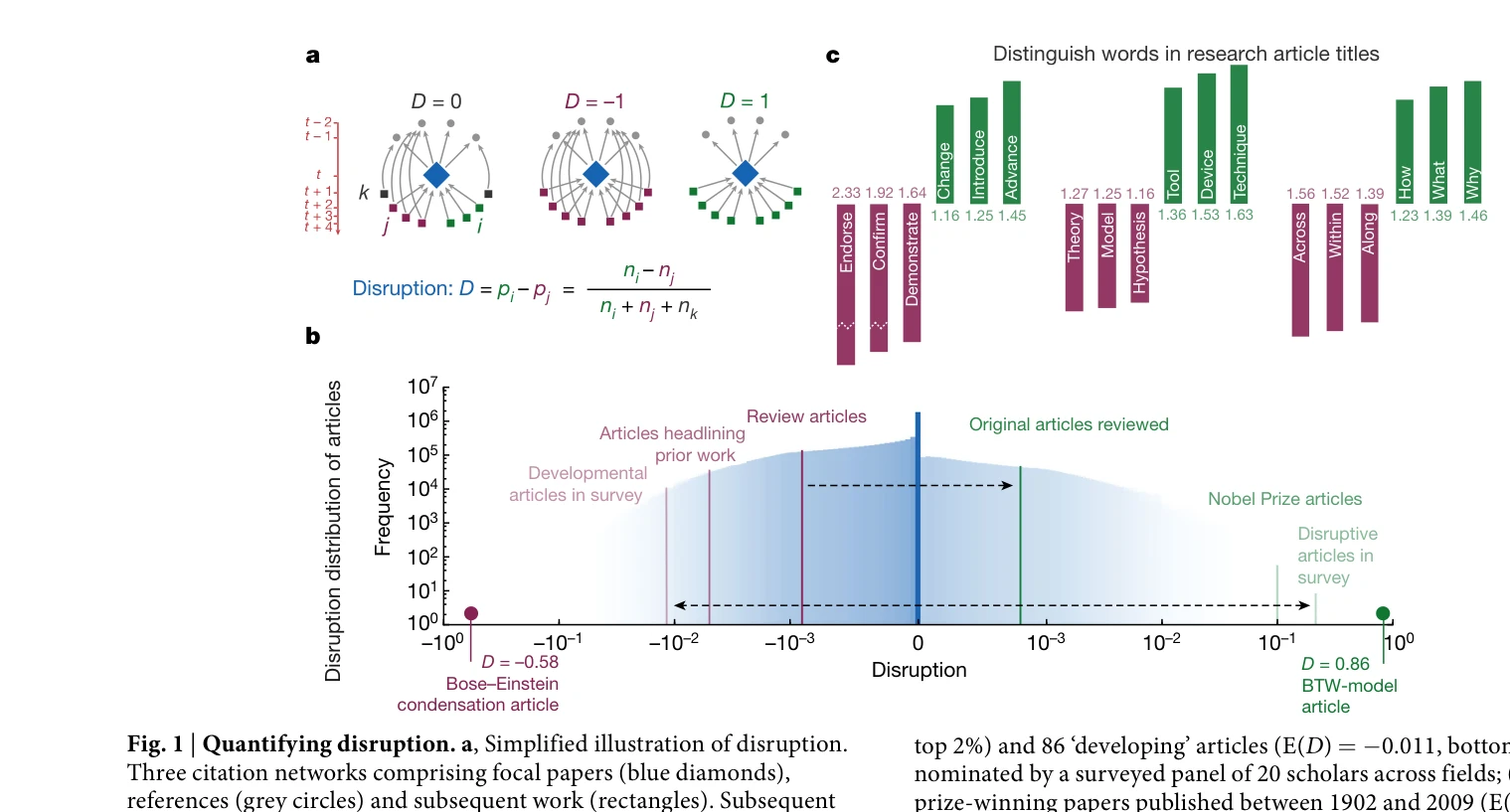
Fig. 1 | Quantifying disruption. a, Simplified illustration of disruption.
 *Fig. 2 | Small teams disrupt whereas large teams develop. a–c, For* 65백만 개의 논문, 특허, 소프트웨어를 분석하여 소규모 팀은 파괴적(disruptive) 혁신을, 대규모 팀은 점진적(developmental) 개선을 주도한다는 것을 실증했다.
팀 과학 시대에 소규모 팀의 역할을 정량적으로 재평가한 획기적 연구로, 대규모 데이터와 혁신적 측정 방법론으로 과학정책의 다양성 추구 필요성을 강력하게 입증했다.
Mapping scientific communities at scale

Figure 1: Visualization of a network with VOSviewer.
 *Figure 1: Visualization of a network with VOSviewer.* 대규모 bibliometric 데이터셋에서 과학 공동체를 효율적으로 매핑하기 위해 노드 필터링 대신 링크 필터링(strongest interactions)을 우선하는 새로운 방법론을 제시한다. Elasticsearch, Graphology, VOSviewer 등을 통합하여 scalable network analysis framework를 구축했다.
대규모 bibliometric 데이터에서 network analysis의 확장성 문제를 실용적으로 해결한 우수한 엔지니어링 작업이다. 링크 중심 필터링과 Elasticsearch 사전 계산이라는 간단하지만 효과적인 기법으로 백만 단위 출판물을 실시간 처리할 수 있게 했으며, 오픈소스 공개와 다층 기관 지원으로 실제 정책 결정에 즉시 활용 가능하다는 점에서 높은 가치가 있다.
Unequal effects of the COVID-19 pandemic on scientists
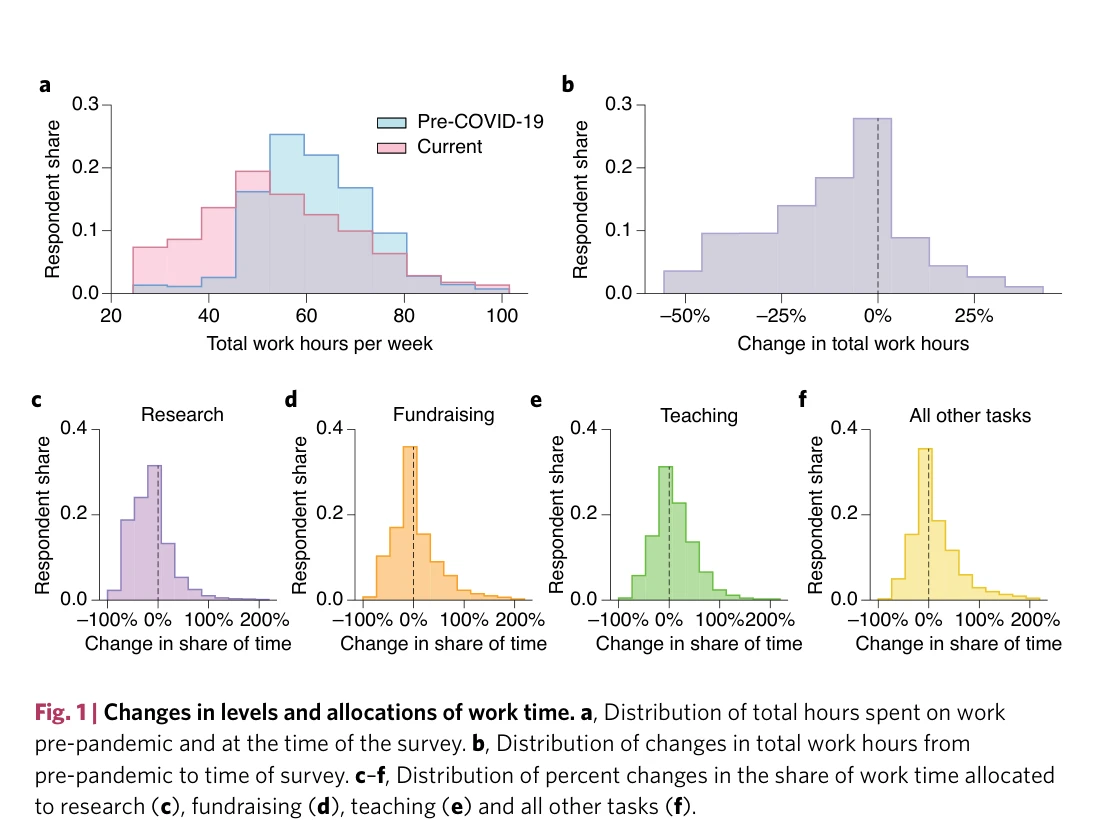
Fig. 1 | Changes in levels and allocations of work time. a, Distribution of total hours spent on work
 *Fig. 2 | Field and group-level changes in research time. a, Field-level average changes in research time. b, Group-level* COVID-19 팬데믹이 과학자들의 연구 시간에 불평등한 영향을 미쳤으며, 특히 여성 과학자, 벤치 사이언스 분야, 어린 자녀를 둔 과학자들이 심각한 영향을 경험했다.
이 연구는 팬데믹이 과학자 집단에 미친 불평등한 영향을 처음으로 정량적으로 밝힌 중요한 증거 기반 연구로, 특히 보육 책임이 여성 과학자의 경력에 미치는 구체적 영향을 조명했다. 응답률 저하와 표본 제한이라는 한계가 있지만, 제도적 개선과 향후 추적 연구를 위한 귀중한 기초 데이터를 제공한다.
Bibliometrics: Global Gender Disparities in Science
본 논문은 세계적 규모의 서지계량학(Bibliometrics) 분석을 통해 과학 연구 분야에서 지속되는 성별 불균형을 실증적으로 입증한다.
본 논문은 과학계의 성별 격차를 서지계량학적으로 실증한 획기적 연구로서, 정책 입안자와 학계 지도자들에게 구체적인 증거를 제공하여 성평등 문화 조성에 기여한다. 다만 분석 대상이 Nature에 한정되어 있어 일반화 가능성의 제고가 필요하다.
Gender-diverse teams produce more novel and higher-impact scientific ideas

Fig. 1A plots the upward trend of women’s participation in medical science from 2000
 *Fig. 1A plots the upward trend of women’s participation in medical science from 2000* 660만 편의 의료과학 논문을 분석하여 성별 다양성 팀(mixed-gender teams)이 단일 성별 팀보다 더 참신하고 영향력 있는 연구 결과를 생산함을 입증했다. 성별 균형이 높을수록 논문의 참신성(novelty)과 영향력(impact)이 증가하는 경향을 발견했다.
대규모 의료과학 논문 데이터를 분석하여 성별 다양성 팀이 참신하고 영향력 있는 연구를 생산함을 엄밀하게 입증한 우수한 논문이다. 결과의 일관성, 통제변수의 충실성, 정책적 함의의 중요성이 높으나, 관찰 데이터의 한계와 메커니즘 미해명 부분이 개선 대상이다.
Global citation inequality is on the rise
2000년부터 2015년까지 15년간 426만 명의 저자와 2,600만 편의 논문을 분석한 결과, 상위 1% 인용 엘리트 과학자들의 인용 점유율이 14%에서 21%로 증가하며 글로벌 인용 불평등이 심화되고 있음을 보여준다.
이 연구는 대규모 저자 동일성 확인 데이터를 활용하여 글로벌 과학 시스템의 인용 불평등이 심화되고 있음을 처음 정량적으로 입증한 중요한 논문이다. 다만 인용을 성공의 단일 지표로 보는 한계와 인과관계의 불명확성, 제도적 메커니즘에 대한 분석 부족이 있어 후속 질적·정책 연구가 필요하다.
Intersectional inequalities in science
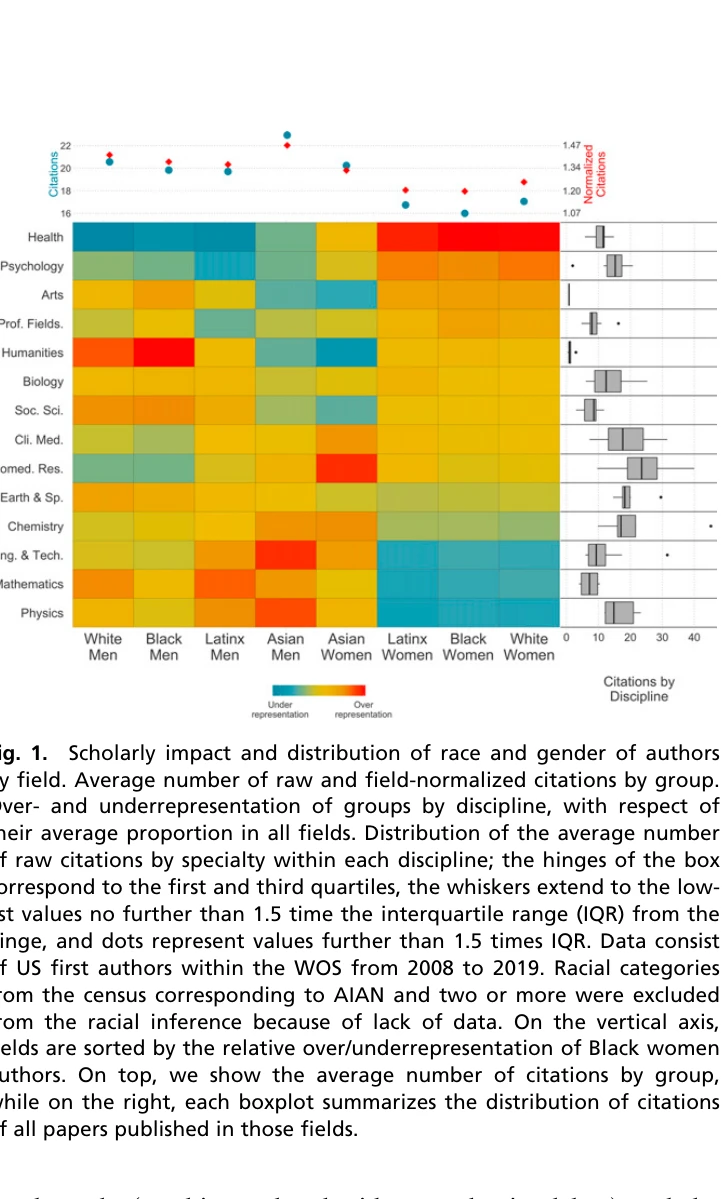
본 연구는 교차성(intersectionality) 관점에서 미국 과학인력의 인종과 성별 다양성이 연구주제 선택과 과학적 영향력에 미치는 영향을 대규모 문헌계량학(bibliometrics) 분석으로 규명했다.
본 논문은 교차성 분석을 대규모 문헌계량학 데이터에 적용하여 과학 다양성과 혁신의 관계를 새로운 방식으로 규명한 중요한 연구이다. 다만 이름 기반 인종 분류의 오류와 인과메커니즘 규명의 한계가 있으나, 과학 정책 수립에 실질적 함의를 제공한다.
Category Overview
# Scientific Collaboration & Networks 개요 본 카테고리는 과학 분야의 협력 네트워크(collaboration network)와 학술 커뮤니티 구조를 분석하는 16개 논문을 다룬다. 무작위 네트워크의 스케일링 현상부터 대규모 과학 협력 지도 작성에 이르기까지, 과학자 간 상호작용과 지식 생산의 네트워크 역학을 종합적으로 탐구한다[957][935]. 커뮤니티 탐지(community detection) 기법과 그래프 이론을 적용하여 과학 협력 구조를 규명하고[948][961], 대규모 데이터 기반의 학술 분석 인프라 구축을 시도한다[1023][985]. 또한 젠더 불균형[1027], 국가 간 협력 변화[1029], 학술 경력 궤적[1028] 등 과학 협력의 사회적·정책적 차원을 조명한다. 대규모언어모델(large language models)의 도입과 인간-AI 협력(human-AI collaboration) 패러다임, 그리고 학술출판 생태계의 변화[1021][1022][1024][994]를 함께 살펴봄으로써, 현대 과학 협력의 미래 방향성을 제시한다.
⚠ 갭: 효과적인 과학 협력을 위한 최적 팀 구성과 협업 환경에 대한 실증 연구가 부족하다
🏛 정책: 하이브리드 협업 모델 개발과 국제공동연구 활성화를 위한 제도적 지원이 필요하다
Emergence of Scaling in Random Networks
실제 네트워크들이 공통적으로 보이는 멱법칙 분포(scale-free power-law distribution)는 네트워크 성장과 선호적 부착(preferential attachment)이라는 두 가지 메커니즘으로부터 자연스럽게 나타난다.
이 논문은 스케일-프리 네트워크(scale-free network) 개념을 처음 정식화하고, 성장과 선호적 부착이라는 단순한 메커니즘으로 복잡한 실제 네트워크의 멱법칙 분포를 설명함으로써 네트워크 과학 분야의 기초를 확립한 획기적 작업이다.
Scientific prize network predicts who pushes the boundaries of science

Fig. 1A shows the sharp annual increase in the number of prizes relative to the growth of
 *Fig. 2 The exponential distribution of scientific prizewinning. Plot and inset show* 3,000개 이상의 과학상과 10,455명의 수상자 데이터를 분석하여 과학상 네트워크가 과학의 경계를 넓히는 과학자들을 예측할 수 있음을 보여준다.
과학상 네트워크 분석을 통해 과학의 엘리트 집중화, 학제적 연결, 계층적 구조를 최초로 정량화하고 미래의 영향력 있는 과학자를 예측하는 프레임워크를 제시한 중요한 연구이다. 대규모 데이터와 혁신적 분석 방법론으로 과학 사회학 분야에 유의미한 기여를 한다.
Scientific production in the era of large language models

Fig. 1 shows that LLM adoption is associated with a large increase in researchers’ scientific output
 *Fig. 1 shows that LLM adoption is associated with a large increase in researchers’ scientific output* 대규모 언어모델(LLM)이 과학 논문 작성에 광범위하게 도입되면서 연구 생산성은 증가했지만, 글의 복잡성과 논문 품질 간의 관계가 역전되어 언어적으로는 정교하지만 실질적으로는 부실한 원고들이 증가하고 있다.
본 연구는 LLM의 과학 생산에 대한 거시적 영향을 최초로 체계적이고 대규모로 실증한 획기적 연구로, 단순 생산성 증가 너머로 과학 품질 평가 기준의 근본적 변화를 요구하는 중요한 발견을 제시한다.
SciSciGPT: advancing human–AI collaboration in the science of science
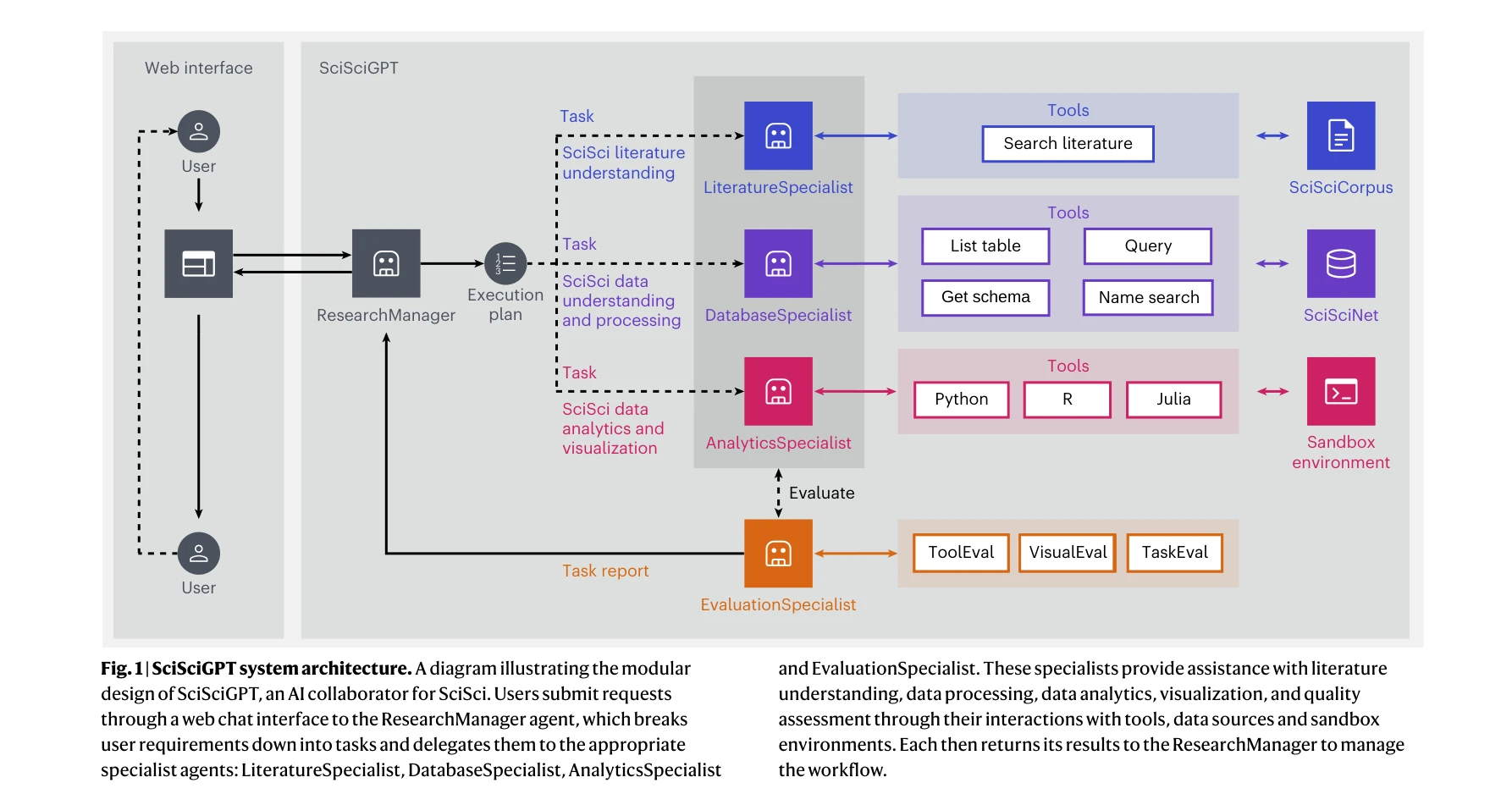
Fig. 1 | SciSciGPT system architecture. A diagram illustrating the modular
 *Fig. 1 | SciSciGPT system architecture. A diagram illustrating the modular* SciSciGPT는 대규모 언어모델(LLM)을 기반으로 한 오픈소스 AI 협력자로, 과학 메타과학(science of science) 분야의 복잡한 연구 워크플로우를 자동화하고 재현성을 향상시킨다.
SciSciGPT는 LLM 에이전트 기반 AI 협력자의 실질적 가능성을 메타과학 도메인에서 입증한 중요한 프로토타입이며, 제안된 성숙도 모델은 향후 AI 연구 도구 개발을 위한 일반화된 프레임워크를 제공한다. 투명성 및 윤리 문제 해결과 함께 다양한 과학 분야로의 확장이 이루어진다면 과학 연구의 패러다임 전환을 가능하게 할 것으로 기대된다.
SciSciNet: A large-scale open data lake for the science of science research

Fig. 1 The entity relationship diagram of SciSciNet. SciSciNet includes “SciSciNet_Papers” as the main data
 *Fig. 1 The entity relationship diagram of SciSciNet. SciSciNet includes “SciSciNet_Papers” as the main data* 134M개 이상의 과학 논문과 펀딩, 특허, 임상시험 등 외부 연계 데이터를 통합한 대규모 오픈 데이터 레이크(SciSciNet)를 제시하여, 과학 연구의 장벽을 낮추고 재현성을 향상시킨다.
SciSciNet은 과학 연구에 대한 패러다임적 자원으로, 134M개 논문과 다층 연계 데이터를 통합하여 과학 메타 연구의 진입 장벽을 획기적으로 낮춘다. 투명한 문서화와 표준화된 지표 제공으로 재현성을 강화하며, 개방형 구조로 커뮤니티의 지속적 확장을 가능하게 한다.
Software survey: VOSviewer, a computer program for bibliometric mapping
 *Fig. 3 Screenshot of the main window of VOSviewer* VOSviewer는 bibliometric mapping을 위한 자유 소프트웨어로, 특히 대규모 bibliometric map의 시각화(visualization)에 중점을 두고 개발되었으며 VOS mapping technique을 기반으로 한다.
VOSviewer는 bibliometric mapping의 시각화라는 소외된 영역에 집중하여 대규모 map의 해석성을 획기적으로 개선한 실질적으로 유용한 도구이며, 자유 소프트웨어로 제공되어 연구 커뮤니티에 큰 기여를 하고 있다.
Systemic Gendered Citation Imbalance in Computer Science: Evidence from Conferences and Journals
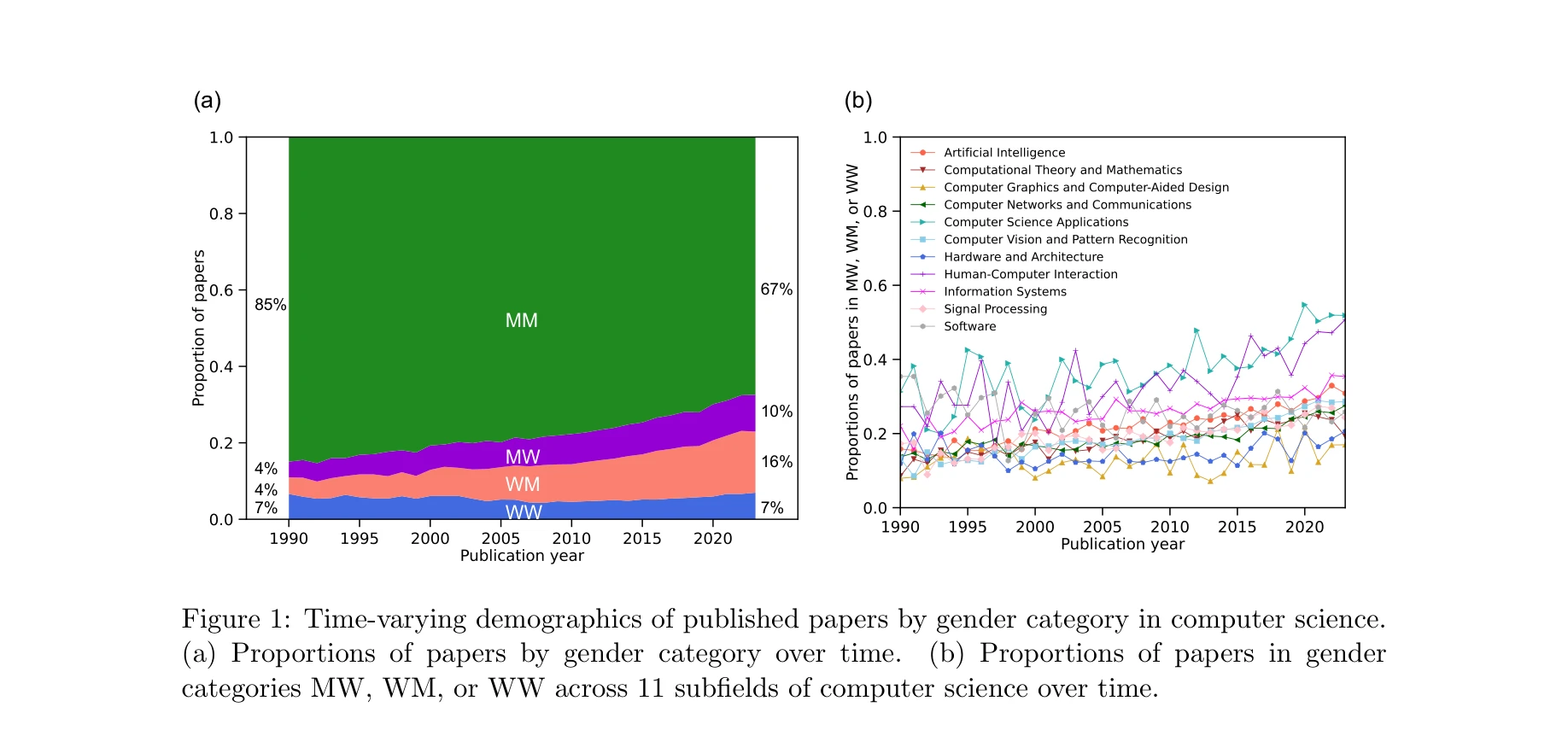
Figure 1: Time-varying demographics of published papers by gender category in computer science.
 *Figure 2: Gender imbalance in citations made by papers in computer science. Panels (a), (d),* 컴퓨터과학 분야에서 여성 저자 논문이 예상보다 적은 인용을 받는 성별 기반 인용 불균형을 실증적으로 규명하고, 이러한 현상이 회의 논문에서 저널 논문보다 더 심각함을 보여준다.
컴퓨터과학에서의 성별 기반 인용 불균형을 최초로 체계적으로 규명하고 회의-저널 간 차이를 밝혀낸 중요한 연구로, 학문의 형평성 증진을 위한 실질적 근거를 제공한다. 다만 이진 성별 분류와 자동 할당의 한계를 보완하고 인과관계를 더욱 엄밀히 규명하는 후속 연구가 필요하다.
Tenure and research trajectories
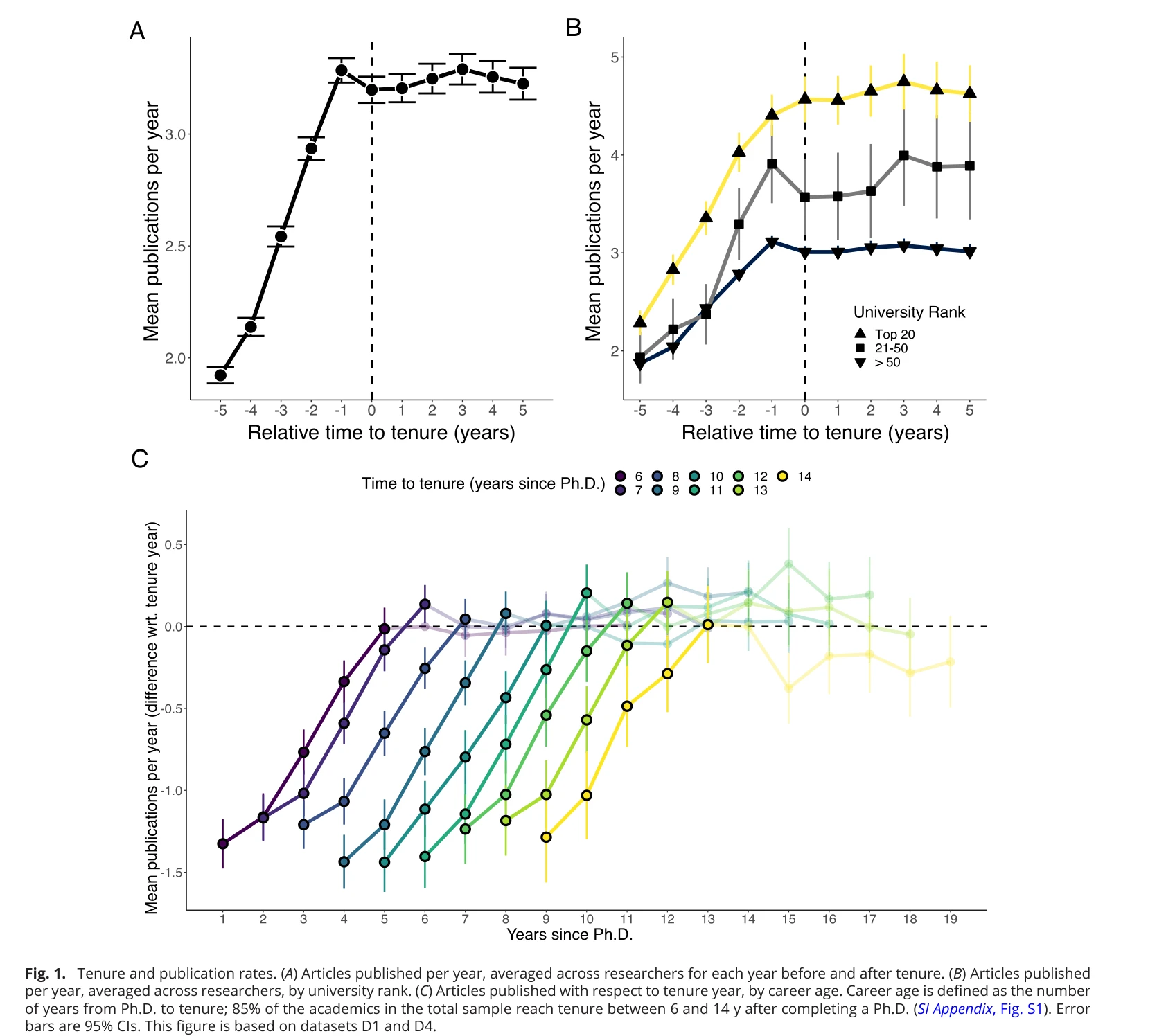
Fig. 1. Tenure and publication rates. (A) Articles published per year, averaged across researchers for each year befor
 *Fig. 1. Tenure and publication rates. (A) Articles published per year, averaged across researchers for each year befor* 12,611명의 미국 학자를 7개 데이터소스에서 추적하여, 종신재직권(tenure) 획득 전후 연구 생산성과 창의성의 변화를 대규모로 실증 분석한 연구이다. 종신재직권 획득 직전에 논문 발표가 최고조에 달하고, 획득 후 분야별로 상이한 궤적을 보이며, 창의성은 증가하나 영향력은 감소하는 현상을 발견했다.
이 논문은 미국 종신재직권 제도가 연구 생산성과 창의성에 미치는 영향을 대규모 실증 데이터로 처음 체계적으로 규명한 고도의 학술적 기여이며, 분야별 이질성 발견과 방법론의 엄밀성(인과성 규명, 경력 나이 통제)이 뛰어나 Science of Science, 학계 정책 입안, 학자 경력 이해에 중대한 함의를 제공한다.
The altering landscape of US–China science collaboration: from convergence to divergence
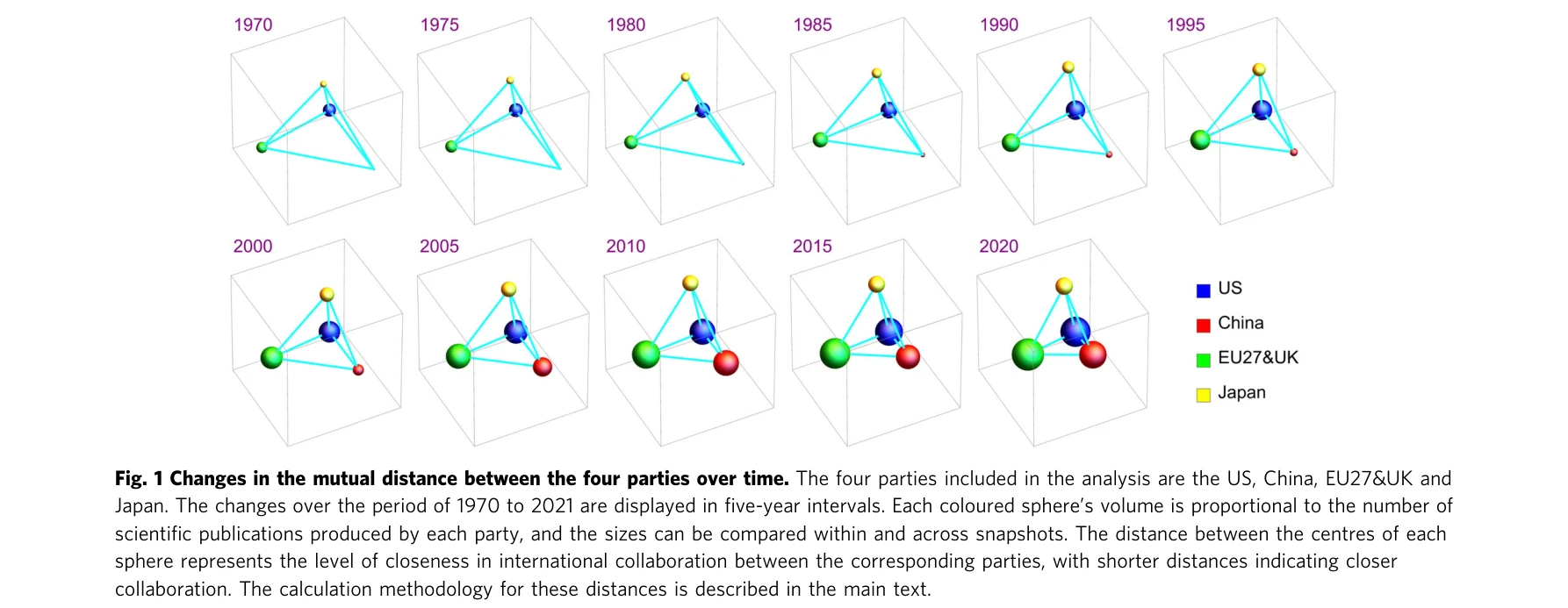
Fig. 1 Changes in the mutual distance between the four parties over time. The four parties included in the analysis are
 *Fig. 1 Changes in the mutual distance between the four parties over time. The four parties included in the analysis are * 미국과 중국의 과학 협력이 2000년대 이후 급속한 수렴에서 최근 발산으로 전환되는 역동적 패턴을 보이며, 이는 글로벌 과학 협력의 일반적 수렴 추세와 대조된다.
본 논문은 미국-중국 과학 협력의 역동적 변화를 대규모 데이터로 처음 입증한 중요한 연구로, 글로벌 과학 정책과 외교에 실질적 근거를 제공한다. 다만 인과관계 규명과 최신 데이터 포함을 위한 후속 연구가 필요하다.
The Preeminence of Ethnic Diversity in Scientific Collaboration
Fig. 1 Exploring homophily in real vs. randomized data. Each column corresponds to a different class of diversity, and e
 *Fig. 3 Group and individual diversity vs. impact in each subfield. In each subplot, the points correspond to subfields, th* 900만 개 논문과 600만 명의 과학자를 분석하여 인종(ethnic) 다양성이 과학적 협력의 영향력(citation impact)과 가장 강하게 상관관계를 가지며, 인종 다양성이 높은 논문은 10.63%, 과학자는 47.67%의 영향력 증가를 보임을 입증했다.
본 논문은 대규모 데이터와 엄밀한 통계방법으로 인종 다양성이 다른 형태의 다양성보다 과학적 영향력에 훨씬 강한 긍정적 상관관계를 가짐을 처음으로 체계적으로 입증했으며, 다양성 정책의 과학적 근거를 제공하는 중요한 공헌이다. 다만 명명화 인종 분류의 한계와 인과성 미보장 등 방법론적 제약이 있다.
Atlas of Science Collaboration, 1971–2020
Figure 1(a) | The World Map of Artificial Intelligence Collaboration. The bubbles represent the top 199 institutions
 *Figure 1(a) | The World Map of Artificial Intelligence Collaboration. The bubbles represent the top 199 institutions* 1971년부터 2020년까지 50년간 OpenAlex 데이터를 활용하여 15개 자연과학 분야의 국제 및 기관 간 연구 협력 현황과 진화를 시각화한 종합 지도책(Atlas)이다.
OpenAlex의 오픈 데이터를 활용하여 50년간 15개 과학 분야의 국제 협력 현황을 종합적으로 시각화한 선도적 자료로, 정책 입안자 및 연구 관리자에게 직관적이고 실용적인 인사이트를 제공한다. 다만 데이터 완전성과 공저자 관계의 한계를 인식하고 활용하면 과학 외교 및 R&D 정책 수립의 중요한 참고 자료가 될 수 있다.
Community Detection in Graphs
그래프에서 커뮤니티 구조(community structure)를 검출하는 문제를 종합적으로 분석하고, 통계물리학 기반 방법론들을 중심으로 다양한 탐지 알고리즘들을 체계적으로 정리한 포괄적 리뷰 논문이다.
이 논문은 커뮤니티 검출 문제를 최초로 종합적으로 정리한 영향력 있는 리뷰로, 다양한 방법론의 통일된 이해를 제공하며 분야의 표준 참고문헌이 되었다. 다만 계산 확장성과 일부 미해결 이론적 문제들은 향후 연구 과제로 남아 있다.
Comparative science mapping: a novel conceptual structure analysis with metadata
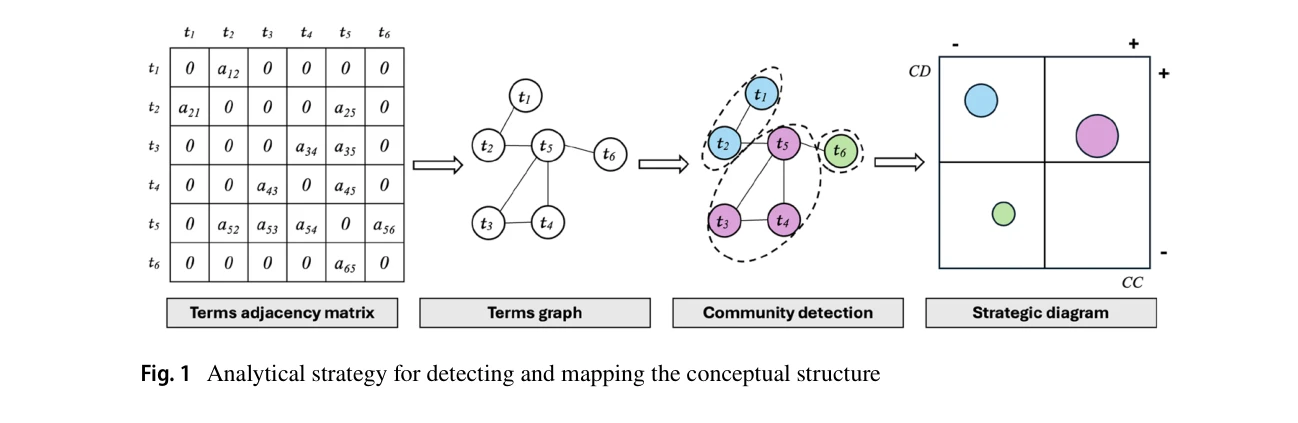
Fig. 1 Analytical strategy for detecting and mapping the conceptual structure
 *Fig. 1 Analytical strategy for detecting and mapping the conceptual structure* 메타데이터를 활용한 비교 과학지도(comparative science mapping) 기법을 제안하여, 저자, 기관, 지역 등의 특성에 따라 과학출판물의 개념 구조를 다중 관점에서 분석하고 시각화한다.
메타데이터를 활용하여 기존 과학지도 기법을 창의적으로 확장한 연구로, 이탈리아 종양학 연구의 종합적 분석을 통해 정책 입안과 기관 전략 수립에 실질적 기여를 제공한다.
Evolution of the social network of scientific collaborations
1991-1998년 8년간의 수학 및 신경과학 논문 데이터베이스를 분석하여 과학자 협력 네트워크의 진화 메커니즘을 규명한 연구로, scale-free 네트워크 특성과 preferential attachment 현상을 실증적으로 검증하고 모델링했다.
복잡계 네트워크 과학의 고전적 논문으로, 협력 네트워크의 동역학적 진화를 최초로 체계적으로 분석하고 preferential attachment를 실증적으로 검증하여 scale-free 네트워크 이론의 실증적 기초를 확립했다. 실증-모델-시뮬레이션의 삼각 검증 방법론과 내부/외부 링크 구분 모델은 이후 네트워크 과학 연구의 표준 방법론으로 광범위하게 채택되었다.
Fast Unfolding of Communities in Large Networks
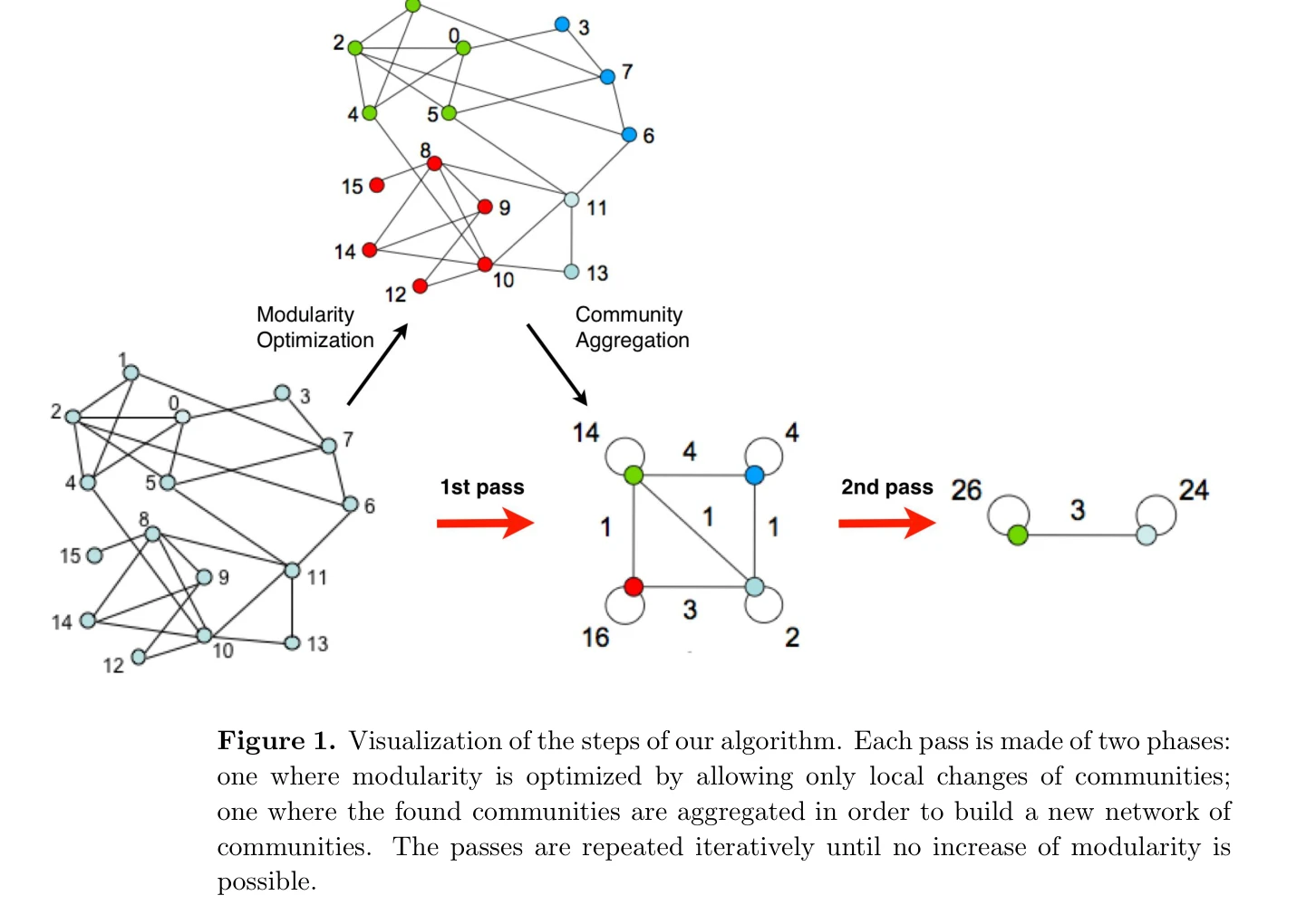
Figure 1. Visualization of the steps of our algorithm. Each pass is made of two phases:
 *Figure 1. Visualization of the steps of our algorithm. Each pass is made of two phases:* 대규모 네트워크에서 모듈성(modularity) 최적화 기반의 빠른 커뮤니티 검출 알고리즘을 제안하며, 선형에 가까운 시간복잡도로 수백만 개 노드를 처리할 수 있다.
매우 효율적이고 실용적인 커뮤니티 검출 알고리즘으로, 선형에 가까운 복잡도와 계층적 구조 해석 능력을 통해 대규모 네트워크 분석 분야에서 획기적 기여를 한다. 명확한 방법론과 강력한 실험 검증이 돋보이는 우수한 논문이다.
Global patterns of migration of scholars with economic development
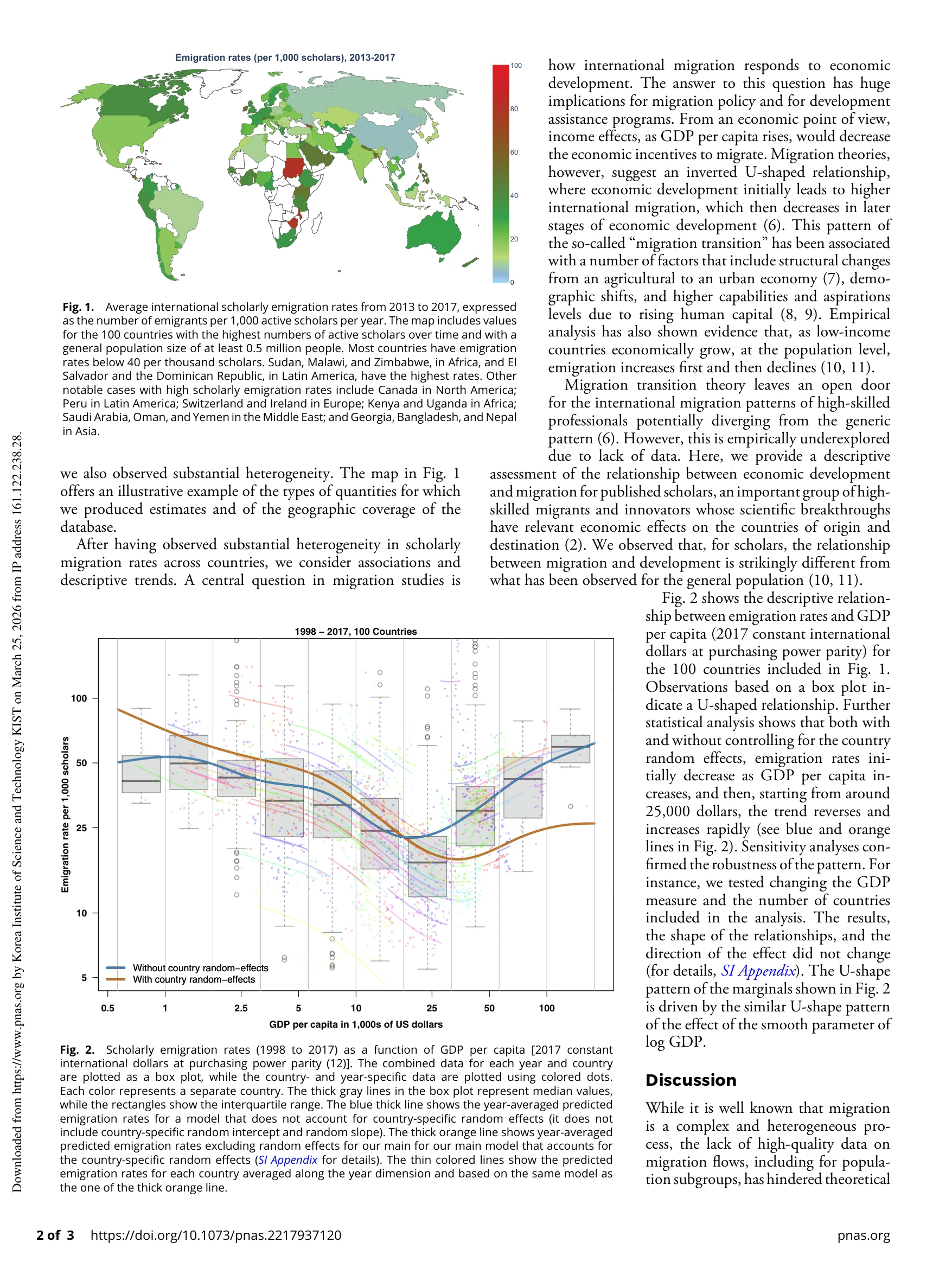
Fig. 1.
 *Fig. 2.* Scopus의 3,600만 개 학술논문 메타데이터를 활용하여 1998-2017년 전 세계 학자(scholars)의 국제 이주 패턴을 분석한 결과, 경제발전에 따른 학자 이주율이 U자형 곡선을 보임을 발견했다.
본 연구는 대규모 서지 데이터를 혁신적으로 활용하여 학자 이주에 대한 최초의 포괄적 글로벌 분석을 제공하며, 일반 인구와 다른 U자형 패턴을 발견함으로써 이주 이론의 확장에 기여한다.
Mapping scientific communities at scale
Figure 1: Visualization of a network with VOSviewer.
 *Figure 1: Visualization of a network with VOSviewer.* 대규모 bibliometric 데이터셋에서 과학 공동체를 효율적으로 매핑하기 위해 노드 필터링 대신 링크 필터링(strongest interactions)을 우선하는 새로운 방법론을 제시한다. Elasticsearch, Graphology, VOSviewer 등을 통합하여 scalable network analysis framework를 구축했다.
대규모 bibliometric 데이터에서 network analysis의 확장성 문제를 실용적으로 해결한 우수한 엔지니어링 작업이다. 링크 중심 필터링과 Elasticsearch 사전 계산이라는 간단하지만 효과적인 기법으로 백만 단위 출판물을 실시간 처리할 수 있게 했으며, 오픈소스 공개와 다층 기관 지원으로 실제 정책 결정에 즉시 활용 가능하다는 점에서 높은 가치가 있다.
Organisational accounts engaged in scholarly communication on Twitter: Patterns of presence, activity and engagement

Figure 1 presents the workflow used to identify organisational accounts that tweeted
 *Figure 2 shows the distribution of these accounts across the seven organisational* 트위터에서 학술 출판물에 대해 트윗한 9,842개 조직 계정(organizational accounts)을 식별하고, 이들의 소셜 미디어 자본(social media capital), 트윗 활동, 참여 수준의 패턴을 분석한 연구이다.
이 연구는 학술 커뮤니케이션에서 조직이 하는 중요한 역할을 체계적으로 규명하고, 재사용 가능한 공개 데이터셋을 제공함으로써 altmetrics 분야에 실질적인 기여를 한다. 다만 단일 플랫폼 분석과 기술적 깊이 면에서 개선의 여지가 있다.
Category Overview
# AI for Science: Gender, Diversity & Equity 카테고리 개요 과학 분야에서의 젠더, 다양성 및 형평성(Gender, Diversity & Equity) 연구는 과학 생태계의 구조적 불평등을 정량적으로 분석하고 개선하기 위한 중요한 학제적 노력입니다. 이 카테고리의 14편 논문들은 크게 세 가지 주요 영역을 다루고 있습니다: 첫째, 저자 데이터베이스 구축 및 과학 지도 작성(Science Mapping)을 통한 객관적인 성별 격차 측정 [1052][1054][1055], 둘째, 인용 패턴 분석과 텍스트 마이닝(Text Mining)을 이용한 과학적 신용 배분의 불평등 구조 파악 [1053][1056][1057][1059], 셋째, 역사적 추이 분석과 교차성(Intersectionality) 관점에서의 다층적 불평등 이해 [970][976]입니다. 특히 여성 과학자들이 동등한 기여에도 불구하고 적절한 인정을 받지 못하는 현상 [1059]과 젠더 다양성이 높은 팀이 더 혁신적이고 영향력 있는 연구를 생산한다는 발견 [965]은 형평성 개선의 과학적 근거를 제공합니다. 이러한 연구들은 비뚤림 감지(Bias Detection), 메타분석(Meta-analysis) 등 AI 및 데이터 과학 기법을 활용하여 과학 출판 및 평가 시스템의 투명성을 높이고, 궁극적으로 더 포용적이고 정의로운 과학 생태계 구축을 목표하고 있습니다.
⚠ 갭: 성별 격차의 근본 원인과 생애주기별 맞춤형 지원 방안에 대한 연구가 부족하다
🏛 정책: 여성 과학자의 경력 지속성과 리더십 개발을 위한 구조적 지원 체계 강화가 필요하다
The Preeminence of Ethnic Diversity in Scientific Collaboration
Fig. 1 Exploring homophily in real vs. randomized data. Each column corresponds to a different class of diversity, and e
 *Fig. 3 Group and individual diversity vs. impact in each subfield. In each subplot, the points correspond to subfields, th* 900만 개 논문과 600만 명의 과학자를 분석하여 인종(ethnic) 다양성이 과학적 협력의 영향력(citation impact)과 가장 강하게 상관관계를 가지며, 인종 다양성이 높은 논문은 10.63%, 과학자는 47.67%의 영향력 증가를 보임을 입증했다.
본 논문은 대규모 데이터와 엄밀한 통계방법으로 인종 다양성이 다른 형태의 다양성보다 과학적 영향력에 훨씬 강한 긍정적 상관관계를 가짐을 처음으로 체계적으로 입증했으며, 다양성 정책의 과학적 근거를 제공하는 중요한 공헌이다. 다만 명명화 인종 분류의 한계와 인과성 미보장 등 방법론적 제약이 있다.
Unsupervised embedding of trajectories captures the latent structure of scientific migration
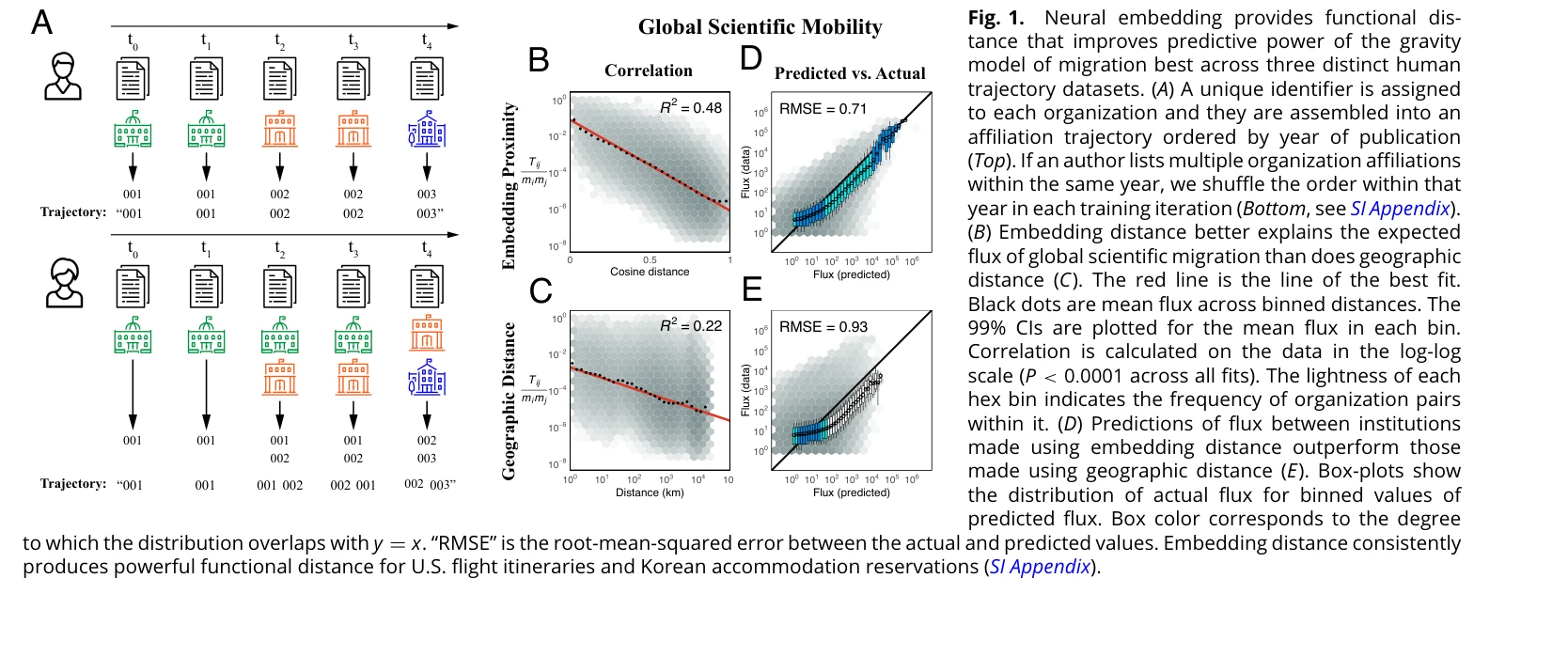
Fig. 1.
 *Fig. 1.* Word2vec 신경망 임베딩 모델을 마이그레이션 궤적에 적용하여 위치 간의 잠재적 관계를 벡터 공간에 인코딩하고, 과학자 300만 명의 이동 패턴에서 문화, 언어, 명성 등 다층적 구조를 학습할 수 있음을 입증했다.
본 논문은 Word2vec과 중력 모델의 수학적 동치성을 증명하고 과학자 마이그레이션 300만 건에 적용하여, 신경망 임베딩이 다층적 사회 현상의 구조를 효과적으로 학습할 수 있음을 보였다. 이론과 실증이 결합된 견고한 방법론론과 높은 사회과학적 의의로 우수한 연구이나, 데이터 편향과 의미론적 해석의 엄밀성 개선이 필요하다.
Unsupervised Word Embeddings Capture Latent Knowledge from Materials Science Literature
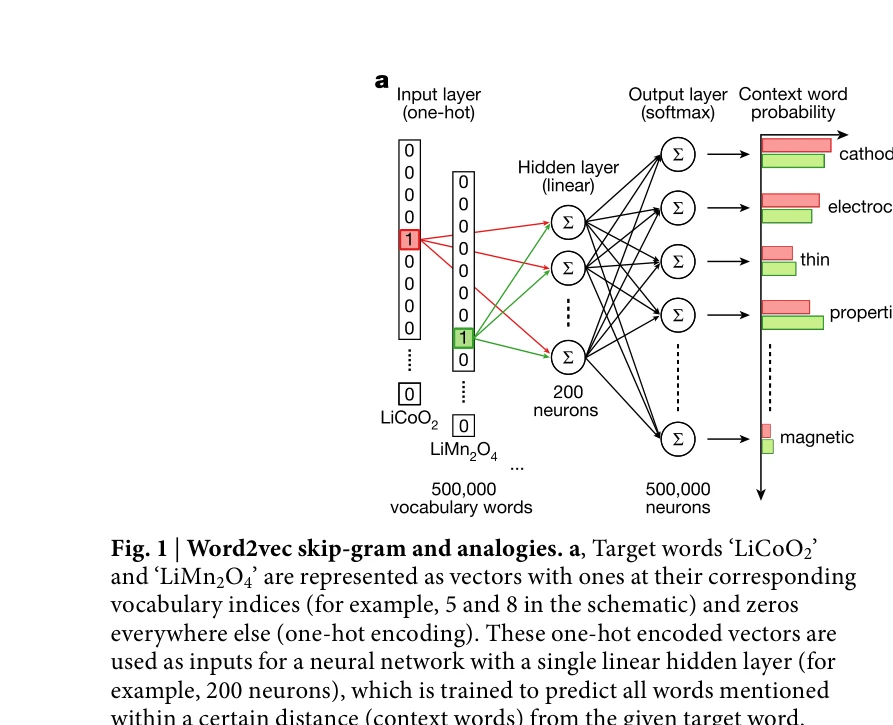
Fig. 1 | Word2vec skip-gram and analogies. a, Target words ‘LiCoO2’
 *Fig. 3 | Validation of the predictions. a, Results of prediction of* 비지도 학습 기반 word embeddings을 재료과학 문헌에 적용하여 화학적 지식을 명시적으로 입력하지 않고도 주기율표 구조와 물질-특성 관계를 자동으로 인코딩하며, 미래 열전재료를 사전에 예측할 수 있음을 입증한 연구이다.
본 연구는 비지도 학습 기반 word embeddings을 재료과학에 처음 적용하여 문헌에 숨겨진 지식을 자동으로 인코딩하고 미래 발견을 예측 가능함을 실증적으로 입증한 획기적인 작업이다. 자연언어처리와 재료과학의 융합 연구로서 학문 간 경계를 확장하며, 추후 AI 기반 과학 발견 가속화의 중요한 토대가 된다.
Updated science-wide author databases of standardized citation indicators
Scopus 데이터를 기반으로 2020년 5월까지의 업데이트된 과학자 인용 지표 데이터베이스를 제공하며, 상위 100,000명 과학자와 각 세부분야 상위 2% 과학자의 표준화된 인용 지수를 공개한다.
본 논문은 과학자의 학술적 영향력을 측정하기 위한 표준화된 인용 지표 데이터베이스의 중요한 업데이트를 제공하며, 머신러닝을 활용한 분류 개선과 자기인용 분석 강화로 학술 평가의 투명성과 공정성을 크게 향상시킨다. 완전히 공개된 데이터와 명확한 방법론으로 학술 커뮤니티에 실질적인 기여를 한다.
Visualizing the context of citations referencing papers published by Eugene Garfield: a new type of keyword co-occurrence analysis
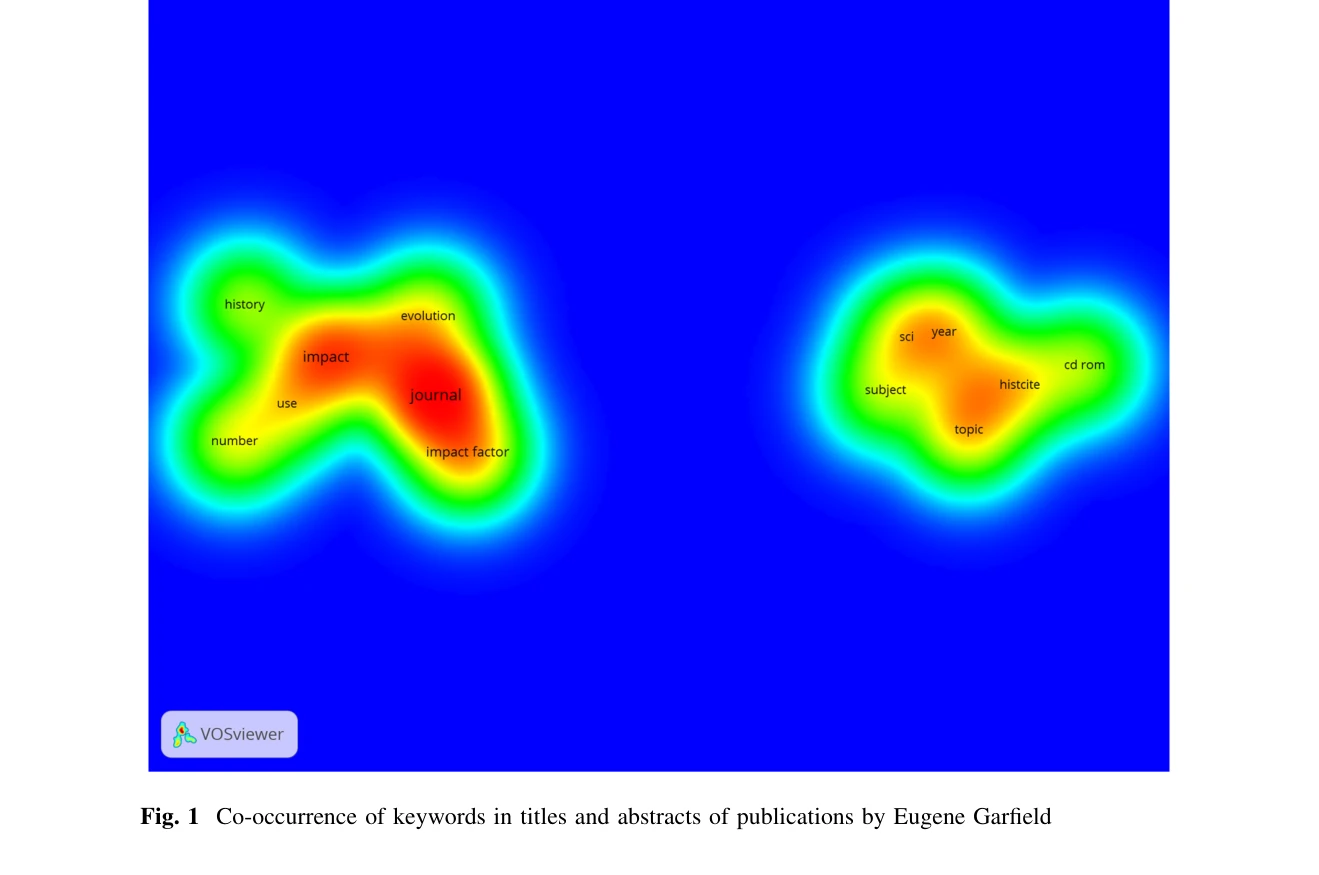
 *Fig. 3 Co-occurrence of keywords in citation contexts of papers referencing Eugene Garfield* Eugene Garfield의 논문들을 인용한 논문들의 인용 맥락(citation context)을 기반으로 키워드 동시출현 네트워크(keyword co-occurrence network)를 생성하는 새로운 유형의 문헌계량 네트워크를 제안한다.
인용 맥락 기반 키워드 동시출현 네트워크라는 새로운 분석 방법을 제안하고, 인용이 인용된 논문의 인지적 영향을 반영한다는 이론을 실증적으로 검증한 의미 있는 연구이다. 다만 표본 크기 제약과 Microsoft Academic의 불완전한 데이터 커버리지를 개선하면 더욱 강력한 연구가 될 수 있다.
What's In Your Field? Mapping Scientific Research with Knowledge Graphs and Large Language Models
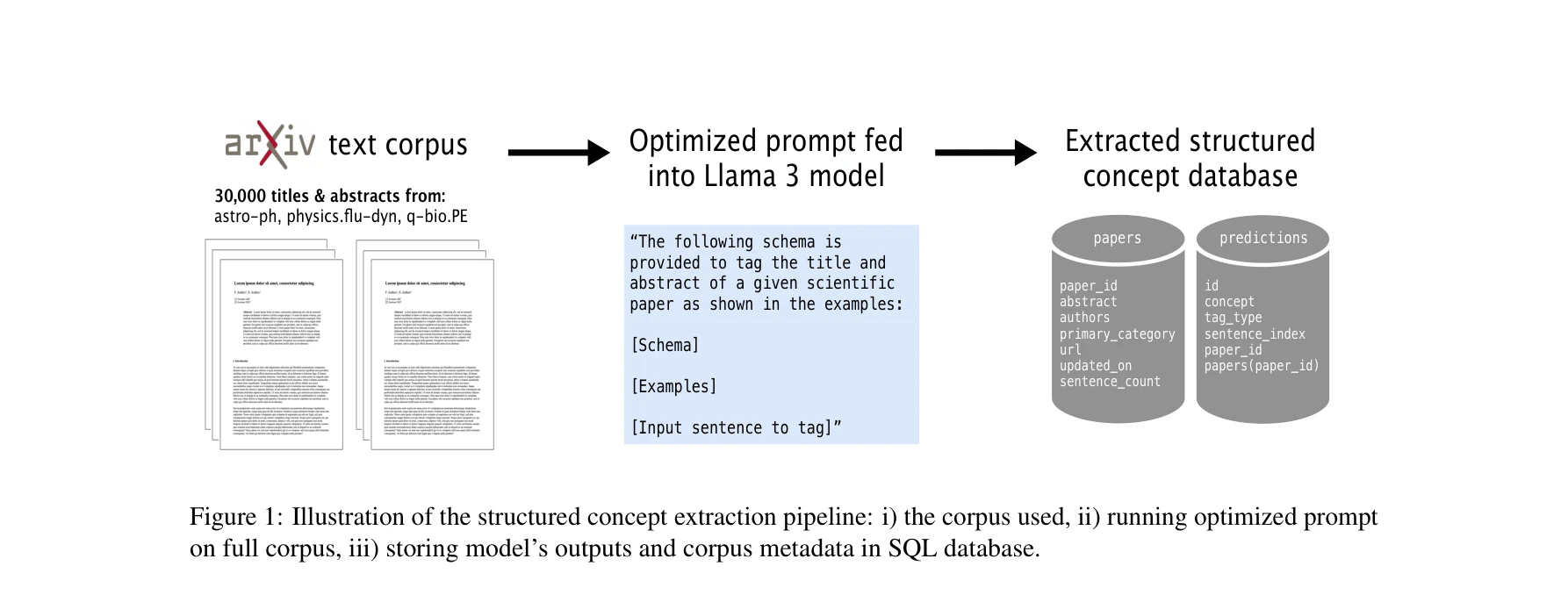
Figure 1: Illustration of the structured concept extraction pipeline: i) the corpus used, ii) running optimized prompt
 *Figure 1: Illustration of the structured concept extraction pipeline: i) the corpus used, ii) running optimized prompt* LLM을 이용한 구조화된 개념 추출을 통해 과학 논문의 지식 그래프를 구축하고, 대규모 문헌에서 체계적으로 연구 패턴과 동향을 분석할 수 있는 시스템을 제시한다.
이 논문은 대규모 과학 문헌 분석의 중요한 문제에 창의적이고 실용적인 솔루션을 제시하며, 구조화된 지식 추출을 통해 연구 동향 분석을 체계화했다. 추출 정확도의 한계가 있으나 30,000개 논문의 성공적 처리와 실제 인터페이스 제공으로 높은 실무 가치를 입증한다.
When text mining meets science mapping in the bibliometric analysis: A review and future opportunities
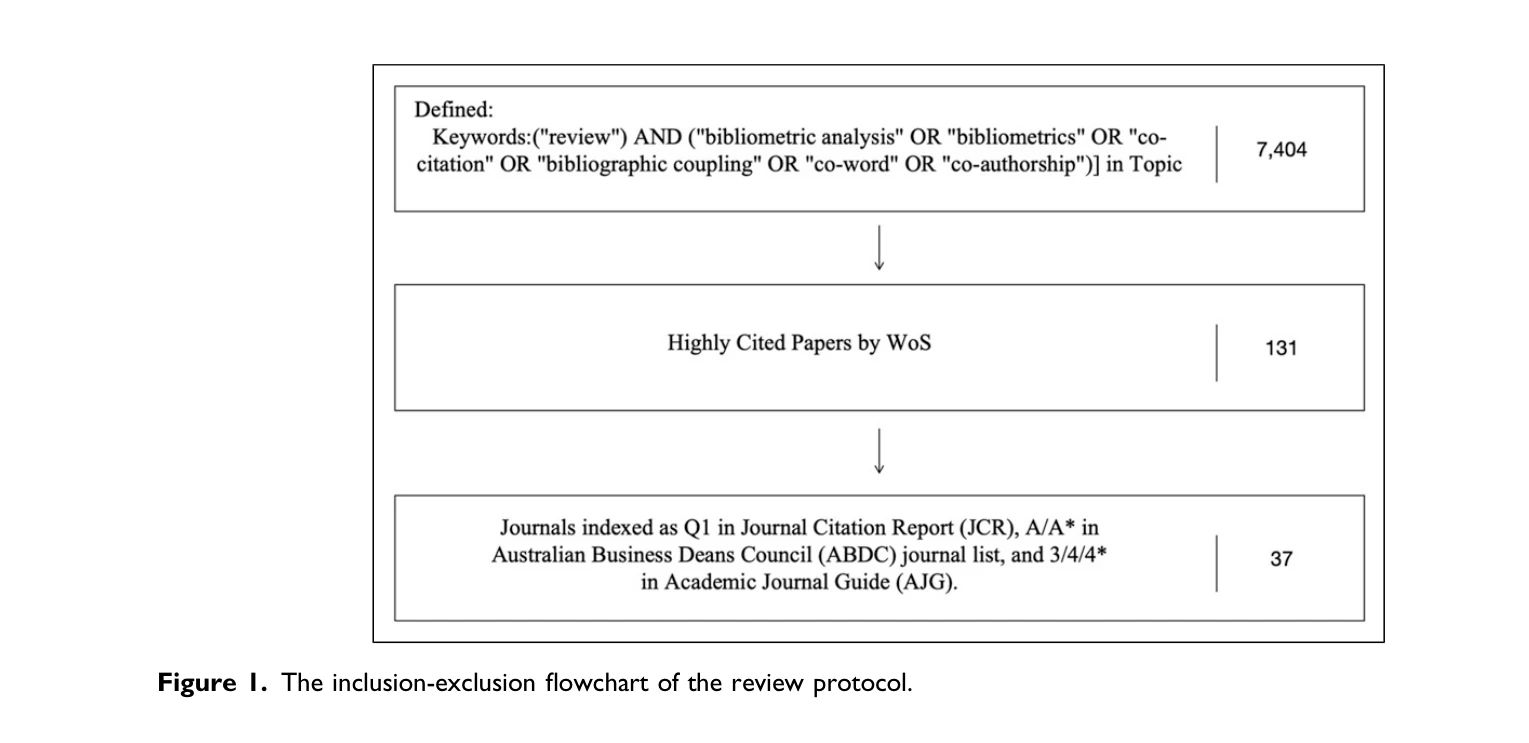
Figure 1. The inclusion-exclusion flowchart of the review protocol.
 *Figure 3. The framework of the science mapping process.* 과학 출판물의 급증으로 인해 문헌 검토 효율성이 중요해졌으며, 본 논문은 bibliometric analysis(서지학적 분석)에서 text mining(텍스트 마이닝)을 결합한 science mapping(과학지도)의 프레임워크를 종합적으로 검토한다.
본 논문은 급증하는 과학 출판 데이터 시대에 bibliometric analysis와 text mining의 통합 필요성을 명확히 하고, 체계적인 문헌 검토를 통해 현황을 파악한 가치 있는 종합 리뷰 논문이다. 다만 text mining 기법의 구체적인 적용 방법론과 사례 연구가 보완된다면 더욱 실용적이고 영향력 있는 기여가 될 것이다.
Where Do Your Citations Come From? Citation-Constellation: A Free, Open-Source, No-Code, and Auditable Tool for Citation Network Decomposition with Complementary BARON and HEROCON Scores

 *Figure 2: Score panel in both interfaces.* Citation-Constellation은 인용 네트워크를 사회적·구조적 근접성에 따라 분해하는 무료 오픈소스 도구로, BARON과 HEROCON 두 가지 보완적 지표를 통해 연구자의 인용 출처를 분석한다.
이 논문은 오랫동안 이론적으로만 존재해온 인용 네트워크 분해 개념을 완전히 투명하고 접근 가능한 운영 도구로 구현한 중요한 기여이며, 책임 있는 연구 평가 운동과 오픈 사이언스에 부합하는 민주화된 인프라를 제공한다.
Which stylistic features fool ChatGPT research evaluations?
ChatGPT는 연구 품질 평가 시 실제 연구 품질과 무관한 언어적 복잡성과 초록 길이에 과도하게 영향을 받으며, 이는 인간 전문가의 평가와 다른 편향된 패턴을 보여준다.
본 논문은 ChatGPT의 연구 평가에서 나타나는 체계적 편향을 경험적으로 입증하여 AI 기반 평가 시스템의 신뢰성 문제를 제기하며, 실무적으로 LLM 기반 연구 평가 도입 시 주의해야 할 점을 명확히 제시한다.
Why Most Published Research Findings Are False
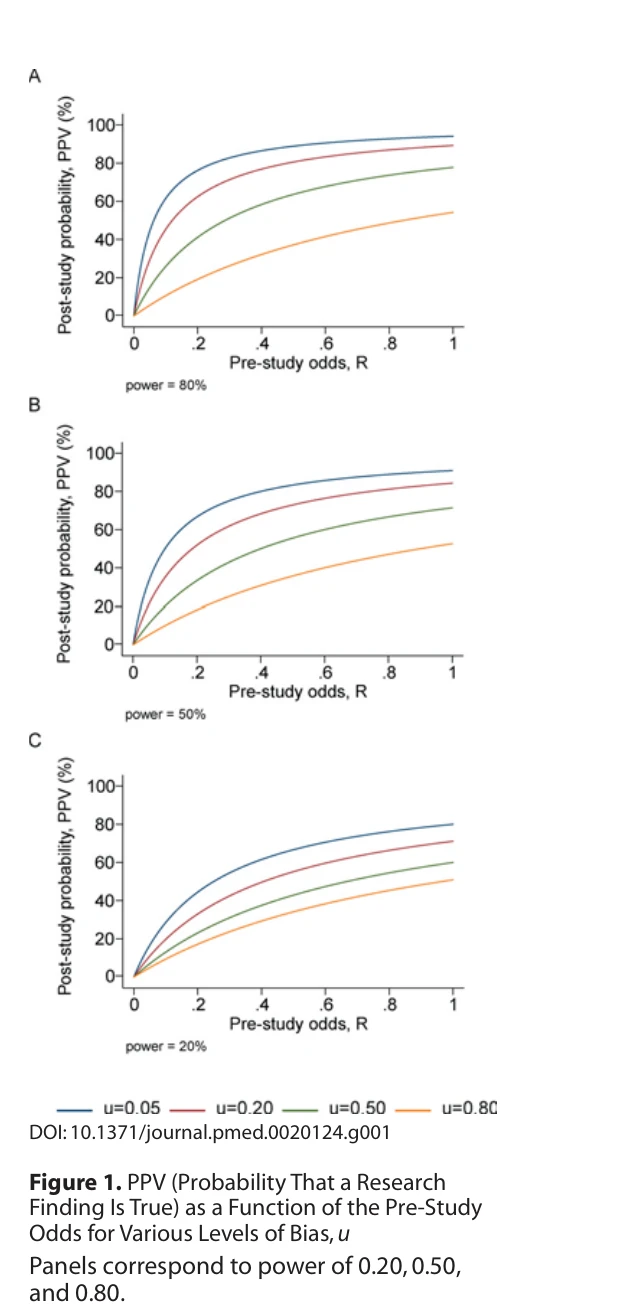
Figure 1. PPV (Probability That a Research
 *Figure 1. PPV (Probability That a Research* 통계적 유의성(p<0.05)에만 의존한 연구방식으로 인해 출판된 대부분의 연구 결과가 거짓일 가능성이 높다는 수학적 증명과 분석.
과학 출판의 신뢰성 위기를 수학적으로 증명한 획기적 논문으로, 단순한 비판을 넘어 왜 체계적으로 거짓 발견이 나타나는지 정량적으로 설명했다. 이후 메타-과학(meta-science)과 재현 위기 논의의 이론적 토대를 제공했다.
Women are credited less in science than men
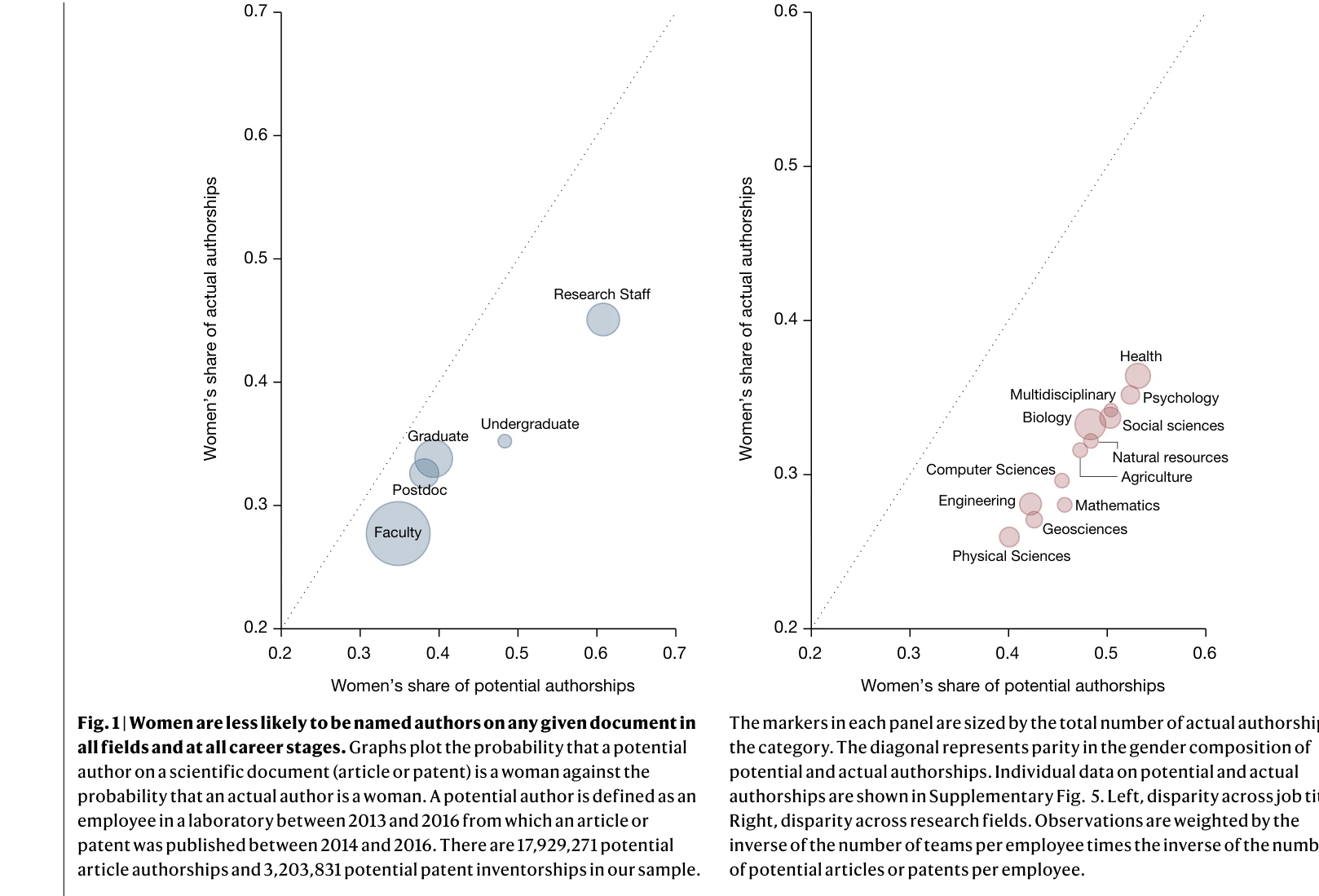
Fig. 1 | Women are less likely to be named authors on any given document in
 *Fig. 1 | Women are less likely to be named authors on any given document in* 과학 분야에서 여성 연구자들이 남성 동료에 비해 저자 표시(authorship credit)를 받을 확률이 현저히 낮으며, 이는 생산성 차이가 아닌 기여도 인정의 차이에서 비롯된다.
과학 분야의 성별 격차가 단순 생산성 차이가 아닌 기여도 인정 격차에서 비롯된다는 것을 대규모 행정 데이터, 설문, 질적 분석으로 강력하게 입증한 매우 중요한 논문이다. 구조적 성차별 문제를 통계적으로 규명하고 정책 개입의 방향을 제시한다는 점에서 높은 학술적·사회적 가치를 지닌다.
Bibliometrics: Global Gender Disparities in Science
본 논문은 세계적 규모의 서지계량학(Bibliometrics) 분석을 통해 과학 연구 분야에서 지속되는 성별 불균형을 실증적으로 입증한다.
본 논문은 과학계의 성별 격차를 서지계량학적으로 실증한 획기적 연구로서, 정책 입안자와 학계 지도자들에게 구체적인 증거를 제공하여 성평등 문화 조성에 기여한다. 다만 분석 대상이 Nature에 한정되어 있어 일반화 가능성의 제고가 필요하다.
Gender-diverse teams produce more novel and higher-impact scientific ideas
Fig. 1A plots the upward trend of women’s participation in medical science from 2000
 *Fig. 1A plots the upward trend of women’s participation in medical science from 2000* 660만 편의 의료과학 논문을 분석하여 성별 다양성 팀(mixed-gender teams)이 단일 성별 팀보다 더 참신하고 영향력 있는 연구 결과를 생산함을 입증했다. 성별 균형이 높을수록 논문의 참신성(novelty)과 영향력(impact)이 증가하는 경향을 발견했다.
대규모 의료과학 논문 데이터를 분석하여 성별 다양성 팀이 참신하고 영향력 있는 연구를 생산함을 엄밀하게 입증한 우수한 논문이다. 결과의 일관성, 통제변수의 충실성, 정책적 함의의 중요성이 높으나, 관찰 데이터의 한계와 메커니즘 미해명 부분이 개선 대상이다.
Global citation inequality is on the rise
2000년부터 2015년까지 15년간 426만 명의 저자와 2,600만 편의 논문을 분석한 결과, 상위 1% 인용 엘리트 과학자들의 인용 점유율이 14%에서 21%로 증가하며 글로벌 인용 불평등이 심화되고 있음을 보여준다.
이 연구는 대규모 저자 동일성 확인 데이터를 활용하여 글로벌 과학 시스템의 인용 불평등이 심화되고 있음을 처음 정량적으로 입증한 중요한 논문이다. 다만 인용을 성공의 단일 지표로 보는 한계와 인과관계의 불명확성, 제도적 메커니즘에 대한 분석 부족이 있어 후속 질적·정책 연구가 필요하다.
Historical Comparison of Gender Inequality in Scientific Careers Across Countries and Disciplines
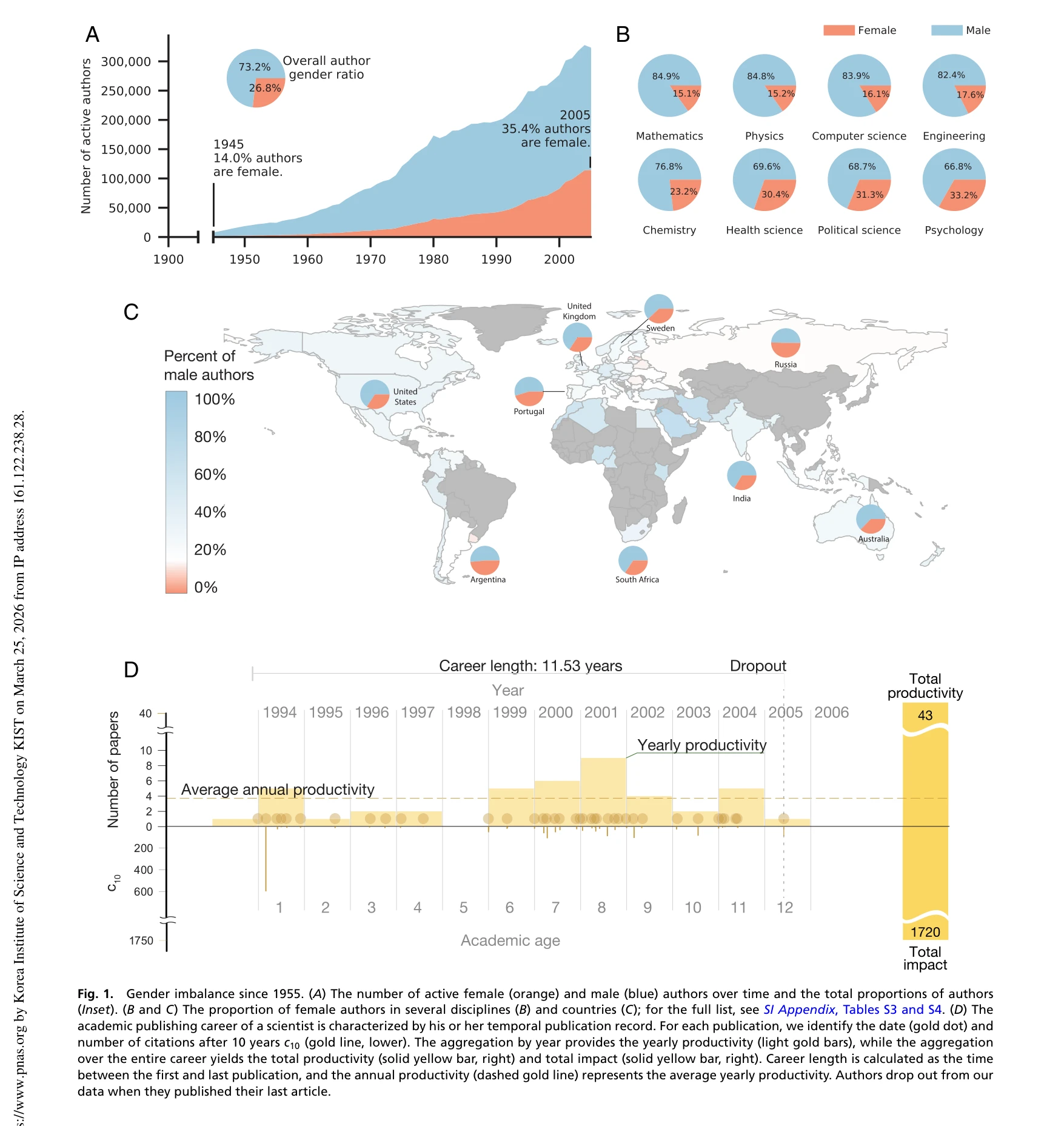
Fig. 1.
 *Fig. 1.* 1955-2010년 153만 명 과학자의 출판 경력을 분석한 결과, 여성의 과학 참여 증가에도 불구하고 생산성(productivity)과 영향력(impact)의 성별 격차는 오히려 증가했으며, 이는 주로 경력 길이와 이탈률(dropout rate)의 차이로 설명된다.
이 논문은 대규모 비블리오메트릭 데이터와 정교한 통계 분석으로 성별 불평등의 역설적 증가를 실증하고, 생산성 격차의 구조적 원인(경력 길이·이탈률)을 규명하여 학계의 정책 논의를 근본적으로 재구성하는 의미 있는 기여를 한다.
Intersectional inequalities in science
본 연구는 교차성(intersectionality) 관점에서 미국 과학인력의 인종과 성별 다양성이 연구주제 선택과 과학적 영향력에 미치는 영향을 대규모 문헌계량학(bibliometrics) 분석으로 규명했다.
본 논문은 교차성 분석을 대규모 문헌계량학 데이터에 적용하여 과학 다양성과 혁신의 관계를 새로운 방식으로 규명한 중요한 연구이다. 다만 이름 기반 인종 분류의 오류와 인과메커니즘 규명의 한계가 있으나, 과학 정책 수립에 실질적 함의를 제공한다.
Category Overview
AI for Science 카테고리는 인공지능과 대규모 언어모델(LLM)이 과학 연구의 패러다임을 어떻게 변화시키고 있는지를 다루는 14편의 논문을 포함하고 있습니다. 이 카테고리는 AI 과학자의 역할 정의부터 시작하여, 인간 중심의 AI(human-aware AI)가 과학 가속화에 미치는 영향, 그리고 기초 모델(Foundation Models)이 과학 발견을 어떻게 촉진하는지를 폭넓게 탐구합니다[1065][1066][1072]. 동시에 AI 기반 자동화(AI-Driven Automation)의 실제 적용, 고처량 물질 예측의 도전 과제, 그리고 개방형 데이터셋(Open Datasets)의 중요성 등 실질적인 과학 연구 환경의 변화를 분석합니다[931][1070][991]. 이와 함께 AI로 인한 과학적 신규성(Research Novelty) 감소 문제, AI의 이해 착각(illusions of understanding) 문제, 그리고 학문의 게이트키퍼 역할 변화 등 비판적 관점도 함께 제시합니다[953][1068][1069]. 또한 생의학 분야의 가설 자동 생성(Automatic Hypothesis Generation), 언어모델 과학(Science of Language Models), 촉매 분야의 오픈 데이터셋 등 특정 응용 분야의 구체적 사례도 포함하고 있습니다[1073][1074][1075]. 이 카테고리는 과학 연구 생태계와 사회 간의 상호작용, 그리고 측정 및 실증 방법론의 변화까지 다루며, AI가 과학의 미래를 형성하는 과정의 다각적 측면을 조명합니다[942][1071].
⚠ 갭: AI 기반 과학 연구의 품질 검증과 신뢰성 확보를 위한 체계적 평가 방법론이 부족하다
🏛 정책: AI 활용 연구의 윤리적 가이드라인과 품질 관리 체계 구축이 필요하다
A Survey of AI Scientists
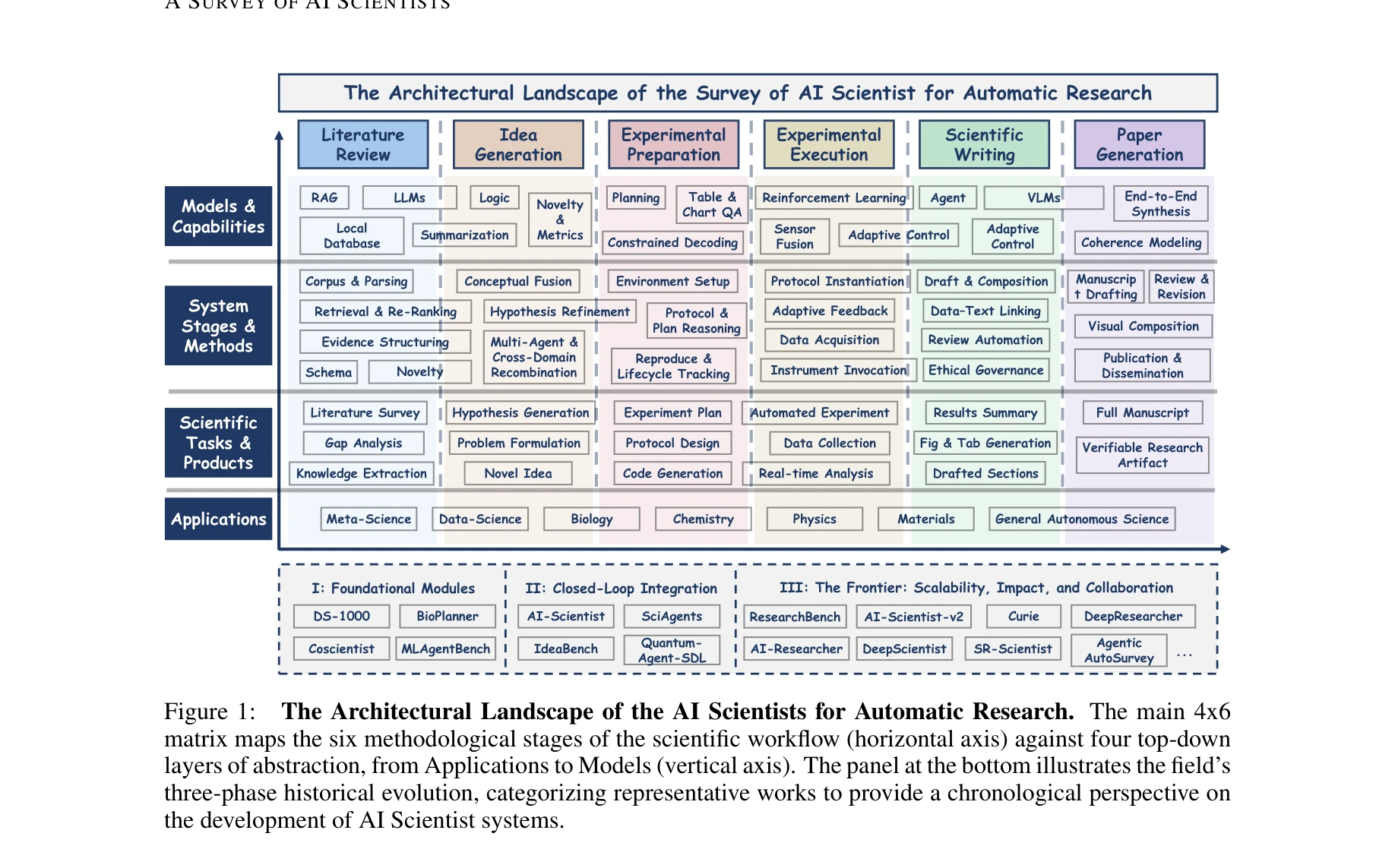
Figure 1:
 *Figure 1:* AI 과학자(AI Scientist) 시스템의 문헌 조사로, 자동화된 과학 발견의 완전한 파이프라인을 6단계 방법론 프레임워크를 통해 체계적으로 분류하고 분석한다.
이 서베이는 급속히 성장하는 AI 과학자 분야를 처음으로 체계적이고 포괄적으로 정리한 중요한 작업으로, 6단계 프레임워크를 통해 방법론적 원칙을 명확히 하고 미래 연구의 로드맵을 제시한다. 다만 정량적 성능 비교와 크로스-도메인 일반화에 대한 실증적 분석이 강화되면 더욱 완성도 있는 리뷰가 될 수 있다.
Accelerating science with human-aware artificial intelligence

Figure 1 illustrates a modular and scalable Artificial Orches-
 *Figure 1 illustrates a modular and scalable Artificial Orches-* AI 기반 자동화 약물 발견을 위해 복잡한 실험실 워크플로우를 통합 관리하는 Artificial 오케스트레이션 플랫폼을 제시한다. 데이터 사일로(data silos) 문제를 해결하고 NVIDIA BioNeMo와 같은 AI 모델을 자동화된 실험 프로세스에 통합한다.
본 논문은 자동화 약물 발견의 현실적 도전과제들(데이터 사일로, 워크플로우 복잡성, AI 통합)을 종합적으로 해결하는 실용적인 오케스트레이션 플랫폼을 제시하며, 모듈식 아키텍처와 다중 프로토콜 지원으로 확장성이 우수하다. 다만 드라이 랩 사례만 제시되었으므로 웻 랩 검증과 대규모 실제 운영 환경에서의 성능 평가가 후속되어야 한다.
Artificial intelligence and illusions of understanding in scientific research
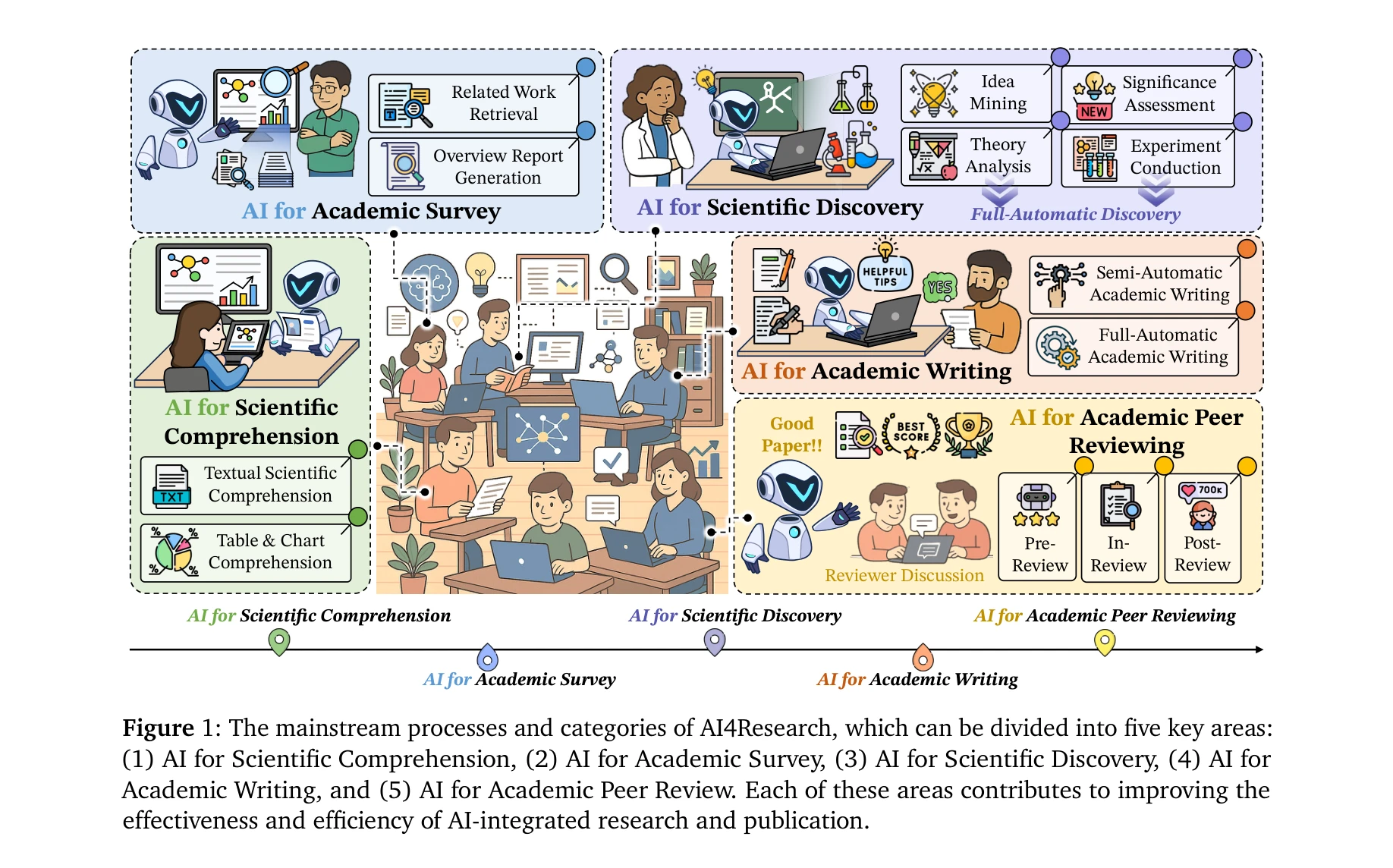
Figure 1: The mainstream processes and categories of AI4Research, which can be divided into five key areas:
 *Figure 2: The taxonomy of AI in research (AI4Research) is categorized into five key areas. Each area is* 본 논문은 AI4Research라는 체계적 분류법을 제시하여 과학 연구의 5가지 주요 작업(과학 이해, 학술 조사, 과학 발견, 학술 저술, 동료 평가)에 AI를 적용하는 현황을 종합적으로 조사한 학술 설문 논문이다.
본 논문은 AI4Research 분야의 첫 종합 설문으로서 5단계 파이프라인 분류, 다양한 학제간 응용 사례 수집, 풍부한 오픈 리소스 제공이라는 측면에서 높은 참고 가치가 있다. 다만 제목과 달리 'illusions of understanding'에 대한 비판적 분석이 약하고, 자동화 시스템의 과학적 엄밀성 보장 방안이 구체적이지 않은 점은 개선이 필요하다.
Breaking the gatekeepers: how AI will revolutionize scientific funding
AI 기술이 생물의학 연구비 배분 시스템의 기득권 구조를 와해시켜, 초기경력 과학자와 혁신적 아이디어에 더 공평한 기회를 제공할 수 있음을 주장한다.
이 논문은 과학 자금 배분 시스템의 구조적 결함을 설득력 있게 분석하고, AI 분야와의 대조를 통해 제도적 개선의 필요성을 강하게 주장한다. 다만 AI 기반 해결책의 기술적 구체화와 현실적 실행 방안이 부족하여, 정책 개혁의 첫 단계 진단으로서의 가치는 높으나 실제 구현으로 나아가기 위한 추가 연구가 절실하다.
Challenges in High-Throughput Inorganic Materials Prediction and Autonomous Synthesis
자동화 재료 발견 시스템(A-lab)의 43개 신규 재료 발견 주장을 재검토한 결과, 자동 Rietveld 분석의 신뢰성 부족과 재료의 무질서(disorder) 예측 누락으로 인해 실제로는 신규 재료가 발견되지 않았음을 지적한다.
자동화 재료 발견의 신뢰성 제고를 위한 중요한 비판적 분석으로, PXRD 특성화와 무질서 모델링의 두 가지 핵심 병목을 명확히 지적한다. 고처리량 재료 탐색의 실질적 진전을 위해 실험 결정학과 계산 화학의 협업 개선을 강력히 촉구하는 관점 논문이다.
Data, measurement and empirical methods in the science of science
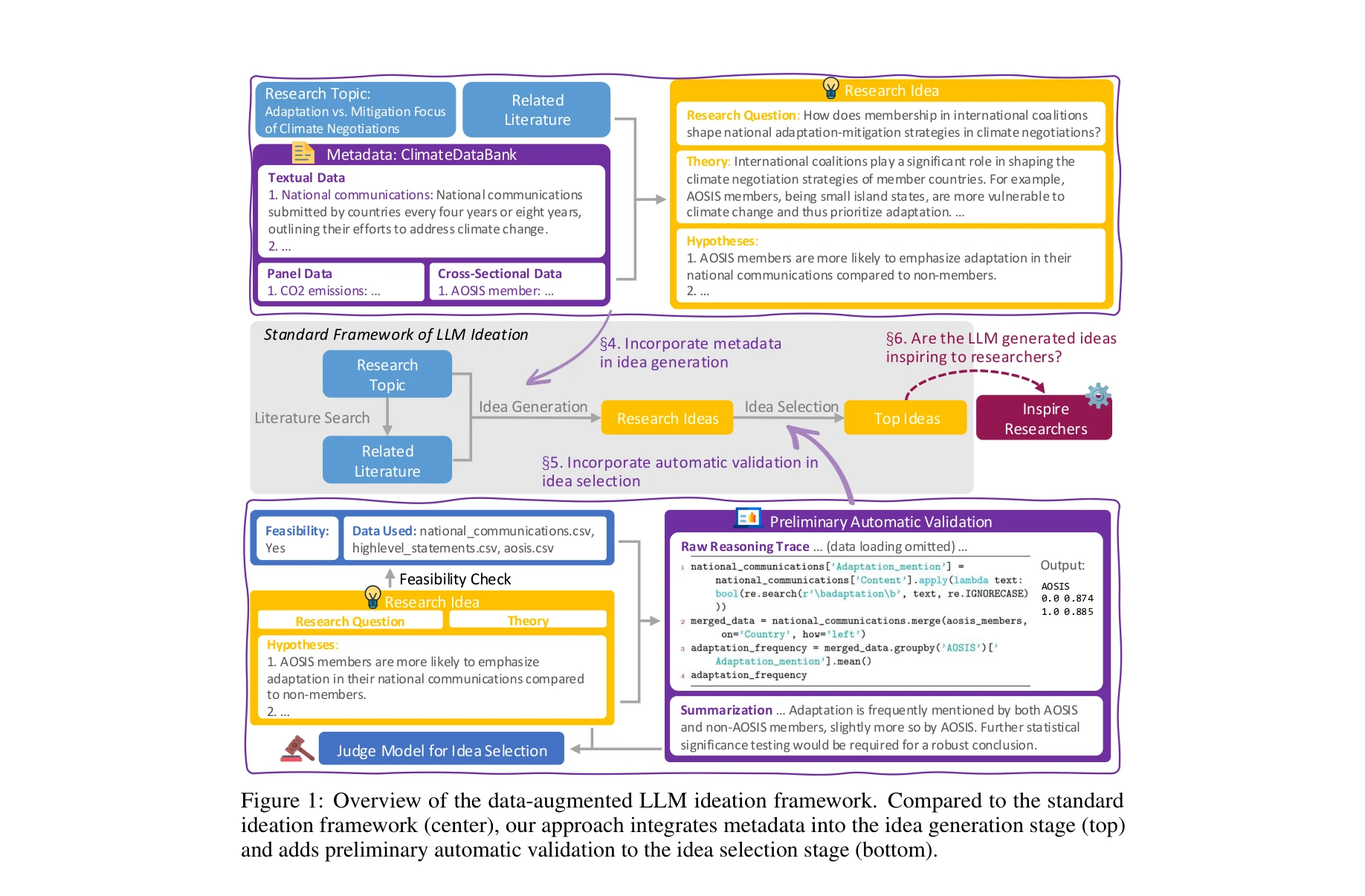
Figure 1: Overview of the data-augmented LLM ideation framework. Compared to the standard
 *Figure 1: Overview of the data-augmented LLM ideation framework. Compared to the standard* 대규모 언어모델(LLM)의 연구 아이디어 생성 과정에 메타데이터와 자동 검증을 통합하여 더 실현 가능하고 효과적인 아이디어를 생성하는 프레임워크를 제안한다.
LLM 기반 연구 아이디어 생성에 데이터를 전략적으로 통합하여 실현 가능성과 실증적 타당성을 동시에 향상시키는 실용적이고 창의적인 방법론을 제시하며, 인간-AI 협력의 실제 가치를 입증한 의미 있는 연구이다.
Embracing Foundation Models for Advancing Scientific Discovery
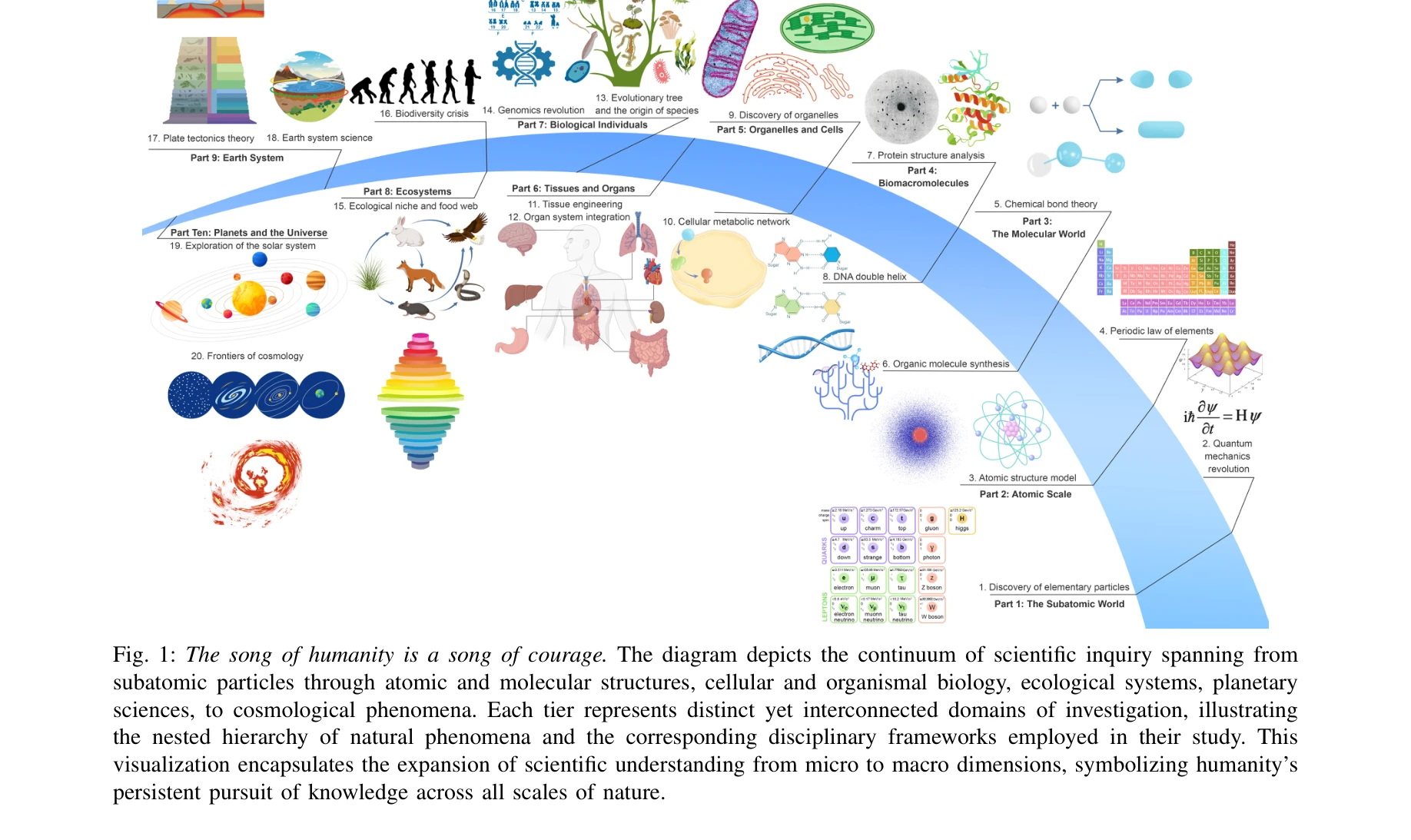
Fig. 1: The song of humanity is a song of courage. The diagram depicts the continuum of scientific inquiry spanning from
 *Fig. 1: The song of humanity is a song of courage. The diagram depicts the continuum of scientific inquiry spanning from* 본 논문은 과학 분야 대규모언어모델(Sci-LLM)의 발전을 데이터 중심으로 분석하는 종합 서베이로, 270개 이상의 사전학습/사후학습 데이터셋과 190개 이상의 벤치마크를 체계적으로 검토하여 과학 AI의 로드맵을 제시한다.
본 서베이는 과학 분야 AI의 발전을 데이터 관점에서 종합적으로 분석한 중요한 기여로, 과학 LLM 개발을 위한 이론적 프레임워크와 실무적 로드맵을 제시한다. 다만 정량적 성과 분석과 자율 에이전트 패러다임의 구체적 구현 사례가 보강될 필요가 있다.
MOLIERE: Automatic Biomedical Hypothesis Generation System
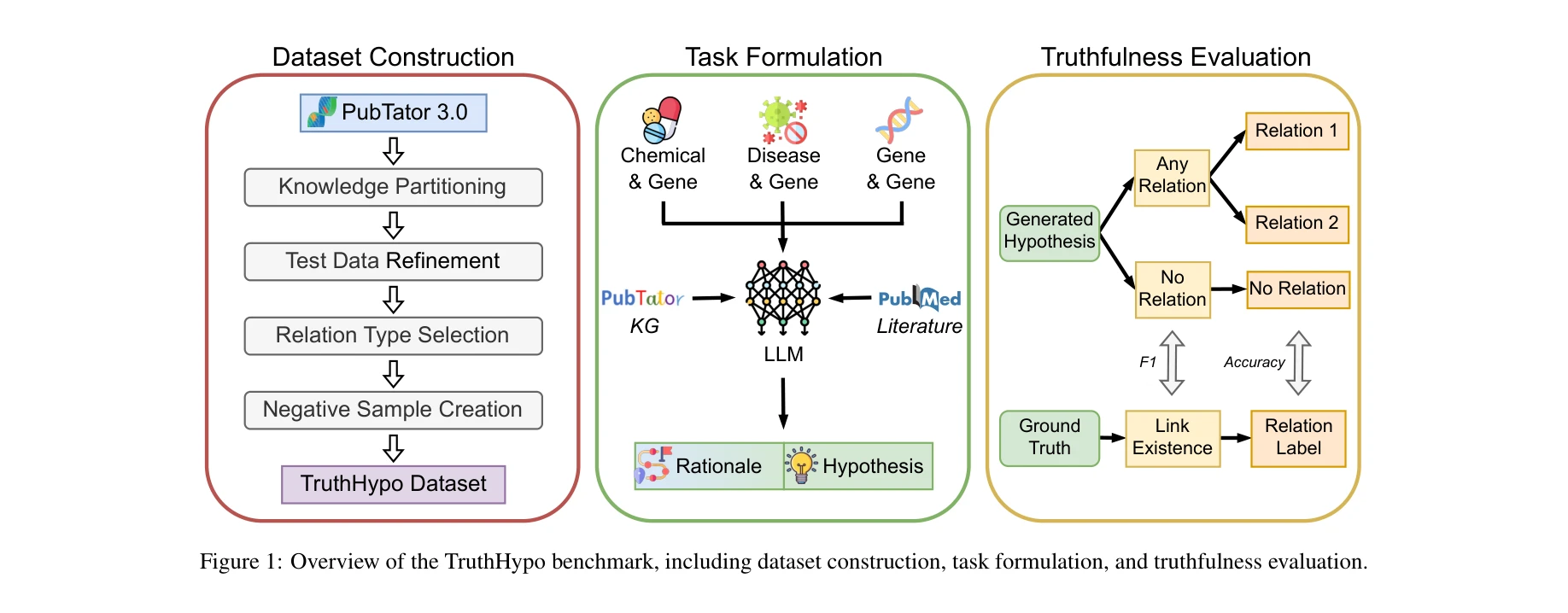
Figure 1: Overview of the TruthHypo benchmark, including dataset construction, task formulation, and truthfulness evalua
 *Figure 1: Overview of the TruthHypo benchmark, including dataset construction, task formulation, and truthfulness evalua* LLM의 생의학 가설 생성 능력을 평가하기 위해 TruthHypo 벤치마크와 KnowHD 할루시네이션 탐지 프레임워크를 제안하여, 생성된 가설의 진실성과 지식 기반성을 체계적으로 평가한다.
본 논문은 LLM 기반 과학 가설 생성의 신뢰성을 평가하는 중요한 문제를 체계적으로 다루며, TruthHypo와 KnowHD를 통해 진실성 평가와 할루시네이션 탐지의 새로운 접근법을 제시한다. 생의학 분야의 가설 생성 벤치마크와 실용적인 할루시네이션 탐지 도구로서 과학 발견 가속화에 기여할 수 있는 가치 있는 연구이다.
OLMo: Accelerating the Science of Language Models

Figure 1: Accuracy score progression of OLMo-7B on 8 core end-tasks score from Catwalk evaluation suite
 *Figure 1: Accuracy score progression of OLMo-7B on 8 core end-tasks score from Catwalk evaluation suite* OLMo는 훈련 데이터, 훈련 코드, 평가 도구까지 모두 공개한 완전 개방형 언어 모델(Open Language Model)이다. 이를 통해 언어 모델에 대한 과학적 연구를 가능하게 한다.
OLMo는 진정한 의미의 완전 개방형 언어 모델을 제공함으로써 언어 모델 연구의 투명성과 재현성을 획기적으로 향상시킨다. 데이터, 코드, 도구까지 모두 공개하는 이 종합적인 접근은 학술 커뮤니티에 큰 기여를 하며 향후 언어 모델 연구의 새로운 방향을 제시한다.
Open Catalyst 2020 (OC20) Dataset and Community Challenges

Figure 1: Adsorbates, materials, calculations,
 *Figure 1: Adsorbates, materials, calculations,* 촉매 발견을 가속화하기 위해 1.28백만 개의 DFT 계산을 포함한 OC20 데이터셋과 3개의 도메인 챌린지 과제를 제시하여 머신러닝 모델의 일반화 능력 향상을 목표로 함.
촉매 머신러닝 분야에서 획기적인 대규모 데이터셋을 제공하고 명확한 벤치마크 과제와 공개 인프라를 제시하여 커뮤니티 기반 모델 개발을 촉진하는 핵심 기여이나, 단순화된 모델 가정이 실제 촉매 응용으로의 전이 시 한계가 있을 수 있음.
Predicting research trends with semantic and neural networks with an application in quantum physics
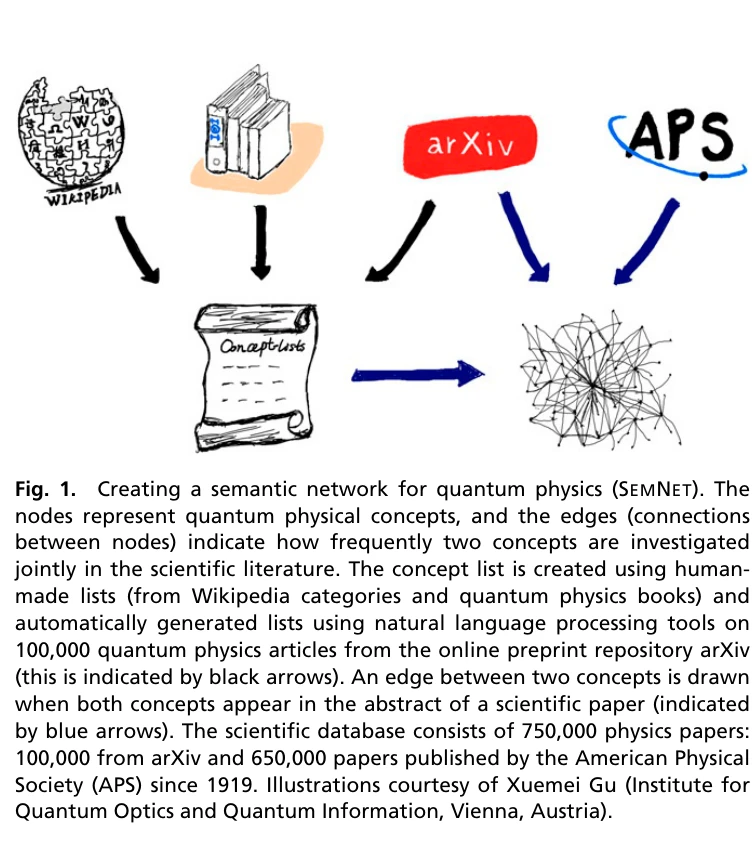
Fig. 1.
 *Fig. 1.* 750,000개의 과학논문을 기반으로 시맨틱 네트워크(SEMNET)를 구축하여 양자물리학의 미래 연구 동향을 예측하고 혁신적인 연구 아이디어를 제안하는 방법론을 제시한다.
본 논문은 대규모 과학문헌으로부터 시맨틱 네트워크를 구축하고 신경망과 네트워크 이론을 결합하여 미래 연구 동향 예측 및 혁신적 아이디어 제안이라는 새로운 접근을 제시하는 의미 있는 연구이다. 양자물리학이라는 급속히 성장하는 분야에 적용하여 실용성을 입증했으나, 개념 추출 정확성 및 장기 예측 능력 개선을 통한 보완이 필요하다.
Quantifying large language model usage in scientific papers
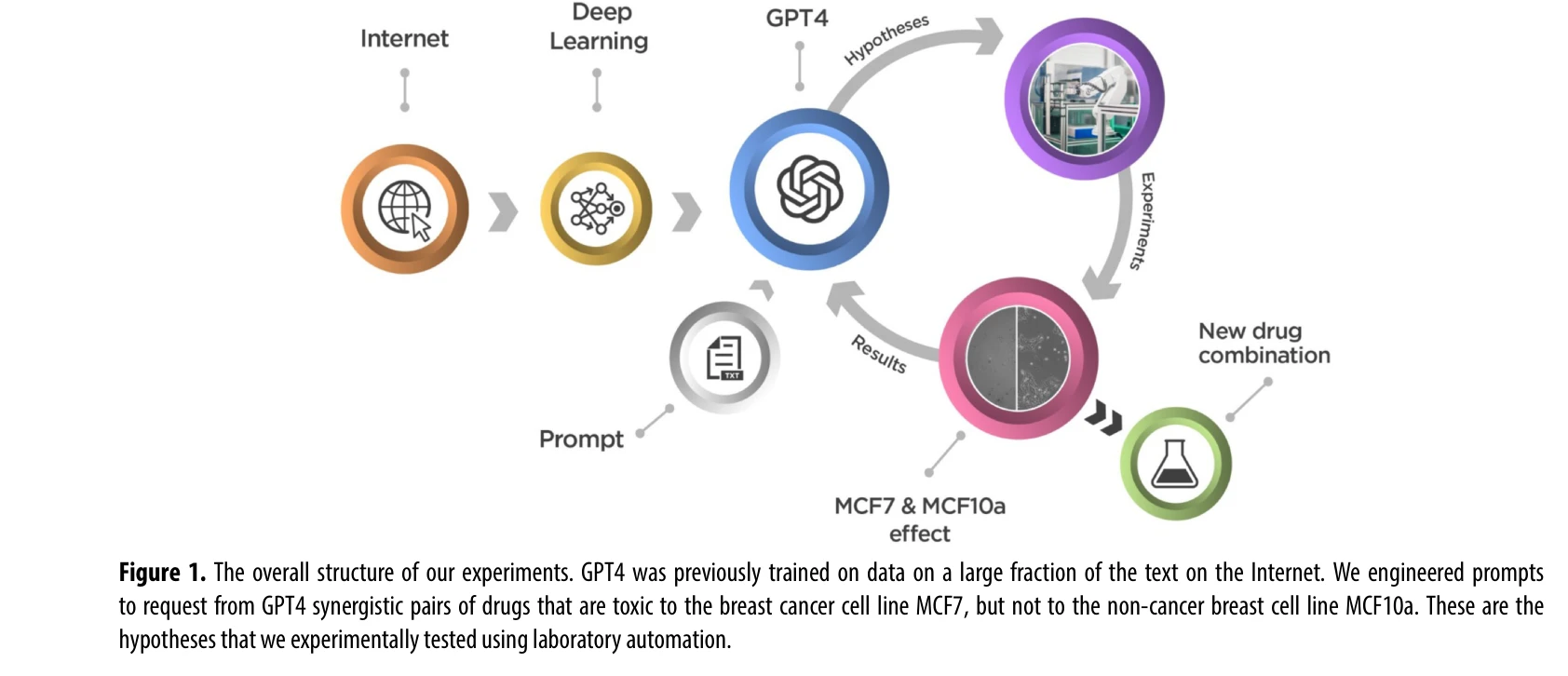
Figure 1. The overall structure of our experiments. GPT4 was previously trained on data on a large fraction of the text
 *Figure 1. The overall structure of our experiments. GPT4 was previously trained on data on a large fraction of the text * GPT-4를 사용하여 유방암 치료를 위한 신약 조합을 가설로 생성하고 실험실에서 검증한 결과, 12개 중 3개의 조합이 양성 대조군을 초과하는 시너지 효과를 보였으며, 반복 실험에서 4개 중 3개가 추가로 확인되었다.
본 논문은 LLM의 할루시네이션을 과학적 창의성의 원천으로 재정의하고 실험적 검증으로 입증한 혁신적 연구이다. 신약 개발의 AI-인간-실험 협업 모델을 제시하며, 재현 가능성과 확장성 강화가 필요하다.
REFORMS: Consensus-based Recommendations for Machine-learning-based Science
기계학습 기반 과학 연구의 타당성, 재현성, 일반화 가능성 문제를 해결하기 위해 32개 항목으로 구성된 REFORMS 체크리스트를 개발하고, 8개 모듈별 상세 가이드라인을 제시한 합의 기반 권장사항.
본 논문은 ML 기반 과학의 재현성 위기를 해결하기 위해 다학제 전문가 합의를 바탕으로 개발한 REFORMS 체크리스트를 제시하여, 과학 커뮤니티에서 ML 도입의 신뢰성을 높이는 실질적이고 광범위하게 적용 가능한 도구를 제공한다.
AI-Driven Automation Can Become the Foundation of Next-Era Science of Science Research
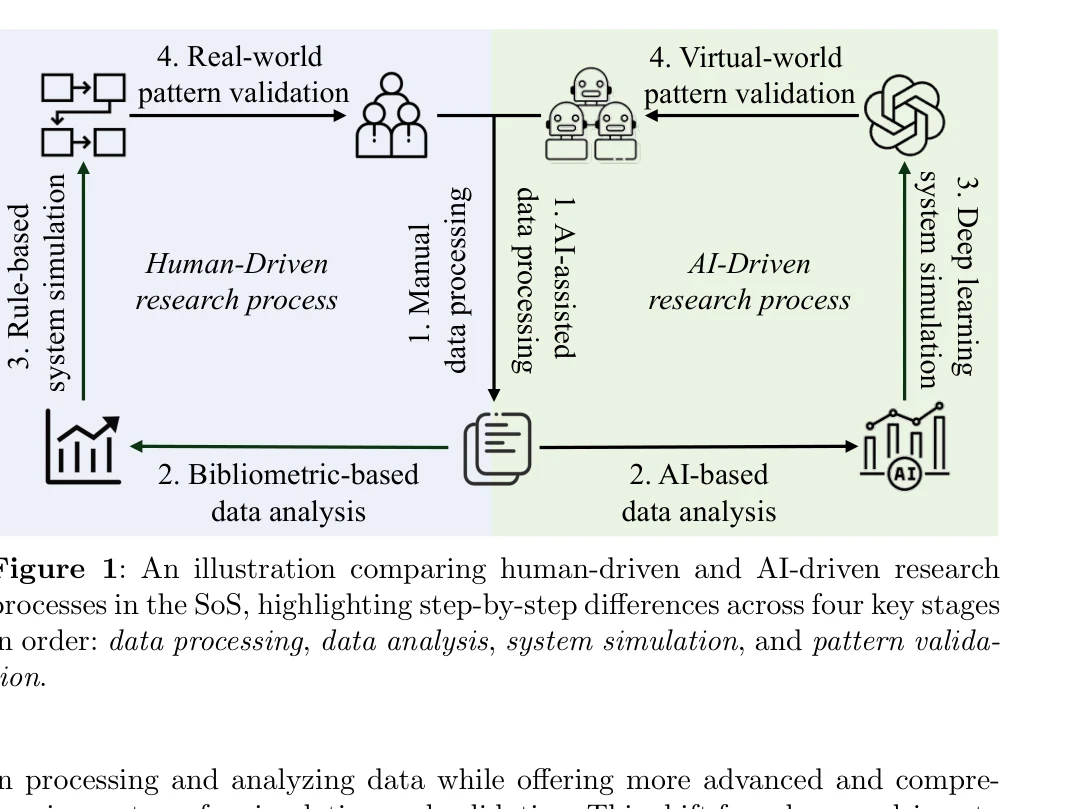
Figure 1: An illustration comparing human-driven and AI-driven research
 *Figure 1: An illustration comparing human-driven and AI-driven research* 본 논문은 과학의 과학(Science of Science, SoS) 연구에 AI 기반 자동화를 도입하여 대규모 연구 패턴 발견을 가능하게 하는 AI4SoS 프레임워크를 제시한다. 전통적인 통계 방법을 넘어 머신러닝과 멀티에이전트 시스템을 활용하여 과학 생태계의 복잡성을 자동으로 분석하고 시뮬레이션한다.
본 논문은 과학의 과학 연구에 AI를 체계적으로 통합하는 AI4SoS라는 새로운 학문 영역을 제안하고, 5단계 자동화 계층으로 명확한 로드맵을 제시하여 큰 개념적 기여를 한다. 다만 제시된 멀티에이전트 시스템은 예시 수준에 머물러 있으며, 실제 검증과 평가 체계가 더욱 강화될 필요가 있다.
Bridging the gap between science and society: Mapping libraries' strategies for engaging in the research impact process through semantic analysis

Figure 1. Actors in the process of generating scientific research impact.
 *Figure 4. Research workflow diagram.* 본 연구는 REF(Research Excellence Framework) 데이터 465건을 LLM과 BERTopic 의미분석을 통해 분석하여 과학-사회 간 지식 전달에서 도서관의 5가지 핵심 전략을 규명했다.
본 연구는 LLM과 의미분석을 결합한 혁신적 방법론으로 도서관의 연구영향 기여 전략을 체계적으로 규명한 높은 가치의 실증 연구이다. 다만 지역적 일반화 한계와 도서관 유형별 세분화 분석 부재는 향후 보완이 필요하다.
Do Large Language Models Reduce Research Novelty? Evidence from Information Systems Journals
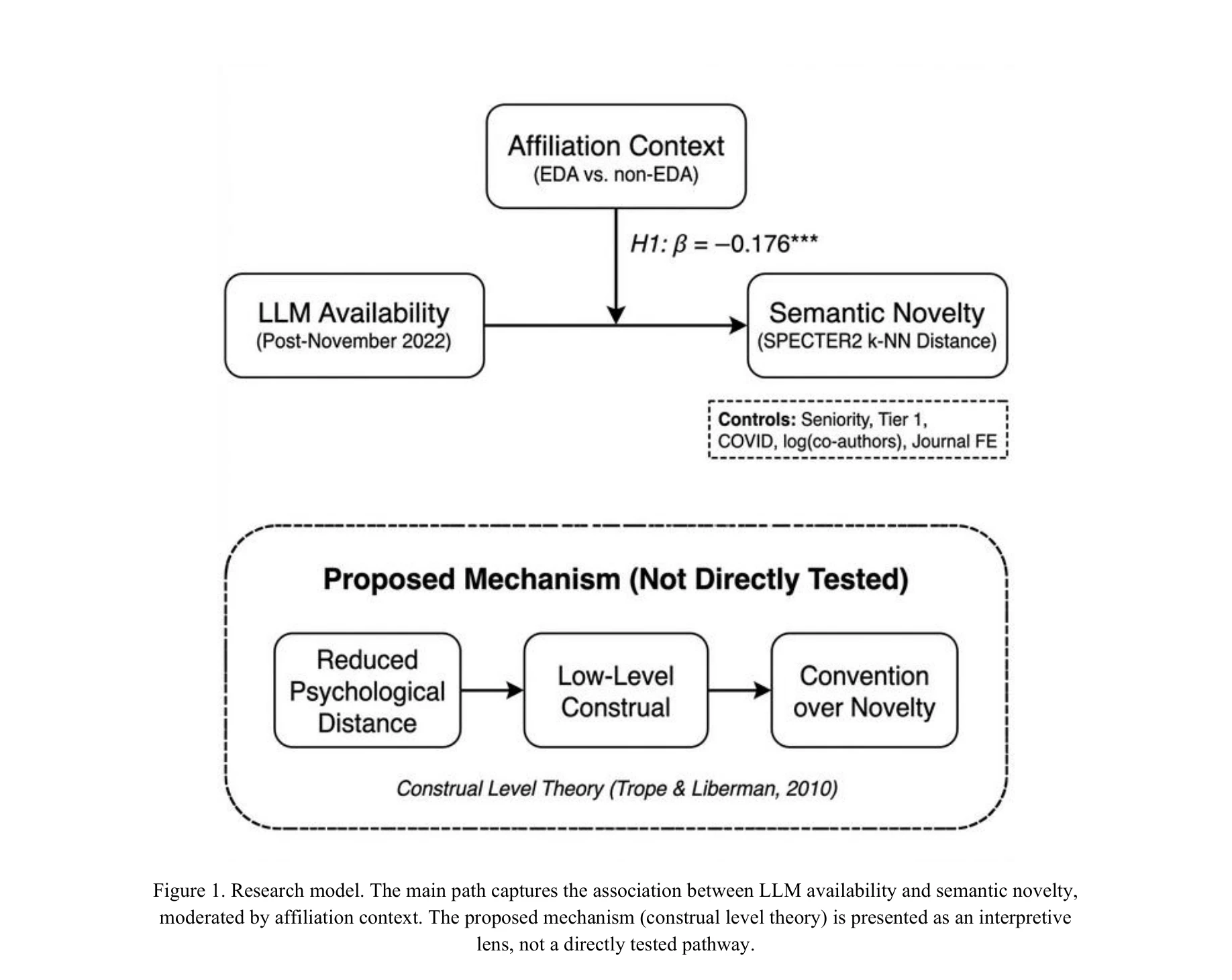
Figure 1. Research model. The main path captures the association between LLM availability and semantic novelty,
 *Figure 2. Event study coefficients for Post x Non-EDA interaction, relative to 2022. Pre-treatment coefficients* ChatGPT 출시 이후 대언어모델(LLM)이 연구 생산성을 높였지만, 의미론적 참신성(semantic novelty)은 감소했으며, 특히 영어 비주류국 소속 저자들에게서 더욱 뚜렷한 경향이 나타났다.
LLM의 생산성 이득이 지적 다양성 감소와 동반되는 현상을 최초로 실증적으로 입증한 중요한 연구로, 특히 저자 집단 간 이질적 효과를 통해 기술의 불균형적 영향을 드러냈으며, 구성수준이론이라는 심리학적 설명으로 AI 정책의 중요한 함의를 제공한다.
Forecasting high-impact research topics via machine learning on evolving knowledge graphs
21백만 개의 과학논문으로부터 구축한 진화하는 지식그래프(evolving knowledge graph)와 머신러닝을 활용하여, 아직 발표되지 않은 새로운 연구 아이디어의 미래 영향력(impact)을 예측하는 기법을 제시한다.
과학 지식의 빠른 성장 속에서 미발표 연구의 미래 영향력을 조기에 예측하는 혁신적 접근법을 제시하며, 대규모 진화 지식그래프와 머신러닝의 결합으로 높은 예측 성능을 달성했다. 다만 도메인 특화성, 영향력 지표의 제한성, 해석 가능성 부족 등의 개선이 필요하며, 향후 과학 AI 어시스턴트 개발의 중요한 토대가 될 수 있다.
Forecasting the future of artificial intelligence with machine learning-based link prediction in an exponentially growing knowledge network
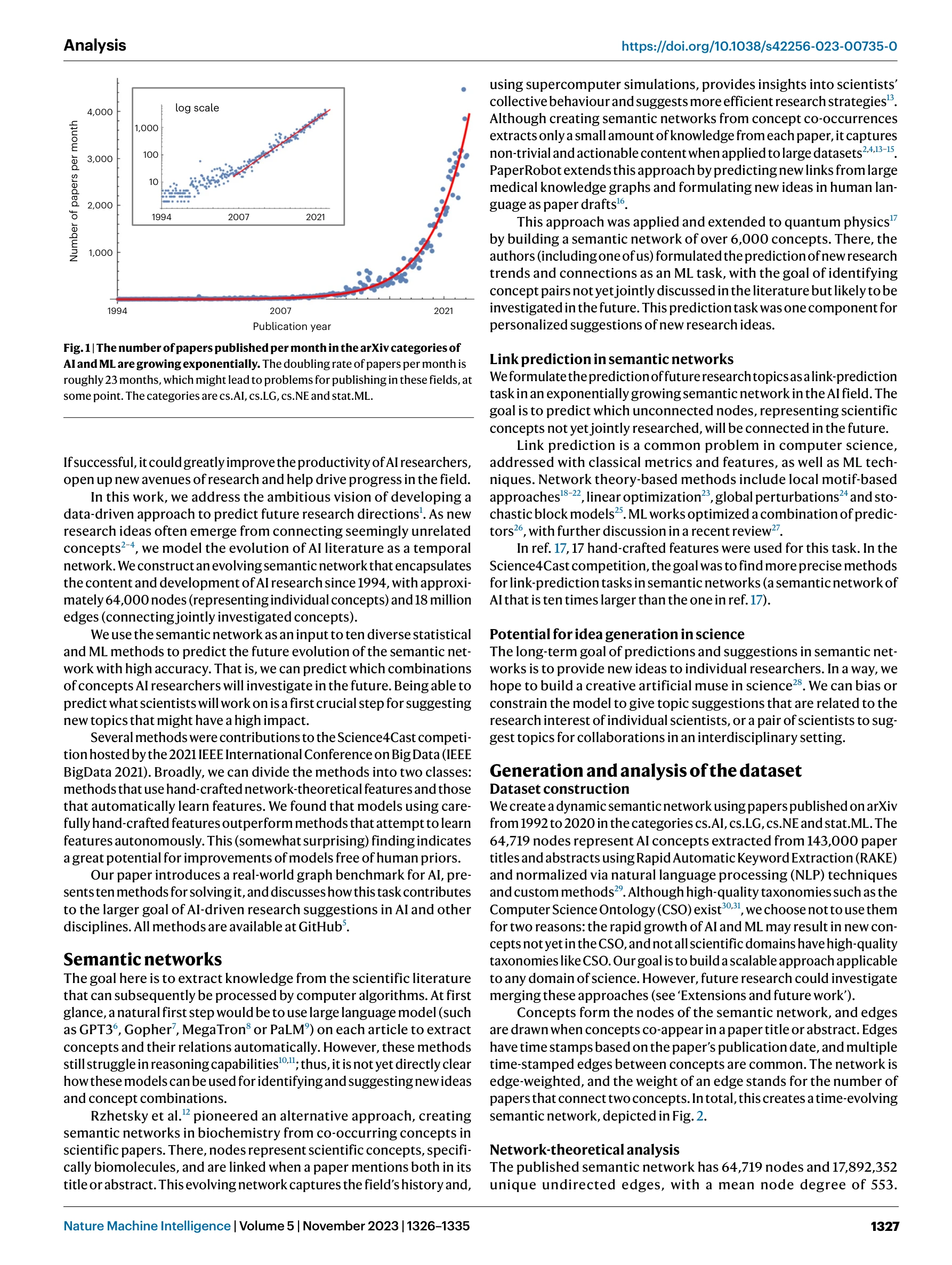
Fig. 1 | The number of papers published per month in the arXiv categories of
 *Fig. 2 | From arXiv to Science4Cast. Utilizing 143,000 AI and ML papers on* 143,000개의 AI 논문으로부터 64,000개 개념 노드를 가진 의미 네트워크(semantic network)를 구축하고, 머신러닝 기반 링크 예측(link prediction)을 통해 미래의 AI 연구 방향을 예측한다.
이 논문은 대규모 의미 네트워크에서 머신러닝 기반 링크 예측을 통해 미래 AI 연구 방향을 예측하는 실용적이고 확장 가능한 접근법을 제시하며, 수작업 특성의 우월성이라는 반직관적이지만 중요한 발견을 제공한다. 실제 과학 생산성 향상을 위한 연구 제안 도구 개발의 중요한 기초 연구이다.
Identifying interdisciplinary emergence in the science of science: combination of network analysis and BERTopic

Fig. 1 Overall research process. The overall research process is performed
 *Fig. 4 Process of BERTopic modeling. The process of BERTopic modeling* 이 연구는 BERTopic 임베딩 토픽 모델링과 네트워크 분석을 결합하여 과학 간행물 메타데이터에서 학제간 지식 재조합을 통해 새로운 과학의 출현을 식별하는 방법을 제안한다.
이 연구는 네트워크 분석과 임베딩 토픽 모델링을 창의적으로 결합하여 학제간 과학의 출현을 식별하는 새로운 방법론을 제시하며, 과학 정책 수립과 혁신 예측에 실질적 가치를 제공한다. 데이터 기반 접근과 질적 검증을 통해 방법론의 신뢰성을 입증했으나, 데이터 범위 확대와 추가적 타당성 검증이 필요하다.
Information Pathways in Online Science Communication: The Role of Platform Actors and News Media
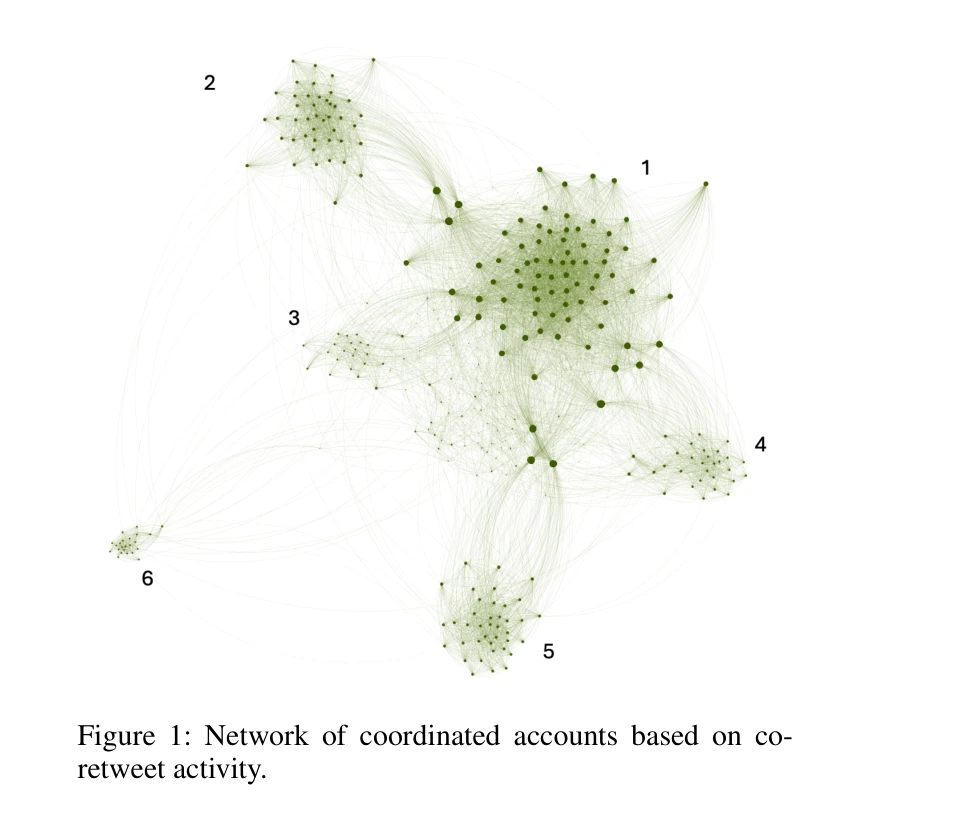
Figure 1: Network of coordinated accounts based on co-
 *Figure 1: Network of coordinated accounts based on co-* COVID-19 팬데믹을 사례로 1.24M 트윗과 211k 뉴스 기사를 분석하여 과학 논문의 정보 경로(information pathways)를 추적하고, 소셜 미디어 슈퍼스프레더(superspreaders)와 뉴스 미디어 간의 상호작용 구조를 규명한 연구이다.
이 논문은 COVID-19 과학 소통 생태계를 다층적으로 분석하여 소셜 미디어 슈퍼스프레더와 뉴스 미디어 간의 상호 강화 구조와 부실정보 증폭 메커니즘을 규명함으로써, 온라인 정보 생태계에 대한 혁신적 이해를 제공한다. 다만 인과관계 미확립과 사례 제한성에 대해 추가 검증이 필요하다.
Mapping Knowledge: Topic Analysis of Science Locates Researchers in Disciplinary Landscape
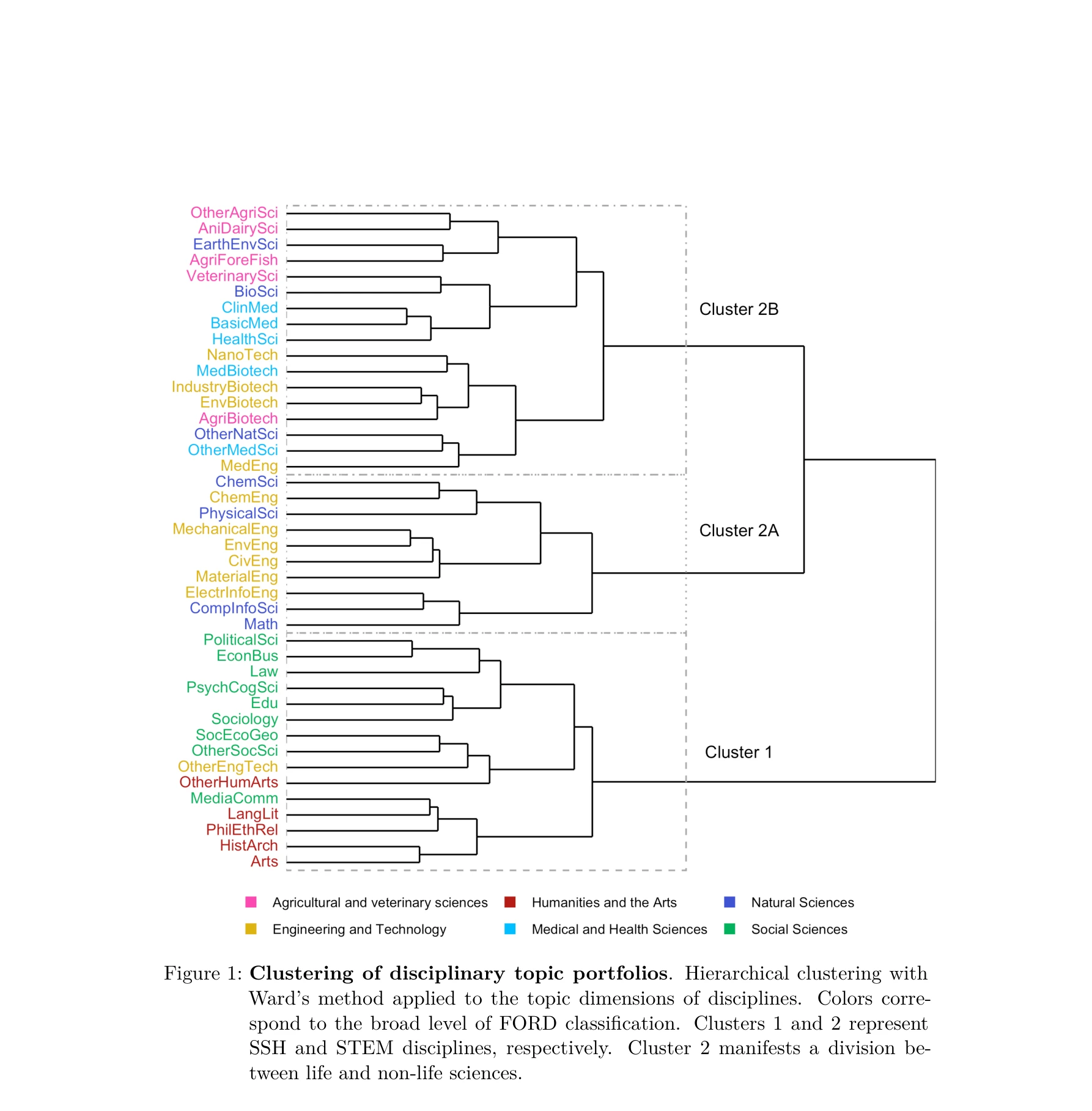
Figure 1: Clustering of disciplinary topic portfolios. Hierarchical clustering with
 *Figure 2: Cloud of topics in the knowledge space. Scores of topics on principal* 이 연구는 토픽 모델링, 구성 데이터 분석, 기하학적 데이터 분석을 결합하여 과학자들을 학문 분야 내에서 위치시키는 새로운 인식론적 좌표 체계를 제시한다. 체코 국가 연구 데이터셋(1,039,577개 출판물, 118,560명 저자)을 활용하여 지식과 지식 생산자의 간격을 해소한다.
이 논문은 과학 지도 작성의 두 전통을 성공적으로 통합하며, 토픽 모델링과 기하학적 데이터 분석의 창의적 결합을 통해 연구자들을 인식론적 좌표계에 위치시키는 혁신적 방법론을 제시한다. 과학 정책 수립과 학문 분야 분석에 즉시 적용 가능한 실질적 가치가 높다.
Mapping the changing structure of science through diachronic periodical embeddings
학술지(periodical)의 시간에 따른 의미론적 변화를 추적하는 '시간 경과 임베딩(diachronic embedding)' 방법을 개발하여 과학의 구조 진화를 정량화한다.
시간 경과 임베딩을 통해 과학 진화를 정량적으로 추적하는 창의적 방법론을 제시하며, 광범위한 검증과 신흥 주제 발견으로 과학의 학문 구조 연구에 중대한 기여를 한다. 다만 데이터 범위 명시와 다양한 임베딩 방법 비교가 보강되면 더욱 강력해질 것이다.
Open Datasets in Learning Analytics: Trends, Challenges, and Best PRACTICE
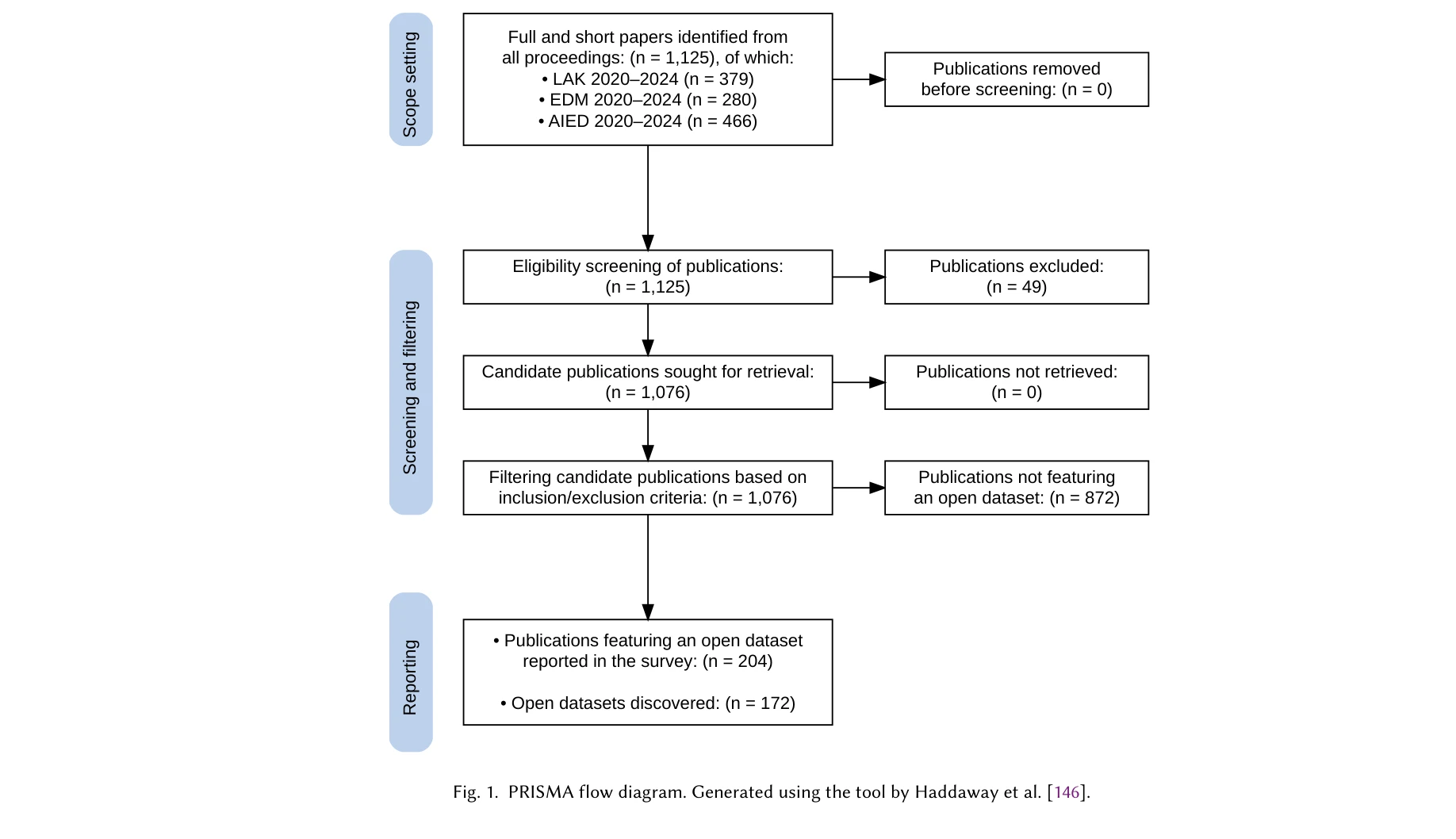
Fig. 1. PRISMA flow diagram. Generated using the tool by Haddaway et al. [146].
 *Fig. 2. Distributions of dataset frequency across educational topics and levels of students.* 본 논문은 학습분석(Learning Analytics), 교육데이터마이닝(Educational Data Mining), 교육용 AI의 세 분야에서 공개 데이터셋의 현황을 파악하고, 데이터 공유 모범 사례를 제시하는 체계적 조사 연구이다.
본 논문은 학습분석 커뮤니티의 공개 데이터 현황에 대한 가장 포괄적이고 최신의 체계적 조사 연구이며, 실질적인 PRACTICE 지침 제공과 신규 데이터셋 인벤토리 공개를 통해 학습분석 분야의 개방 과학 실천을 촉진하는 중요한 기여를 한다.
OpenAlex in focus: Metadata quality of publication type and language fields in an open peer review corpus
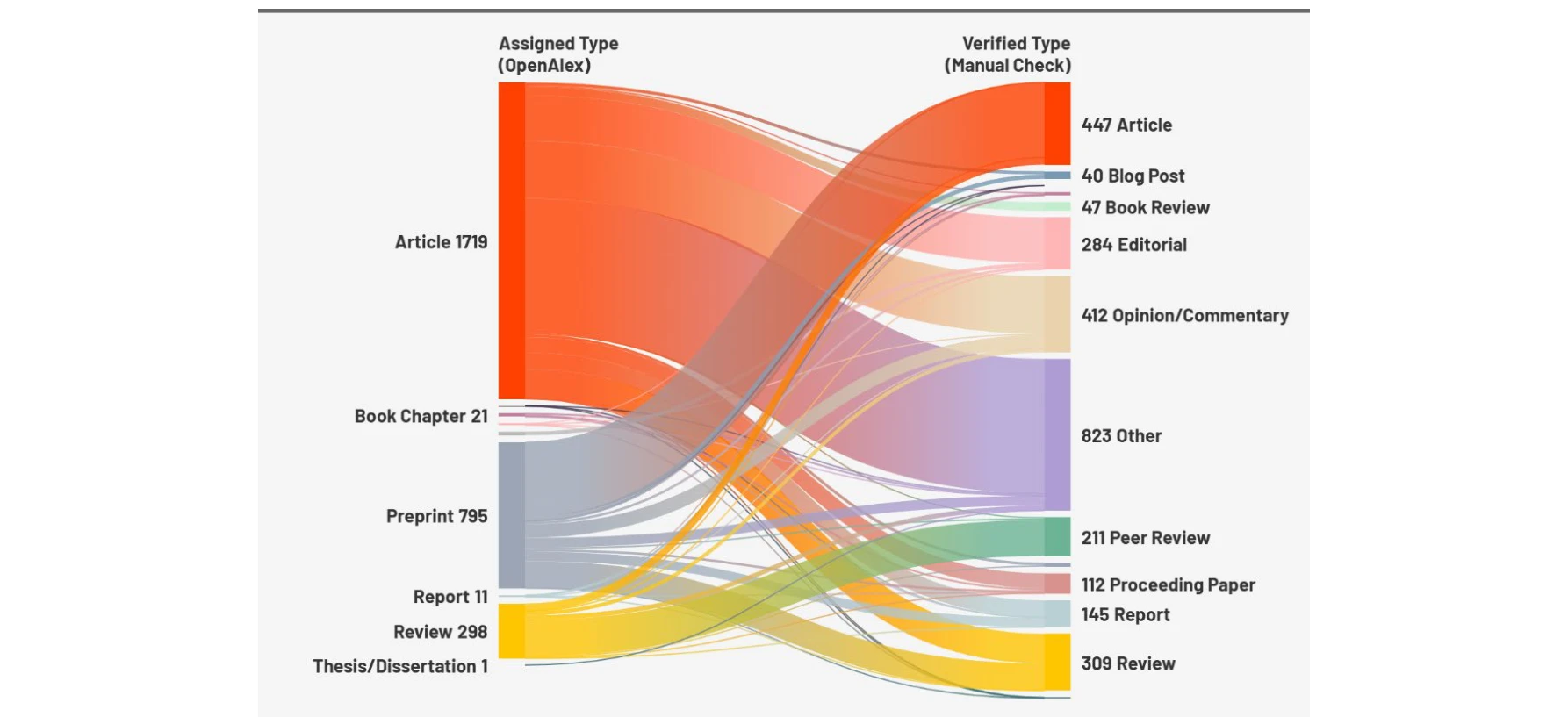
Figure 1 illustrates the differences between the Assigned Type (OpenAlex) and the Verified Type
 *Figure 1 illustrates the differences between the Assigned Type (OpenAlex) and the Verified Type* OpenAlex의 메타데이터 품질을 문헌 유형(publication type)과 언어(language) 필드 중심으로 분석하여, 6,640개 오픈 피어 리뷰 관련 논문에서 43%의 유형 불일치와 3.3%의 언어 불일치를 발견했다.
본 연구는 OpenAlex의 메타데이터 품질 문제를 구체적이고 정량적으로 입증함으로써, 해당 데이터베이스 사용 전 체계적 정제의 필요성을 강조한다. 문헌계량 및 오픈 사이언스 연구 커뮤니티에 실질적인 경고 신호를 제공하며, 오픈 인프라의 신뢰성 확보를 위한 개선 방향을 시사한다.
Category Overview
Science Policy & Funding 카테고리는 과학 정책 결정과 연구비 배분이 과학 생태계에 미치는 영향을 종합적으로 분석하는 분야이다. 팬데믹 시기 정책 변화와 과학 연구의 상호작용 [945], 과학 투자의 광범위한 파급효과 시각화 [964], 학제간 연구에 대한 학문 분야별 지원 현황 [975] 등을 다룬다. 또한 글로벌 과학 펀딩(funding)과 연구 성과의 연관성 [980], 주제 수준의 연구비 배분과 산출물 분석 [983], 미국의 정치적 성향에 따른 과학 펀딩 격차 [996] 같은 현안들을 포괄한다. 이러한 논문들은 과학 정책이 어떻게 형성되고 자원이 어떻게 배분되는지 이해하며, 더 효율적이고 공정한 과학 투자 체계를 구축하는 데 기여한다. Science Policy & Funding은 과학과 사회의 인터페이스(interface)에서 발생하는 구조적, 제도적 문제들을 조명하는 중요한 연구 영역이다.
⚠ 갭: 연구비 효과성 측정을 위한 장기적이고 다차원적인 평가 체계가 부족하다
🏛 정책: 연구비 지원의 질적 효과 제고를 위한 평가 기준 개선과 지원 방식 다양화가 필요하다
Scientific prize network predicts who pushes the boundaries of science
Fig. 1A shows the sharp annual increase in the number of prizes relative to the growth of
 *Fig. 2 The exponential distribution of scientific prizewinning. Plot and inset show* 3,000개 이상의 과학상과 10,455명의 수상자 데이터를 분석하여 과학상 네트워크가 과학의 경계를 넓히는 과학자들을 예측할 수 있음을 보여준다.
과학상 네트워크 분석을 통해 과학의 엘리트 집중화, 학제적 연결, 계층적 구조를 최초로 정량화하고 미래의 영향력 있는 과학자를 예측하는 프레임워크를 제시한 중요한 연구이다. 대규모 데이터와 혁신적 분석 방법론으로 과학 사회학 분야에 유의미한 기여를 한다.
Scientific production in the era of large language models
Fig. 1 shows that LLM adoption is associated with a large increase in researchers’ scientific output
 *Fig. 1 shows that LLM adoption is associated with a large increase in researchers’ scientific output* 대규모 언어모델(LLM)이 과학 논문 작성에 광범위하게 도입되면서 연구 생산성은 증가했지만, 글의 복잡성과 논문 품질 간의 관계가 역전되어 언어적으로는 정교하지만 실질적으로는 부실한 원고들이 증가하고 있다.
본 연구는 LLM의 과학 생산에 대한 거시적 영향을 최초로 체계적이고 대규모로 실증한 획기적 연구로, 단순 생산성 증가 너머로 과학 품질 평가 기준의 근본적 변화를 요구하는 중요한 발견을 제시한다.
SciSciGPT: advancing human–AI collaboration in the science of science
Fig. 1 | SciSciGPT system architecture. A diagram illustrating the modular
 *Fig. 1 | SciSciGPT system architecture. A diagram illustrating the modular* SciSciGPT는 대규모 언어모델(LLM)을 기반으로 한 오픈소스 AI 협력자로, 과학 메타과학(science of science) 분야의 복잡한 연구 워크플로우를 자동화하고 재현성을 향상시킨다.
SciSciGPT는 LLM 에이전트 기반 AI 협력자의 실질적 가능성을 메타과학 도메인에서 입증한 중요한 프로토타입이며, 제안된 성숙도 모델은 향후 AI 연구 도구 개발을 위한 일반화된 프레임워크를 제공한다. 투명성 및 윤리 문제 해결과 함께 다양한 과학 분야로의 확장이 이루어진다면 과학 연구의 패러다임 전환을 가능하게 할 것으로 기대된다.
SciSciNet: A large-scale open data lake for the science of science research
Fig. 1 The entity relationship diagram of SciSciNet. SciSciNet includes “SciSciNet_Papers” as the main data
 *Fig. 1 The entity relationship diagram of SciSciNet. SciSciNet includes “SciSciNet_Papers” as the main data* 134M개 이상의 과학 논문과 펀딩, 특허, 임상시험 등 외부 연계 데이터를 통합한 대규모 오픈 데이터 레이크(SciSciNet)를 제시하여, 과학 연구의 장벽을 낮추고 재현성을 향상시킨다.
SciSciNet은 과학 연구에 대한 패러다임적 자원으로, 134M개 논문과 다층 연계 데이터를 통합하여 과학 메타 연구의 진입 장벽을 획기적으로 낮춘다. 투명한 문서화와 표준화된 지표 제공으로 재현성을 강화하며, 개방형 구조로 커뮤니티의 지속적 확장을 가능하게 한다.
Software survey: VOSviewer, a computer program for bibliometric mapping
 *Fig. 3 Screenshot of the main window of VOSviewer* VOSviewer는 bibliometric mapping을 위한 자유 소프트웨어로, 특히 대규모 bibliometric map의 시각화(visualization)에 중점을 두고 개발되었으며 VOS mapping technique을 기반으로 한다.
VOSviewer는 bibliometric mapping의 시각화라는 소외된 영역에 집중하여 대규모 map의 해석성을 획기적으로 개선한 실질적으로 유용한 도구이며, 자유 소프트웨어로 제공되어 연구 커뮤니티에 큰 기여를 하고 있다.
Systemic Gendered Citation Imbalance in Computer Science: Evidence from Conferences and Journals
Figure 1: Time-varying demographics of published papers by gender category in computer science.
 *Figure 2: Gender imbalance in citations made by papers in computer science. Panels (a), (d),* 컴퓨터과학 분야에서 여성 저자 논문이 예상보다 적은 인용을 받는 성별 기반 인용 불균형을 실증적으로 규명하고, 이러한 현상이 회의 논문에서 저널 논문보다 더 심각함을 보여준다.
컴퓨터과학에서의 성별 기반 인용 불균형을 최초로 체계적으로 규명하고 회의-저널 간 차이를 밝혀낸 중요한 연구로, 학문의 형평성 증진을 위한 실질적 근거를 제공한다. 다만 이진 성별 분류와 자동 할당의 한계를 보완하고 인과관계를 더욱 엄밀히 규명하는 후속 연구가 필요하다.
Tenure and research trajectories
Fig. 1. Tenure and publication rates. (A) Articles published per year, averaged across researchers for each year befor
 *Fig. 1. Tenure and publication rates. (A) Articles published per year, averaged across researchers for each year befor* 12,611명의 미국 학자를 7개 데이터소스에서 추적하여, 종신재직권(tenure) 획득 전후 연구 생산성과 창의성의 변화를 대규모로 실증 분석한 연구이다. 종신재직권 획득 직전에 논문 발표가 최고조에 달하고, 획득 후 분야별로 상이한 궤적을 보이며, 창의성은 증가하나 영향력은 감소하는 현상을 발견했다.
이 논문은 미국 종신재직권 제도가 연구 생산성과 창의성에 미치는 영향을 대규모 실증 데이터로 처음 체계적으로 규명한 고도의 학술적 기여이며, 분야별 이질성 발견과 방법론의 엄밀성(인과성 규명, 경력 나이 통제)이 뛰어나 Science of Science, 학계 정책 입안, 학자 경력 이해에 중대한 함의를 제공한다.
The altering landscape of US–China science collaboration: from convergence to divergence
Fig. 1 Changes in the mutual distance between the four parties over time. The four parties included in the analysis are
 *Fig. 1 Changes in the mutual distance between the four parties over time. The four parties included in the analysis are * 미국과 중국의 과학 협력이 2000년대 이후 급속한 수렴에서 최근 발산으로 전환되는 역동적 패턴을 보이며, 이는 글로벌 과학 협력의 일반적 수렴 추세와 대조된다.
본 논문은 미국-중국 과학 협력의 역동적 변화를 대규모 데이터로 처음 입증한 중요한 연구로, 글로벌 과학 정책과 외교에 실질적 근거를 제공한다. 다만 인과관계 규명과 최신 데이터 포함을 위한 후속 연구가 필요하다.
A Survey of AI Scientists
Figure 1:
 *Figure 1:* AI 과학자(AI Scientist) 시스템의 문헌 조사로, 자동화된 과학 발견의 완전한 파이프라인을 6단계 방법론 프레임워크를 통해 체계적으로 분류하고 분석한다.
이 서베이는 급속히 성장하는 AI 과학자 분야를 처음으로 체계적이고 포괄적으로 정리한 중요한 작업으로, 6단계 프레임워크를 통해 방법론적 원칙을 명확히 하고 미래 연구의 로드맵을 제시한다. 다만 정량적 성능 비교와 크로스-도메인 일반화에 대한 실증적 분석이 강화되면 더욱 완성도 있는 리뷰가 될 수 있다.
Accelerating science with human-aware artificial intelligence
Figure 1 illustrates a modular and scalable Artificial Orches-
 *Figure 1 illustrates a modular and scalable Artificial Orches-* AI 기반 자동화 약물 발견을 위해 복잡한 실험실 워크플로우를 통합 관리하는 Artificial 오케스트레이션 플랫폼을 제시한다. 데이터 사일로(data silos) 문제를 해결하고 NVIDIA BioNeMo와 같은 AI 모델을 자동화된 실험 프로세스에 통합한다.
본 논문은 자동화 약물 발견의 현실적 도전과제들(데이터 사일로, 워크플로우 복잡성, AI 통합)을 종합적으로 해결하는 실용적인 오케스트레이션 플랫폼을 제시하며, 모듈식 아키텍처와 다중 프로토콜 지원으로 확장성이 우수하다. 다만 드라이 랩 사례만 제시되었으므로 웻 랩 검증과 대규모 실제 운영 환경에서의 성능 평가가 후속되어야 한다.
Artificial intelligence and illusions of understanding in scientific research
Figure 1: The mainstream processes and categories of AI4Research, which can be divided into five key areas:
 *Figure 2: The taxonomy of AI in research (AI4Research) is categorized into five key areas. Each area is* 본 논문은 AI4Research라는 체계적 분류법을 제시하여 과학 연구의 5가지 주요 작업(과학 이해, 학술 조사, 과학 발견, 학술 저술, 동료 평가)에 AI를 적용하는 현황을 종합적으로 조사한 학술 설문 논문이다.
본 논문은 AI4Research 분야의 첫 종합 설문으로서 5단계 파이프라인 분류, 다양한 학제간 응용 사례 수집, 풍부한 오픈 리소스 제공이라는 측면에서 높은 참고 가치가 있다. 다만 제목과 달리 'illusions of understanding'에 대한 비판적 분석이 약하고, 자동화 시스템의 과학적 엄밀성 보장 방안이 구체적이지 않은 점은 개선이 필요하다.
Breaking the gatekeepers: how AI will revolutionize scientific funding
AI 기술이 생물의학 연구비 배분 시스템의 기득권 구조를 와해시켜, 초기경력 과학자와 혁신적 아이디어에 더 공평한 기회를 제공할 수 있음을 주장한다.
이 논문은 과학 자금 배분 시스템의 구조적 결함을 설득력 있게 분석하고, AI 분야와의 대조를 통해 제도적 개선의 필요성을 강하게 주장한다. 다만 AI 기반 해결책의 기술적 구체화와 현실적 실행 방안이 부족하여, 정책 개혁의 첫 단계 진단으로서의 가치는 높으나 실제 구현으로 나아가기 위한 추가 연구가 절실하다.
An empirical analysis of open access citation advantages in library and information science
Figure 1. Research framework
 *Figure 5. OA vs non-OA Publication & Citation Comparison* 본 연구는 Web of Science 데이터베이스의 109,759개 도서관정보학(LIS) 학술논문(2001-2024)을 분석하여 오픈액세스(Open Access, OA) 논문의 인용 이점이 OA 유형, 학문분야, 출판년도에 따라 조건부로 나타남을 실증적으로 규명했다.
본 연구는 LIS 분야에서 부족했던 대규모 실증적 OA 연구로서, 의학·생명과학에서 관찰된 OA 인용 이점이 LIS에서는 시간 경과에 따라 소멸되고 OA 유형에 따라 조건부로 작동함을 처음 체계적으로 입증하여 학술커뮤니케이션 정책 수립에 중요한 실증적 근거를 제공한다.
Bridging the gap between science and society: Mapping libraries' strategies for engaging in the research impact process through semantic analysis
Figure 1. Actors in the process of generating scientific research impact.
 *Figure 4. Research workflow diagram.* 본 연구는 REF(Research Excellence Framework) 데이터 465건을 LLM과 BERTopic 의미분석을 통해 분석하여 과학-사회 간 지식 전달에서 도서관의 5가지 핵심 전략을 규명했다.
본 연구는 LLM과 의미분석을 결합한 혁신적 방법론으로 도서관의 연구영향 기여 전략을 체계적으로 규명한 높은 가치의 실증 연구이다. 다만 지역적 일반화 한계와 도서관 유형별 세분화 분석 부재는 향후 보완이 필요하다.
Coevolution of policy and science during the pandemic
COVID-19 팬데믹 기간 정책 문서와 과학 논문의 상호작용을 대규모 데이터베이스로 분석하여, 정책이 최신의 동료검증 과학을 실제로 활용하고 있음을 보여준다.
본 연구는 대규모 데이터 통합을 통해 과학-정책 연결에 관한 오래된 회의론을 실증적으로 반박하며, 팬데믹 대응에서 정책이 실제로 최신 동료검증 과학을 우선적으로 활용함을 명확히 보여준다. 다만 인용의 실제 영향력과 정책 효과성과의 연계 분석이 추가되면 더욱 설득력 있을 것이다.
Early-career setback and future career impact
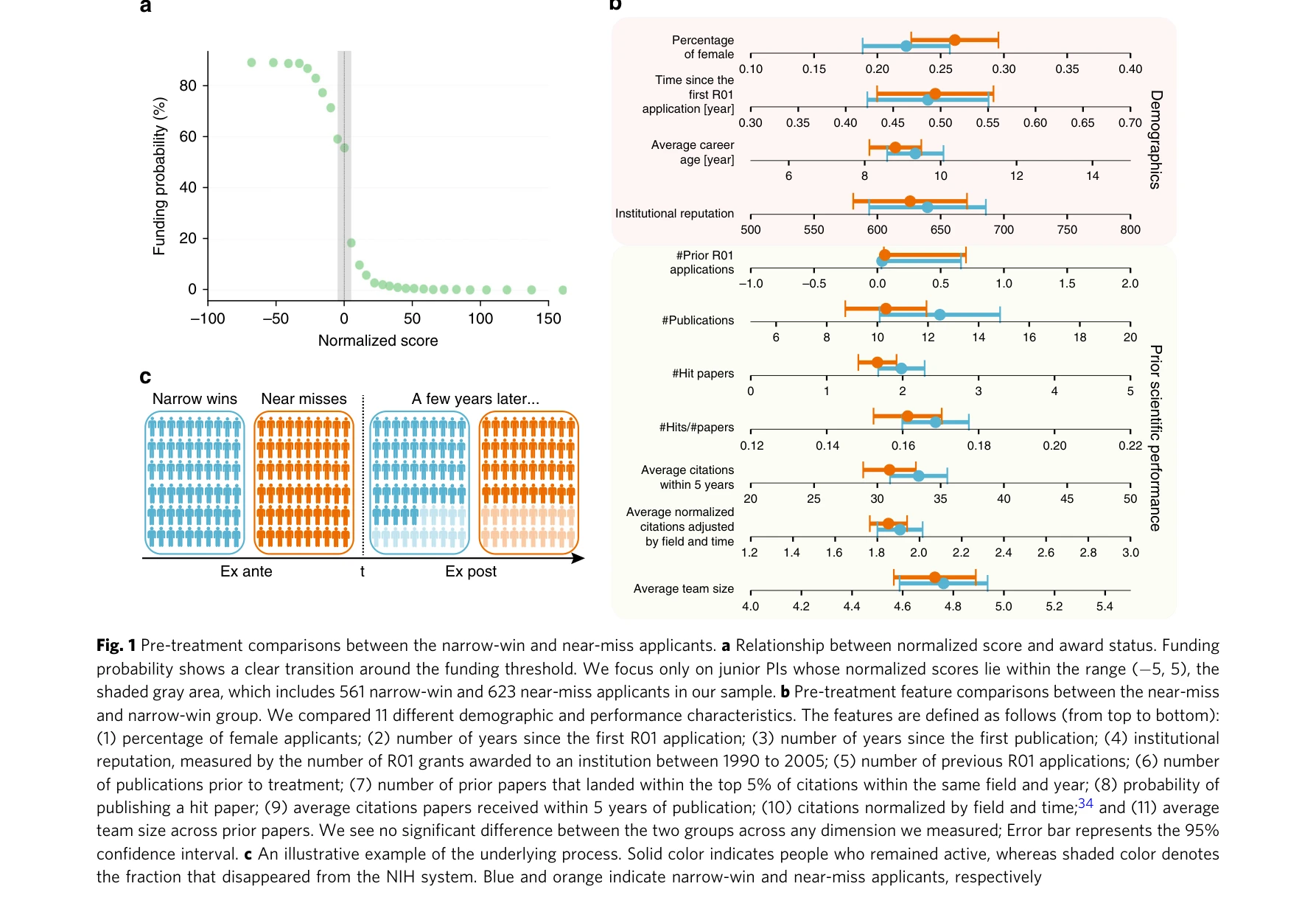
Fig. 1 Pre-treatment comparisons between the narrow-win and near-miss applicants. a Relationship between normalized scor
 *Fig. 2 Comparing future career outcome between near misses (orange) and narrow wins (blue). a The average number of publ* NIH R01 지원자의 초기 경력 좌절(자금 지원 탈락)이 장기 경력에 미치는 영향을 분석한 결과, 생존한 연구자들은 초기 좌절 후 더 높은 연구 성과를 달성하는 것으로 나타났다.
회귀불연속설계를 통해 초기 경력 좌절과 장기 연구 성과의 인과관계를 엄밀하게 규명한 점에서 높은 방법론적 엄밀성을 보유하며, NIH 전체 데이터 활용과 10년 추적을 통해 신뢰할 수 있는 실증 증거를 제시한 우수한 연구이다.
Funding the Frontier: Visualizing the Broad Impact of Science and Science Funding
Figure 1: The science ecosystem, from the upstream funding to the science to the broader downstream
 *Figure 1: The science ecosystem, from the upstream funding to the science to the broader downstream* 과학 펀딩의 다차원적 영향을 시각적으로 분석하기 위해 700만 개 연구비, 1억 4천만 개 논문, 1억 6천만 개 특허 등을 연결한 대규모 데이터 기반 시각분석 시스템(FtF)을 개발했다.
이 논문은 Science of Science와 Visual Analytics를 결합하여 펀딩의 다차원적 사회 영향을 체계적으로 분석하는 최초의 포괄적 플랫폼을 제시했으며, 180억 규모의 이질적 네트워크 데이터 통합과 공개 웹 도구 제공을 통해 학술계뿐 아니라 정책 실무에서의 즉각적 활용 가치를 입증하는 뛰어난 연구다.
Interdisciplinary papers supported by disciplinary grants garner deep and broad scientific impact
Fig. 1. Quantifying the level of interdisciplinarity of individual publications and grants. Major publication databases
 *Fig. 3. Impact of interdisciplinary papers as a function of grant interdisciplinarity. a) Interdisciplinary papers from * 350,000개 국제 연구비 데이터를 분석한 결과, 학제간(interdisciplinary) 연구비보다 학문분야 중심(disciplinary) 연구비가 높은 영향력의 학제간 논문을 생산하는 것으로 나타났다.
학제간 연구비 지원 정책의 효과를 대규모 실증 데이터로 처음 체계적으로 검증한 중요한 연구이다. 깊은 학문기초와 학제간 혁신의 상보성을 보여주며 과학정책 입안에 직접적인 함의를 제공한다.
Linking Global Science Funding to Research Publications
 *Figure 2: Overview of the funder name disambiguation pipeline.* 전 세계 과학 펀딩 조직을 연구 논문과 연결하기 위해 740만 개의 펀딩 인정 문자열을 체계적으로 명확화하고 190만 개의 고유 펀더를 표준화된 식별자로 매핑한 대규모 데이터셋을 구축했다.
본 연구는 과학 펀딩의 글로벌 투명성과 비교 가능성을 크게 향상시키는 실질적이고 포괄적인 데이터 인프라를 제공하며, 다단계 명확화 방법론과 체계적 교차 데이터베이스 검증을 통해 과학-정책 연구의 신뢰성을 높이는 중요한 기여를 한다.
Mapping Research Funding and Outputs at the Topic Level in the Nordic Countries
북유럽 국가들의 연구 자금 지원과 출판 성과 간의 관계를 주제 수준에서 분석하여, 자금이 출판량은 증가시키지만 인용 영향도(citation impact)는 오히려 감소시키는 질-량 간 트레이드오프 현상을 발견했다.
북유럽의 연구 자금과 출판 성과 간의 관계를 주제 수준에서 체계적으로 분석한 우수한 연구로, 자금이 출판량은 증가시키지만 인용 영향도는 오히려 감소시킨다는 중요한 정책적 시사점을 제시한다. 다만 지역 한정성과 인과 메커니즘에 대한 더 깊은 분석이 필요하다.
Partisan disparities in the funding of science in the United States
1980-2020년 미국 연방정부의 과학 기금 배분을 분석한 결과, 공화당 의원들이 민주당보다 더 강력한 자금 지원을 일관되게 제공했음을 보여준다. 이는 정치적 양극화 시대에 과학 자금의 양당 협력적 특성을 강조한다.
정치와 과학 정책의 관계를 정량적으로 분석한 중요한 실증 연구로서, 50년간의 포괄적 예산 데이터를 통해 정당별 과학 자금 배분의 역사적 패턴을 처음으로 체계적으로 규명했다. 정치적 양극화 시대에 과학 자금의 양당 협력의 중요성을 강조하며 정책 입안자와 과학 공동체 모두에게 중요한 근거를 제공한다.
Category Overview
이 카테고리는 과학 연구 분야에서의 경력 발전과 인력 이동(mobility)에 관한 다양한 측면을 다룬다. [1065], [1066], [1068], [1069]는 AI 기술이 과학 연구와 학자의 경력에 미치는 영향을 조사하며, 특히 인간-중심 AI(human-aware AI)와 과학적 이해의 문제를 탐색한다. [956], [967], [970], [973]은 조기 경력 단계의 어려움, 경제 발전에 따른 학자의 국제 이동(international migration), 과학 경력의 성별 불평등(gender inequality) 추이, 그리고 기관 간 이동성(inter-institutional mobility)이 과학적 성과에 미치는 영향을 실증적으로 분석한다. 이들 연구는 현대 과학 생태계에서 기술 혁신, 인적 자본(human capital), 그리고 구조적 불평등이 어떻게 연결되어 있는지를 보여준다.
⚠ 갭: 연구자 이동성이 지역별 과학 생태계에 미치는 장기적 영향에 대한 분석이 부족하다
🏛 정책: 글로벌 인재 순환을 촉진하면서도 지역 과학 역량을 강화하는 균형있는 정책이 필요하다
A Survey of AI Scientists
Figure 1:
 *Figure 1:* AI 과학자(AI Scientist) 시스템의 문헌 조사로, 자동화된 과학 발견의 완전한 파이프라인을 6단계 방법론 프레임워크를 통해 체계적으로 분류하고 분석한다.
이 서베이는 급속히 성장하는 AI 과학자 분야를 처음으로 체계적이고 포괄적으로 정리한 중요한 작업으로, 6단계 프레임워크를 통해 방법론적 원칙을 명확히 하고 미래 연구의 로드맵을 제시한다. 다만 정량적 성능 비교와 크로스-도메인 일반화에 대한 실증적 분석이 강화되면 더욱 완성도 있는 리뷰가 될 수 있다.
Accelerating science with human-aware artificial intelligence
Figure 1 illustrates a modular and scalable Artificial Orches-
 *Figure 1 illustrates a modular and scalable Artificial Orches-* AI 기반 자동화 약물 발견을 위해 복잡한 실험실 워크플로우를 통합 관리하는 Artificial 오케스트레이션 플랫폼을 제시한다. 데이터 사일로(data silos) 문제를 해결하고 NVIDIA BioNeMo와 같은 AI 모델을 자동화된 실험 프로세스에 통합한다.
본 논문은 자동화 약물 발견의 현실적 도전과제들(데이터 사일로, 워크플로우 복잡성, AI 통합)을 종합적으로 해결하는 실용적인 오케스트레이션 플랫폼을 제시하며, 모듈식 아키텍처와 다중 프로토콜 지원으로 확장성이 우수하다. 다만 드라이 랩 사례만 제시되었으므로 웻 랩 검증과 대규모 실제 운영 환경에서의 성능 평가가 후속되어야 한다.
Artificial intelligence and illusions of understanding in scientific research
Figure 1: The mainstream processes and categories of AI4Research, which can be divided into five key areas:
 *Figure 2: The taxonomy of AI in research (AI4Research) is categorized into five key areas. Each area is* 본 논문은 AI4Research라는 체계적 분류법을 제시하여 과학 연구의 5가지 주요 작업(과학 이해, 학술 조사, 과학 발견, 학술 저술, 동료 평가)에 AI를 적용하는 현황을 종합적으로 조사한 학술 설문 논문이다.
본 논문은 AI4Research 분야의 첫 종합 설문으로서 5단계 파이프라인 분류, 다양한 학제간 응용 사례 수집, 풍부한 오픈 리소스 제공이라는 측면에서 높은 참고 가치가 있다. 다만 제목과 달리 'illusions of understanding'에 대한 비판적 분석이 약하고, 자동화 시스템의 과학적 엄밀성 보장 방안이 구체적이지 않은 점은 개선이 필요하다.
Breaking the gatekeepers: how AI will revolutionize scientific funding
AI 기술이 생물의학 연구비 배분 시스템의 기득권 구조를 와해시켜, 초기경력 과학자와 혁신적 아이디어에 더 공평한 기회를 제공할 수 있음을 주장한다.
이 논문은 과학 자금 배분 시스템의 구조적 결함을 설득력 있게 분석하고, AI 분야와의 대조를 통해 제도적 개선의 필요성을 강하게 주장한다. 다만 AI 기반 해결책의 기술적 구체화와 현실적 실행 방안이 부족하여, 정책 개혁의 첫 단계 진단으로서의 가치는 높으나 실제 구현으로 나아가기 위한 추가 연구가 절실하다.
Early-career setback and future career impact
Fig. 1 Pre-treatment comparisons between the narrow-win and near-miss applicants. a Relationship between normalized scor
 *Fig. 2 Comparing future career outcome between near misses (orange) and narrow wins (blue). a The average number of publ* NIH R01 지원자의 초기 경력 좌절(자금 지원 탈락)이 장기 경력에 미치는 영향을 분석한 결과, 생존한 연구자들은 초기 좌절 후 더 높은 연구 성과를 달성하는 것으로 나타났다.
회귀불연속설계를 통해 초기 경력 좌절과 장기 연구 성과의 인과관계를 엄밀하게 규명한 점에서 높은 방법론적 엄밀성을 보유하며, NIH 전체 데이터 활용과 10년 추적을 통해 신뢰할 수 있는 실증 증거를 제시한 우수한 연구이다.
Global patterns of migration of scholars with economic development
Fig. 1.
 *Fig. 2.* Scopus의 3,600만 개 학술논문 메타데이터를 활용하여 1998-2017년 전 세계 학자(scholars)의 국제 이주 패턴을 분석한 결과, 경제발전에 따른 학자 이주율이 U자형 곡선을 보임을 발견했다.
본 연구는 대규모 서지 데이터를 혁신적으로 활용하여 학자 이주에 대한 최초의 포괄적 글로벌 분석을 제공하며, 일반 인구와 다른 U자형 패턴을 발견함으로써 이주 이론의 확장에 기여한다.
Historical Comparison of Gender Inequality in Scientific Careers Across Countries and Disciplines
Fig. 1.
 *Fig. 1.* 1955-2010년 153만 명 과학자의 출판 경력을 분석한 결과, 여성의 과학 참여 증가에도 불구하고 생산성(productivity)과 영향력(impact)의 성별 격차는 오히려 증가했으며, 이는 주로 경력 길이와 이탈률(dropout rate)의 차이로 설명된다.
이 논문은 대규모 비블리오메트릭 데이터와 정교한 통계 분석으로 성별 불평등의 역설적 증가를 실증하고, 생산성 격차의 구조적 원인(경력 길이·이탈률)을 규명하여 학계의 정책 논의를 근본적으로 재구성하는 의미 있는 기여를 한다.
Impacts of inter-institutional mobility on scientific performance from research capital and social capital perspectives
Fig. 1 Regression model framework
 *Fig. 1 Regression model framework* 본 논문은 인공지능(AI) 분야에서 연구자의 학술기관-산업체 이동(aca.ind mobility)이 연구자의 과학적 성과에 미치는 영향을 연구자본과 사회자본 관점에서 분석한다. PSM(propensity score matching) 방법을 활용하여 인과관계를 규명하고 학술기관 간 이동(aca.aca mobility)과의 비교를 통해 정책적 시사점을 제시한다.
본 논문은 PSM을 활용한 인과추론으로 학산 이동의 실제 효과를 정량화하고, 연구자본 vs 사회자본의 차등적 축적을 실증함으로써 기존 문헌의 중요한 갭을 채웠다. AI 분야의 시의적절한 선택과 명확한 분석 설계는 강점이나, 단일 분야 분석과 성과 측정의 협소함은 개선이 필요하다.
Category Overview
# Knowledge Production & Innovation 카테고리 개요 과학 지식의 생산과 혁신 과정을 이해하기 위한 23편의 논문들은 크게 네 가지 핵심 영역을 다룬다. 첫째, 과학 지도 제작(Science Mapping)과 지식 조직 체계(Knowledge Organization Systems)에 관한 연구들은 연구 분야의 구조를 파악하고 주제의 진화를 추적하는 방법론을 제시한다[1018][1019][930][952][969][1013]. 둘째, 파괴적 혁신(Disruptive Innovation)과 과학적 영향(Scientific Impact)의 측정에 관한 연구들은 높은 영향력을 가진 연구 주제를 식별하고 예측하는 기계학습 기반 접근법을 제안한다[1080][936][962][963][972]. 셋째, 연구 협력과 자금 배분 구조에 관한 연구들은 원격 협업의 영향[1010], 복권 기반 펀딩 모델[1012], 그리고 인공지능 도입의 위험성[1014]을 분석한다. 넷째, 대규모 데이터셋(Large-scale Dataset)과 자연언어 처리 기술의 발전은 과학 문헌의 의미적 분석[1015]과 정책-과학 연계[1016], 그리고 분야별 지식 지도화[1017][978][982]를 가능하게 한다. 마지막으로 촉매 과학(Catalytic Science)의 오픈 데이터셋 개발[1082]은 과학 혁신의 물질적 기반을 다룬다.
⚠ 갭: 혁신적 연구를 촉진하는 제도적 환경과 인센티브 구조에 대한 체계적 연구가 부족하다
🏛 정책: 점진적 개선을 넘어 근본적 혁신을 장려하는 연구 지원 체계로의 전환이 필요하다
Remote collaboration fuses fewer breakthrough ideas
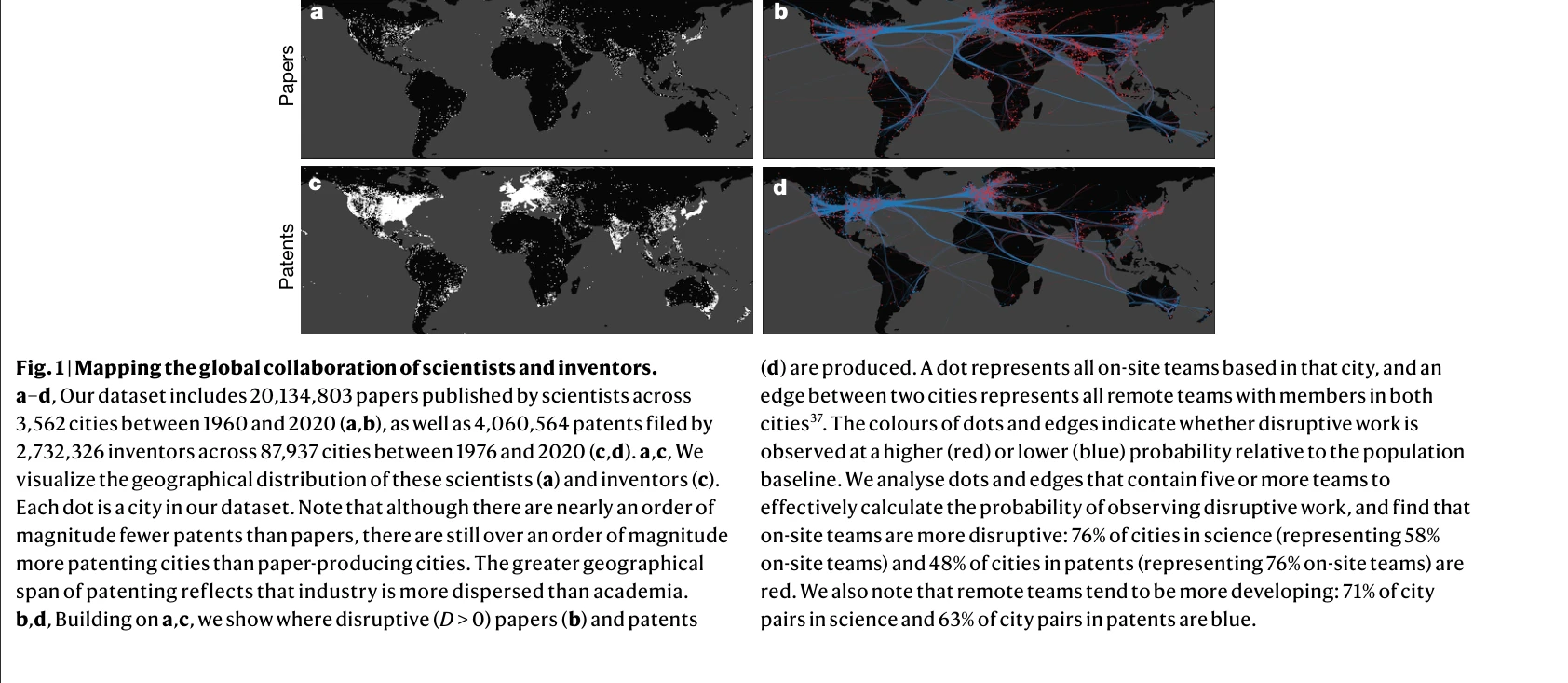
Fig. 1 | Mapping the global collaboration of scientists and inventors.
 *Fig. 3 | Remote teams produce fewer breakthrough innovations. We analysed* 원격 협업이 증가하고 있음에도 불구하고, 20년간의 2,000만 개 논문과 400만 개 특허 분석을 통해 원격 팀이 온사이트 팀보다 혁신적인 아이디어 생성에서 지속적으로 낮은 성과를 보임을 규명했다.
이 논문은 원격 협업의 증가 추세에도 불구하고 혁신이 둔화되는 현상을 팀 내 역할 변화로 설명하는 뛰어난 실증 연구로, 과학기술 정책과 조직 운영에 중요한 함의를 제공한다. 대규모 데이터 분석과 저자 기여도라는 새로운 지표의 활용이 특히 혁신적이다.
Rethink Funding by Putting the Lottery First
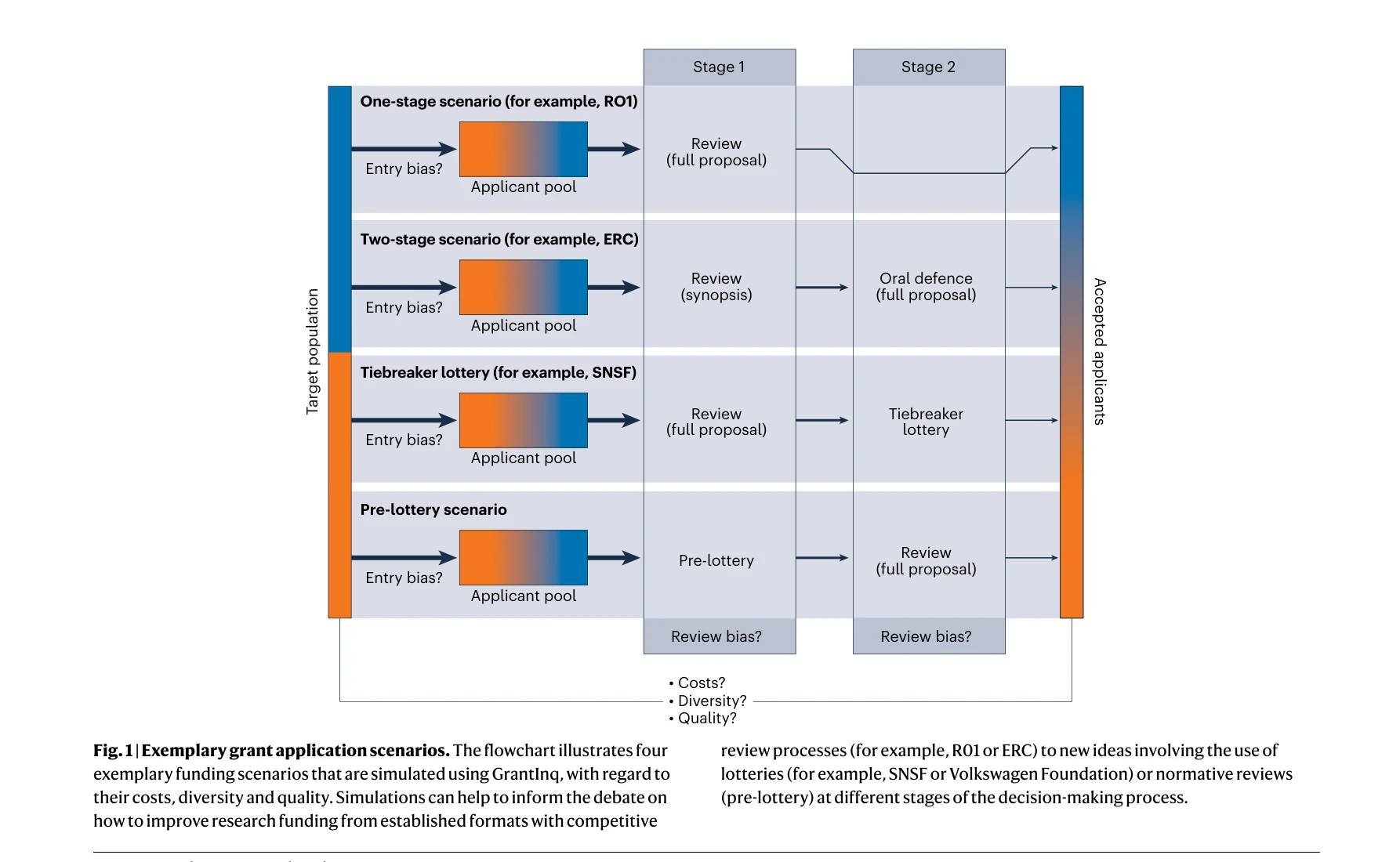
Fig. 1 | Exemplary grant application scenarios. The flowchart illustrates four
 *Fig. 1 | Exemplary grant application scenarios. The flowchart illustrates four* 연구비 배분 과정의 초기 단계에 로또 시스템을 도입하여 체계적 편견을 줄이고 다양성을 증대하며 효율성을 개선할 것을 제안한다.
연구비 배분의 만성적 편견 문제에 대해 로또 시스템의 도입 시점을 획기적으로 변경함으로써 근본적 해결을 제안하는 중요한 논평이다. GrantInq를 통한 정량적 시뮬레이션이 정책 변화의 근거를 제시하나, 실제 구현 과정의 현실적 과제에 대한 심화 검토가 필요하다.
Data, measurement and empirical methods in the science of science
Figure 1: Overview of the data-augmented LLM ideation framework. Compared to the standard
 *Figure 1: Overview of the data-augmented LLM ideation framework. Compared to the standard* 대규모 언어모델(LLM)의 연구 아이디어 생성 과정에 메타데이터와 자동 검증을 통합하여 더 실현 가능하고 효과적인 아이디어를 생성하는 프레임워크를 제안한다.
LLM 기반 연구 아이디어 생성에 데이터를 전략적으로 통합하여 실현 가능성과 실증적 타당성을 동시에 향상시키는 실용적이고 창의적인 방법론을 제시하며, 인간-AI 협력의 실제 가치를 입증한 의미 있는 연구이다.
Robust Evidence for Declining Disruptiveness: Assessing the Role of Zero-Backward-Citation Works
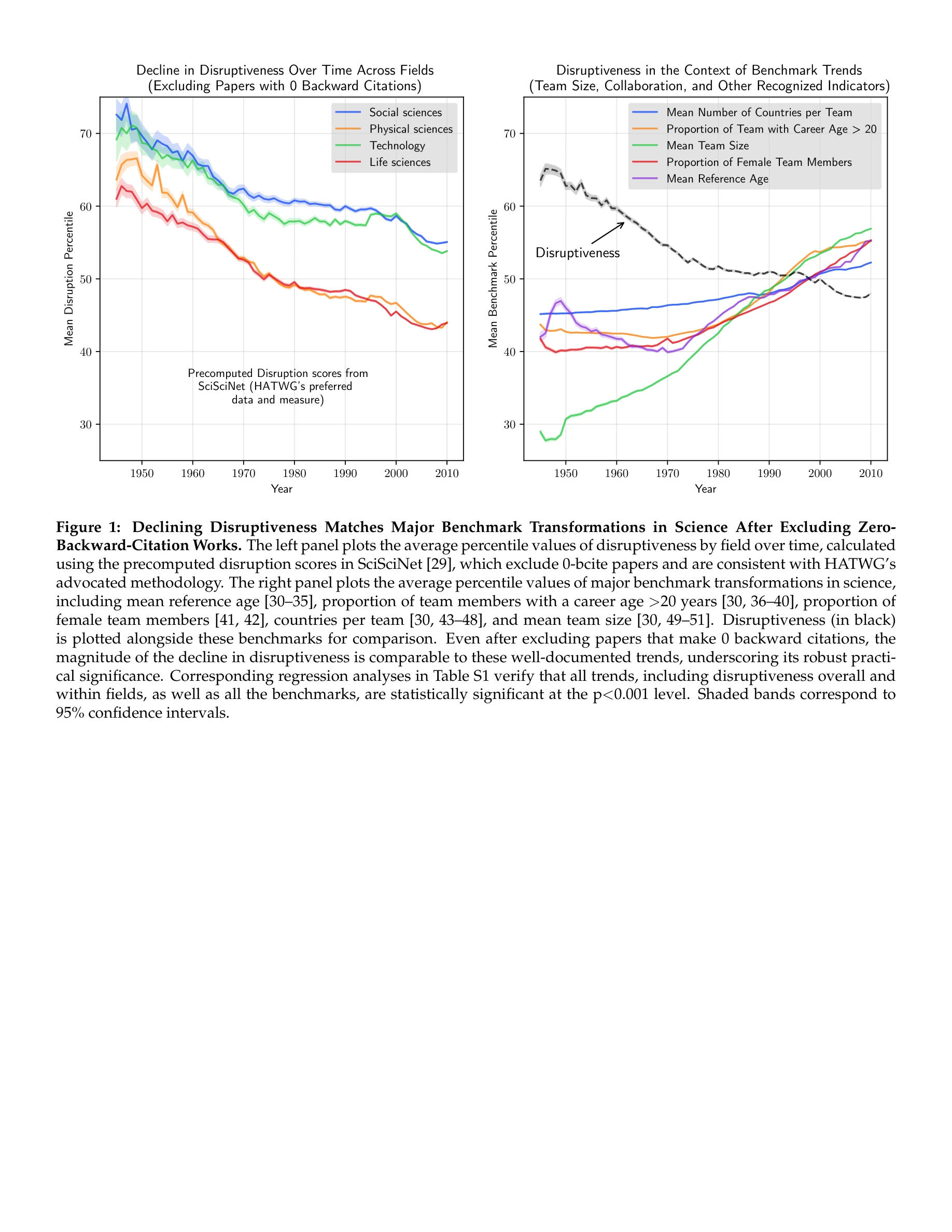
Figure 1: Declining Disruptiveness Matches Major Benchmark Transformations in Science After Excluding Zero-
 *Figure 1: Declining Disruptiveness Matches Major Benchmark Transformations in Science After Excluding Zero-* Park et al.의 과학 파괴성(disruptiveness) 감소 연구에 대한 Holst et al.의 비판에 대응하며, 영인용(zero-backward-citation) 논문을 제외해도 실질적이고 통계적으로 유의미한 감소가 나타남을 보여준다.
과학 계량 분석에서 메타데이터 품질과 방법론의 중요성을 명확히 드러내며, 비판자의 회귀모델 자체가 원래 주장을 반박하는 결과를 제시함으로써 과학의 파괴성 감소라는 원본 연구의 견고성을 강하게 재확인한다.
A General Theory of Bibliometric and Other Cumulative Advantage Processes
누적 이득(Cumulative Advantage) 원리를 따르는 확률 분포 이론을 제시하여 '성공이 성공을 낳는' 현상을 설명하고, 이것이 베타 함수로 지배되며 문헌계량학의 다양한 경험 법칙들의 기초가 됨을 보임.
누적 이득의 수학적 기초를 엄밀하게 제시하여 문헌계량학과 사회과학 현상의 왜곡 분포들을 통일적으로 설명하는 획기적인 이론 제시. 베타 함수의 우아함과 광범위한 적용 가능성으로 인해 학문적 가치가 높으나, 실증 검증과 매개변수 추정의 구체적 방법에 대한 보완이 필요함.
An index to quantify an individual's scientific research output
개별 연구자의 과학적 성과를 정량화하기 위해 h-index를 제안한다. h-index는 h편 이상의 인용을 받은 논문의 수로 정의되며, 연구 영향력을 종합적으로 평가하는 단일 지표이다.
h-index는 연구자의 종합적 과학적 영향력을 측정하는 획기적인 단일 지표를 제시한다. 수학적 모형을 통한 이론적 기초 제공과 실증 데이터로의 검증을 통해 높은 실용성과 설득력을 갖추었으며, 이후 과학 평가의 표준 지표로 광범위하게 채택될 가능성이 크다.
Are disruptive papers more likely to impact technology and society?
CD index(논문의 상대적 파괴성)는 기술 및 사회 영향과 약한 관계를 보이지만, 새롭게 제안된 '파괴적 인용(disruptive citation)' 지표는 기술·사회 임팩트와 강한 긍정 관계를 나타낸다.
약 4천만 개 논문의 대규모 분석으로 기존 CD index의 한계를 실증하고, 절대적 파괴 임팩트 개념을 새롭게 제시하여 과학 평가 방식에 중요한 질문을 던지는 고가치 연구이다. 다만 새로운 지표의 정의가 더 명확하고 인과 관계 규명이 필요하다.
Atypical Combinations and Scientific Impact
Fig. 1. Novelty and conventionality in science. For a sample paper,
 *Fig. 2. The probability of a “hit” paper, conditional on novelty and conventionality. This figure* 1,790만 편의 논문 분석을 통해 높은 영향력을 가진 과학 논문은 기존의 일반적인 지식 조합에 기초하면서도 비전형적(atypical) 조합을 포함할 때 2배 높은 인용률을 보인다는 것을 발견했다.
이 논문은 참고문헌 조합이라는 객관적 지표를 통해 과학적 혁신과 영향력의 관계를 최초로 대규모로 규명한 중요한 연구이며, 팀 과학의 우월성을 실증적으로 입증함으로써 과학 정책과 연구 전략 수립에 직접적인 시사점을 제공한다.
Do novel papers attract more social attention?
Fig. 1. Distribution of paper by year published.
 *Fig. 2. Mean of Altmetrics of papers by whether they are classified as novel paper. AAScore represents the Altmetric Att* 본 연구는 310,000개 이상의 경제학 및 경영학 논문을 분석하여 혁신적(Novel)인 연구가 소셜 미디어, 트위터, 블로그 등 Altmetrics를 통해 더 많은 사회적 관심을 받는지 실증적으로 검증했다.
본 연구는 혁신적 연구가 학술 인용도 외에도 사회적 미디어 플랫폼에서 실질적인 공중의 관심을 끌 수 있음을 대규모 실증 데이터로 처음 입증했으며, 과학의 사회적 영향 평가에 새로운 관점을 제시한 의미 있는 기여를 한다.
Estimating the Reproducibility of Psychological Science
심리학 분야 100개 발표 논문의 재현 연구를 수행한 결과, 재현 효과 크기가 원본의 절반 수준으로 나타나 심리학 연구의 재현성이 심각한 수준임을 실증적으로 규명했다.
본 논문은 심리학 연구의 재현 위기를 최초로 대규모 체계적으로 실증한 획기적 연구로, 학문의 신뢰성 재검토와 방법론 개선의 필요성을 강력하게 제시했다. 이는 심리학뿐만 아니라 전체 학문 공동체의 개혁을 촉발한 매우 영향력 있는 연구이다.
Evaluating the Replicability of Social Science Experiments in Nature and Science
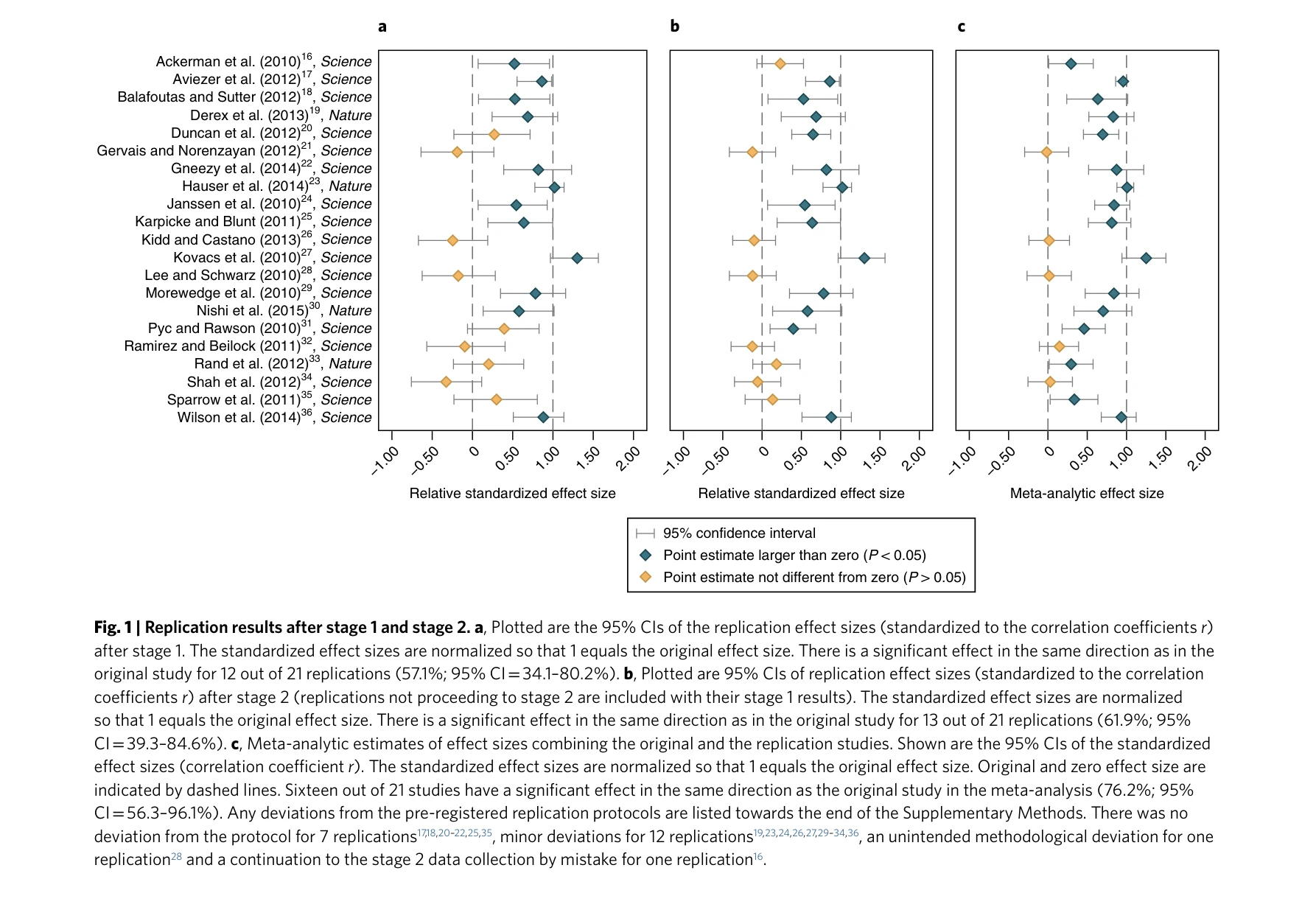
Fig. 1 | Replication results after stage 1 and stage 2. a, Plotted are the 95% CIs of the replication effect sizes (stan
 *Fig. 1 | Replication results after stage 1 and stage 2. a, Plotted are the 95% CIs of the replication effect sizes (stan* 2010-2015년 Nature와 Science에 발표된 사회과학 실험 21개를 체계적으로 재현한 결과, 62%만이 원래 방향의 유의미한 효과를 보였으며 평균 효과크기는 원래의 50% 수준임을 보고한다.
이 연구는 최고 권위 저널의 사회과학 실험이 예상보다 낮은 재현율(62%)과 감소된 효과크기(50%)를 보임을 체계적으로 입증하여 과학 출판과 방법론의 신뢰성 문제를 중요하게 조명했으며, 사전 등록과 투명한 재현 프로토콜이 과학 커뮤니티 표준이 되도록 기여한 중요한 메타과학 연구이다.
Growth Rates of Modern Science: Bibliometric Analysis Based on the Number of Publications and Cited References
Figure 1 shows the exponential growth of global scientific publication output for the
 *Figure 2 shows the segmented growth of the annual number of cited references* 본 연구는 1650년부터 2012년까지 인용 참고문헌(cited references) 데이터를 기반으로 현대 과학의 성장률을 분석하여, 과학이 세 개의 명확한 성장 단계를 거쳐 왔음을 밝혔다.
본 논문은 장기간 인용 데이터와 고급 통계 기법을 결합하여 현대 과학의 성장 패턴을 정밀하게 규명한 우수한 연구이며, 과학정책 수립과 학문 발전 이해에 중요한 기여를 한다.
Papers and patents are becoming less disruptive over time
Fig. 1: Overview of the measurement approach.
 *Fig. 2: Decline of disruptive science and technology.* 지난 60년간 45백만 편의 논문과 390만 개의 특허를 분석한 결과, 과학과 기술 논문/특허들이 시간이 지남에 따라 과거와의 단절을 추구하지 않는 경향(disruptiveness 감소)을 보이고 있다. 이는 새로운 지식이 축적되었음에도 불구하고 혁신의 속도가 둔화되고 있음을 시사한다.
본 논문은 과학과 기술의 진보 패턴을 정량적으로 규명하는 획기적 연구로, 새로운 CD 지수 개발과 초대규모 데이터 분석을 통해 '디스럽션의 역설'을 설득력 있게 입증했다. 결과는 과학 정책과 혁신 전략 수립에 중요한 시사점을 제공하지만, 인과관계 규명과 메커니즘 심화 분석은 향후 연구 과제로 남아있다.
Rethinking Thematic Evolution in Science Mapping: An Integrated Framework for Longitudinal Analysis

 *Figure 5: Evolutionary graph.* 과학 지도 작성(science mapping)에서 종단 분석 시 테마 감지와 계보 구성의 구조적 불일치를 해결하기 위해, 가중 관계형 네트워크 내에 lineage reconstruction을 통합하는 프레임워크를 제안한다.
과학 지도 작성의 오래된 구조적 불일치를 창의적으로 해결하고, fuzzy affiliation과 관계형 중심의 진화 개념화로 높은 방법론적 일관성을 달성했다. 다만 실증적 검증과 비교 분석이 강화되면 더욱 설득력 있는 기여가 될 것이다.
Science Mapping and Science Maps
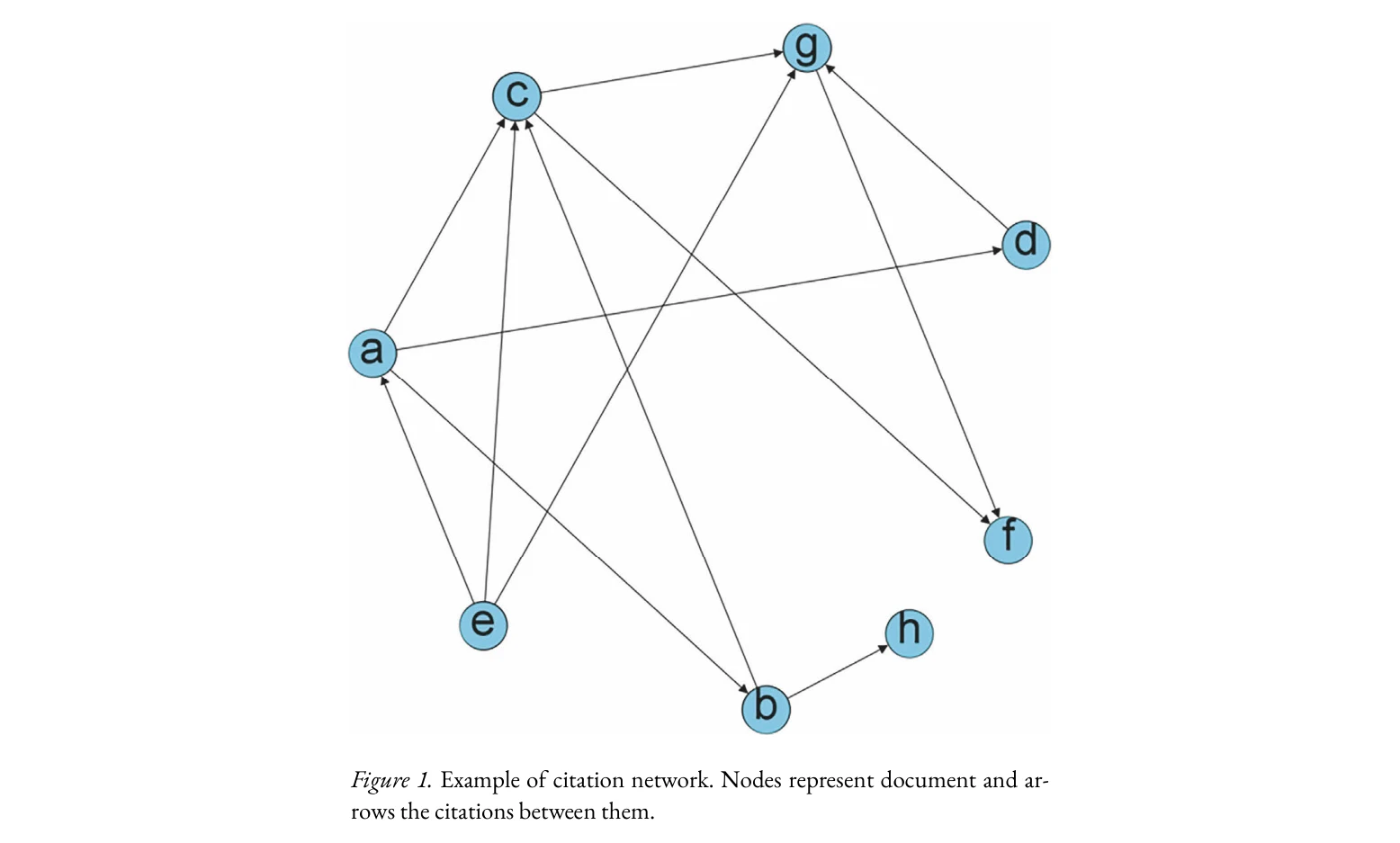
Figure 1. Example of citation network. Nodes represent document and ar-
 *Figure 1. Example of citation network. Nodes represent document and ar-* 본 논문은 과학 지식의 구조와 동역학을 시각적으로 표현하는 과학 매핑(Science Mapping)의 개념, 이론, 방법론을 종합적으로 소개하는 입문서이다. 인용 네트워크(Citation Network)와 용어 기반 네트워크(Term-based Network) 등 주요 매핑 기법들의 생성 원리와 절차를 상세히 설명한다.
본 논문은 과학 매핑의 방법론적 토대를 체계적으로 정리하고 에피스테몰로지적·사회학적 함의를 포함하여 메타과학적 가치를 제시한 종합적 입문서로, 학계와 과학정책 수립에 실질적 기여를 할 수 있다. 다만 수학적 형식화 부재와 정성적 검증 부족이 기술적 깊이를 제한한다.
Science of science
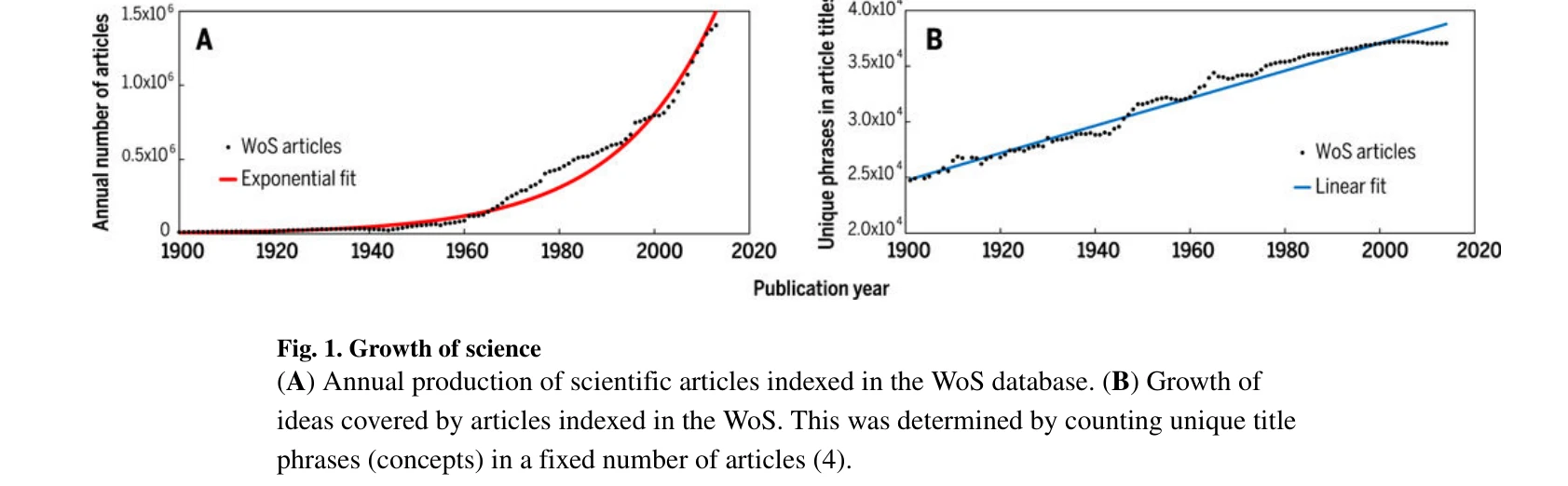
 *Fig. 5. Universality in citation dynamics* 과학의 메커니즘을 대규모 데이터(big data)로 정량적으로 분석하는 SciSci(과학의 과학)는 과학자의 선택, 경력, 팀 구성 등이 과학적 발견에 미치는 영향을 파악하여 과학 정책 개선을 목표로 한다.
본 논문은 과학의 메커니즘을 정량적으로 분석하는 새로운 학문 분야 SciSci를 종합적으로 소개하며, 출판 지수 성장 vs 개념 선형 확장, 팀 규모의 역설 등 흥미로운 발견들을 제시한다. 다만 분야 간 차이 고려 부족과 인과관계 규명의 한계는 향후 개선 과제이다.
A Survey on Knowledge Organization Systems of Research Fields: Resources and Challenges
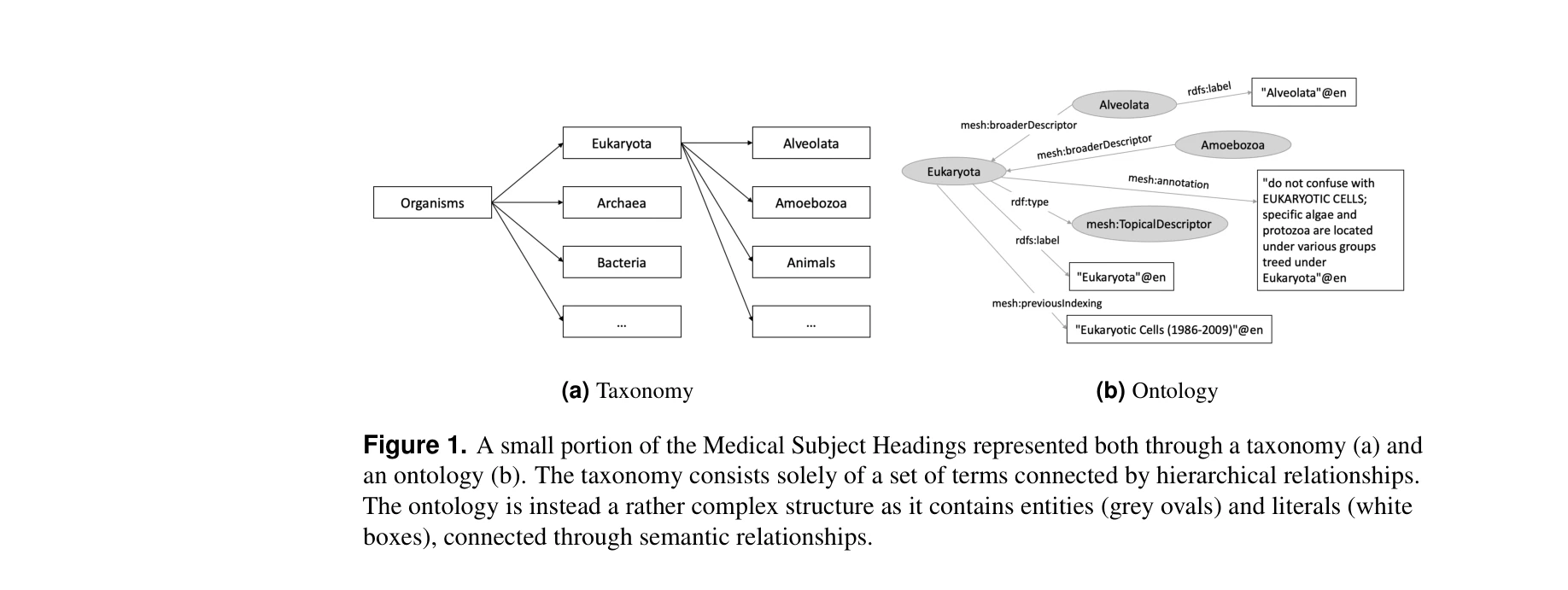
 *Figure 2. The aspects and features used for the analysis of Knowledge Organization Systems.* 학술 분야의 지식 조직 체계(KOS) 45개를 5개 차원(범위, 구조, 큐레이션, 사용, 상호 링크)으로 분석하여 학술 지식 표현의 현황과 통합의 필요성을 제시한 종합 조사.
학술 지식 조직 체계에 대한 최초의 포괄적 종합 조사로서 현황 파악과 문제점 규명에 매우 중요한 기여를 하며, 체계적 방법론과 투명한 공개 원칙을 통해 높은 신뢰성을 확보했다.
Comparative science mapping: a novel conceptual structure analysis with metadata
Fig. 1 Analytical strategy for detecting and mapping the conceptual structure
 *Fig. 1 Analytical strategy for detecting and mapping the conceptual structure* 메타데이터를 활용한 비교 과학지도(comparative science mapping) 기법을 제안하여, 저자, 기관, 지역 등의 특성에 따라 과학출판물의 개념 구조를 다중 관점에서 분석하고 시각화한다.
메타데이터를 활용하여 기존 과학지도 기법을 창의적으로 확장한 연구로, 이탈리아 종양학 연구의 종합적 분석을 통해 정책 입안과 기관 전략 수립에 실질적 기여를 제공한다.
Design and Update of a Classification System: The UCSD Map of Science
Figure 1. Visualizations of the UCSD Map: 2D Mercator projection (left) with three 3D spherical insets (top), 1D circula
 *Figure 1. Visualizations of the UCSD Map: 2D Mercator projection (left) with three 3D spherical insets (top), 1D circula* 본 논문은 과학 전체를 포괄하는 분류 체계인 UCSD Map of Science를 설계하고 업데이트한 과정을 상세히 기술하며, 원본 5년 데이터 기반 지도를 10년 데이터로 확장하여 학문 분야의 구조를 시각화하고 분석한다.
본 논문은 과학 지도 설계의 실무적 노하우를 상세히 제시하고 장기 데이터를 통한 체계적인 업데이트를 최초로 수행한 중요한 기여를 한다. 다만 기술적 혁신보다는 기존 방법론의 신중한 적용과 포괄적인 비교 분석이 주요 강점이며, 학제 간 연구 및 정책 결정을 지원하는 실용적 가치가 매우 높다.
Hierarchical Classification of Research Fields in the "Web of Science" Using Deep Learning
 *Fig. 3 Three-level hierarchical classification system.* Microsoft Academic Graph의 1.6억 개 논문 초록을 이용하여 44개 학문분야, 718개 필드, 1,485개 세부분야로 계층적으로 자동 분류하는 딥러닝 시스템을 제시하며, 단일/다중 레이블 설정에서 90% 이상의 정확도를 달성한다.
본 논문은 전 학문분야를 포괄하는 첫 통일 계층 분류 시스템으로, 학제간 연구 측정과 학문 활동의 자동 색인화에 실질적 기여를 한다. 1.6억 규모 데이터와 3,140회 실험을 통한 강건한 검증과 공개 코드베이스로 높은 재현성과 실용성을 제공한다.
Identifying interdisciplinary emergence in the science of science: combination of network analysis and BERTopic
Fig. 1 Overall research process. The overall research process is performed
 *Fig. 4 Process of BERTopic modeling. The process of BERTopic modeling* 이 연구는 BERTopic 임베딩 토픽 모델링과 네트워크 분석을 결합하여 과학 간행물 메타데이터에서 학제간 지식 재조합을 통해 새로운 과학의 출현을 식별하는 방법을 제안한다.
이 연구는 네트워크 분석과 임베딩 토픽 모델링을 창의적으로 결합하여 학제간 과학의 출현을 식별하는 새로운 방법론을 제시하며, 과학 정책 수립과 혁신 예측에 실질적 가치를 제공한다. 데이터 기반 접근과 질적 검증을 통해 방법론의 신뢰성을 입증했으나, 데이터 범위 확대와 추가적 타당성 검증이 필요하다.
Introducing the open biomedical map of science
PubMed 데이터베이스를 활용하여 생의학 분야의 공개 과학 지도(OBMS)를 개발하는 작업을 소개하며, 저널과 MeSH(Medical Subject Heading) 기술자 간의 이중 네트워크 관계를 시각화한다.
이 논문은 공개 생의학 과학 지도 개발을 위한 견고한 방법론과 초기 성과를 제시하며, 상용 데이터베이스에 의존하지 않는 재현 가능한 과학 지도의 새로운 기준을 제시한다. 다만 현재는 진행 중인 작업(work in progress)으로 완성도 있는 최종 산물과 실제 활용 사례의 제시가 필요하다.
Mapping Knowledge: Topic Analysis of Science Locates Researchers in Disciplinary Landscape
Figure 1: Clustering of disciplinary topic portfolios. Hierarchical clustering with
 *Figure 2: Cloud of topics in the knowledge space. Scores of topics on principal* 이 연구는 토픽 모델링, 구성 데이터 분석, 기하학적 데이터 분석을 결합하여 과학자들을 학문 분야 내에서 위치시키는 새로운 인식론적 좌표 체계를 제시한다. 체코 국가 연구 데이터셋(1,039,577개 출판물, 118,560명 저자)을 활용하여 지식과 지식 생산자의 간격을 해소한다.
이 논문은 과학 지도 작성의 두 전통을 성공적으로 통합하며, 토픽 모델링과 기하학적 데이터 분석의 창의적 결합을 통해 연구자들을 인식론적 좌표계에 위치시키는 혁신적 방법론을 제시한다. 과학 정책 수립과 학문 분야 분석에 즉시 적용 가능한 실질적 가치가 높다.
Mapping the changing structure of science through diachronic periodical embeddings
학술지(periodical)의 시간에 따른 의미론적 변화를 추적하는 '시간 경과 임베딩(diachronic embedding)' 방법을 개발하여 과학의 구조 진화를 정량화한다.
시간 경과 임베딩을 통해 과학 진화를 정량적으로 추적하는 창의적 방법론을 제시하며, 광범위한 검증과 신흥 주제 발견으로 과학의 학문 구조 연구에 중대한 기여를 한다. 다만 데이터 범위 명시와 다양한 임베딩 방법 비교가 보강되면 더욱 강력해질 것이다.
Modeling Changing Scientific Concepts with Complex Networks: A Case Study on the Chemical Revolution

Figure 1: Diachronic prototypical concepts. This
 *Figure 1: Diachronic prototypical concepts. This* 본 논문은 복잡 네트워크(complex networks)를 기반으로 과학 개념의 변화를 모델링하는 프레임워크를 제시하며, 화학혁명에서 프로지스톤과 산소 이론의 경쟁을 사례 연구로 분석하여 onomasiological change(명칭학적 변화)가 높은 엔트로피와 위상학적 밀도와 연관됨을 보인다.
이 논문은 LLM의 해석 불가능성과 역사 데이터 편향 문제를 직시하며, prototype semantics과 복잡 네트워크를 결합한 혁신적 프레임워크로 과학 개념의 시간적 변화를 해석 가능하게 모델링한다. 화학혁명 사례에서 엔트로피-위상학적 밀도와 개념 변화의 연관성을 명확히 입증하였으나, 일반화 검증과 구체적인 방법론 정밀화가 필요하다.
OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts

Figure 1: Sketch of the OpenAlex graph data model.
 *Figure 1: Sketch of the OpenAlex graph data model.* Microsoft Academic Graph 종료에 대응하여 개발된 OpenAlex는 학술 저작물, 저자, 학술지, 기관, 개념으로 구성된 완전 개방형(open data, open API, open-source) 학술 메타데이터 지식 그래프(SKG: Scientific Knowledge Graph)이다.
OpenAlex는 MAG의 공백을 신속히 메우면서 완전 개방 원칙으로 학술 정보 인프라의 민주화를 선도하는 역사적 가치 있는 프로젝트이다. 다만 데이터 품질 향상과 독립적 검증이 광범위한 채택을 위한 필수 과제이다.
Risk and Artificial Intelligence Adoption: A Scientometric and Thematic Evolution Analysis Based on Scopus and Web of Science (1990-2025)
1990-2025년 Scopus와 Web of Science 612개 문헌을 통해 AI 도입 연구에서 위험(Risk)의 개념이 개별 지각적 억제요인에서 시스템 수준의 거버넌스 구조로 진화하는 과정을 과학계량학(scientometric) 및 주제 진화(thematic evolution) 분석으로 규명했다.
본 연구는 AI 도입 연구에서 위험 개념의 근본적 패러다임 전환을 과학계량학 방법으로 체계적으로 규명한 의의 있는 통합 분석이며, 거버넌스-기술 수용 이원적 지식 전통의 융합 경로를 명확히 제시하여 향후 AI 위험 거버넌스 연구의 방향 설정에 실질적 기여를 한다.
S2ORC: The Semantic Scholar Open Research Corpus

Figure 1: Inline citations and references to figures and
 *Figure 1: Inline citations and references to figures and* 81.1M개의 학술논문으로 구성된 S2ORC 코퍼스를 소개하며, 8.1M개의 오픈액세스 논문에 대해 구조화된 전문(full text)과 인용 관계를 기계가독형으로 제공한다.
S2ORC는 학술 논문 분석을 위한 가장 포괄적이고 구조화된 대규모 공개 코퍼스로서, 학술 텍스트 마이닝, 인용 분석, 지식 추출 등 다양한 NLP 연구를 촉진할 수 있는 중요한 기여이다.
Sci2Pol: Evaluating and Fine-tuning LLMs on Scientific-to-Policy Brief Generation
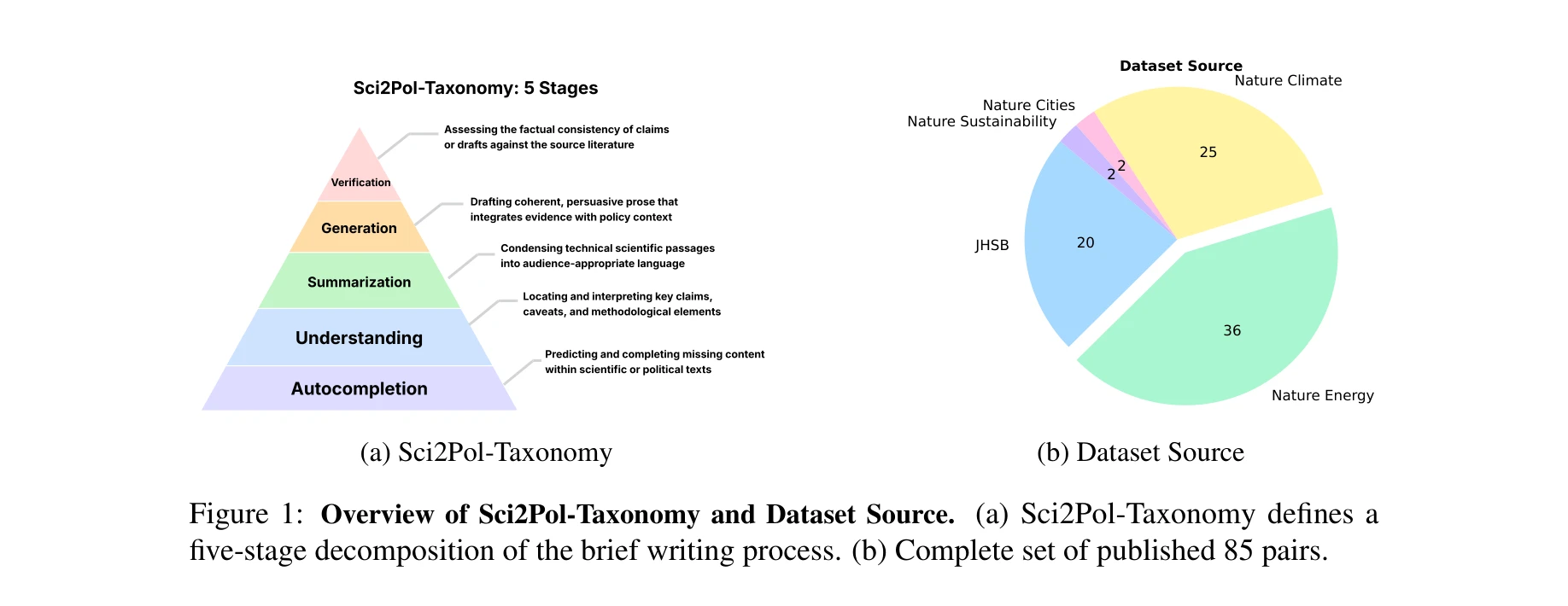
Figure 1: Overview of Sci2Pol-Taxonomy and Dataset Source. (a) Sci2Pol-Taxonomy defines a
 *Figure 1: Overview of Sci2Pol-Taxonomy and Dataset Source. (a) Sci2Pol-Taxonomy defines a* 과학 논문을 정책 문서로 변환하는 LLM 성능 평가를 위한 첫 번째 벤치마크(Sci2Pol-Bench)와 미세조정 데이터셋(Sci2Pol-Corpus)을 제시하며, 인간의 집필 과정을 반영한 5단계 분류체계를 기반으로 18개 과제를 설계했다.
본 논문은 과학-정책 간 격차 해소라는 실질적 문제에 대응하는 첫 전문 벤치마크와 데이터셋을 제시하며, 인간 중심의 분류체계와 LLM 기반 평가 메트릭을 통해 고품질 평가 체계를 구축했다는 점에서 높은 원창성과 실용적 가치를 가진다.
Challenges in High-Throughput Inorganic Materials Prediction and Autonomous Synthesis
자동화 재료 발견 시스템(A-lab)의 43개 신규 재료 발견 주장을 재검토한 결과, 자동 Rietveld 분석의 신뢰성 부족과 재료의 무질서(disorder) 예측 누락으로 인해 실제로는 신규 재료가 발견되지 않았음을 지적한다.
자동화 재료 발견의 신뢰성 제고를 위한 중요한 비판적 분석으로, PXRD 특성화와 무질서 모델링의 두 가지 핵심 병목을 명확히 지적한다. 고처리량 재료 탐색의 실질적 진전을 위해 실험 결정학과 계산 화학의 협업 개선을 강력히 촉구하는 관점 논문이다.
Embracing Foundation Models for Advancing Scientific Discovery
Fig. 1: The song of humanity is a song of courage. The diagram depicts the continuum of scientific inquiry spanning from
 *Fig. 1: The song of humanity is a song of courage. The diagram depicts the continuum of scientific inquiry spanning from* 본 논문은 과학 분야 대규모언어모델(Sci-LLM)의 발전을 데이터 중심으로 분석하는 종합 서베이로, 270개 이상의 사전학습/사후학습 데이터셋과 190개 이상의 벤치마크를 체계적으로 검토하여 과학 AI의 로드맵을 제시한다.
본 서베이는 과학 분야 AI의 발전을 데이터 관점에서 종합적으로 분석한 중요한 기여로, 과학 LLM 개발을 위한 이론적 프레임워크와 실무적 로드맵을 제시한다. 다만 정량적 성과 분석과 자율 에이전트 패러다임의 구체적 구현 사례가 보강될 필요가 있다.
MOLIERE: Automatic Biomedical Hypothesis Generation System
Figure 1: Overview of the TruthHypo benchmark, including dataset construction, task formulation, and truthfulness evalua
 *Figure 1: Overview of the TruthHypo benchmark, including dataset construction, task formulation, and truthfulness evalua* LLM의 생의학 가설 생성 능력을 평가하기 위해 TruthHypo 벤치마크와 KnowHD 할루시네이션 탐지 프레임워크를 제안하여, 생성된 가설의 진실성과 지식 기반성을 체계적으로 평가한다.
본 논문은 LLM 기반 과학 가설 생성의 신뢰성을 평가하는 중요한 문제를 체계적으로 다루며, TruthHypo와 KnowHD를 통해 진실성 평가와 할루시네이션 탐지의 새로운 접근법을 제시한다. 생의학 분야의 가설 생성 벤치마크와 실용적인 할루시네이션 탐지 도구로서 과학 발견 가속화에 기여할 수 있는 가치 있는 연구이다.
OLMo: Accelerating the Science of Language Models
Figure 1: Accuracy score progression of OLMo-7B on 8 core end-tasks score from Catwalk evaluation suite
 *Figure 1: Accuracy score progression of OLMo-7B on 8 core end-tasks score from Catwalk evaluation suite* OLMo는 훈련 데이터, 훈련 코드, 평가 도구까지 모두 공개한 완전 개방형 언어 모델(Open Language Model)이다. 이를 통해 언어 모델에 대한 과학적 연구를 가능하게 한다.
OLMo는 진정한 의미의 완전 개방형 언어 모델을 제공함으로써 언어 모델 연구의 투명성과 재현성을 획기적으로 향상시킨다. 데이터, 코드, 도구까지 모두 공개하는 이 종합적인 접근은 학술 커뮤니티에 큰 기여를 하며 향후 언어 모델 연구의 새로운 방향을 제시한다.
Open Catalyst 2020 (OC20) Dataset and Community Challenges
Figure 1: Adsorbates, materials, calculations,
 *Figure 1: Adsorbates, materials, calculations,* 촉매 발견을 가속화하기 위해 1.28백만 개의 DFT 계산을 포함한 OC20 데이터셋과 3개의 도메인 챌린지 과제를 제시하여 머신러닝 모델의 일반화 능력 향상을 목표로 함.
촉매 머신러닝 분야에서 획기적인 대규모 데이터셋을 제공하고 명확한 벤치마크 과제와 공개 인프라를 제시하여 커뮤니티 기반 모델 개발을 촉진하는 핵심 기여이나, 단순화된 모델 가정이 실제 촉매 응용으로의 전이 시 한계가 있을 수 있음.
The Open Catalyst 2022 (OC22) Dataset and Challenges for Oxide Electrocatalysts

Figure 1: Adsorbates, materials, calculations,
 *Figure 1: Adsorbates, materials, calculations,* OC20 데이터셋은 1.2백만 개 이상의 DFT 완화 계산을 포함하는 촉매 발견을 위한 대규모 오픈소스 데이터셋이며, 그래프 신경망 모델들의 성능 벤치마크와 커뮤니티 챌린지를 제공한다.
OC20은 촉매 발견을 위한 ML 응용 분야에서 혁신적인 대규모 공개 데이터셋으로, 명확한 도메인 챌린지와 함께 그래프 신경망 기반 모델 개발을 크게 촉진할 수 있는 중요한 리소스이다.
AI-Driven Automation Can Become the Foundation of Next-Era Science of Science Research
Figure 1: An illustration comparing human-driven and AI-driven research
 *Figure 1: An illustration comparing human-driven and AI-driven research* 본 논문은 과학의 과학(Science of Science, SoS) 연구에 AI 기반 자동화를 도입하여 대규모 연구 패턴 발견을 가능하게 하는 AI4SoS 프레임워크를 제시한다. 전통적인 통계 방법을 넘어 머신러닝과 멀티에이전트 시스템을 활용하여 과학 생태계의 복잡성을 자동으로 분석하고 시뮬레이션한다.
본 논문은 과학의 과학 연구에 AI를 체계적으로 통합하는 AI4SoS라는 새로운 학문 영역을 제안하고, 5단계 자동화 계층으로 명확한 로드맵을 제시하여 큰 개념적 기여를 한다. 다만 제시된 멀티에이전트 시스템은 예시 수준에 머물러 있으며, 실제 검증과 평가 체계가 더욱 강화될 필요가 있다.
Do Large Language Models Reduce Research Novelty? Evidence from Information Systems Journals
Figure 1. Research model. The main path captures the association between LLM availability and semantic novelty,
 *Figure 2. Event study coefficients for Post x Non-EDA interaction, relative to 2022. Pre-treatment coefficients* ChatGPT 출시 이후 대언어모델(LLM)이 연구 생산성을 높였지만, 의미론적 참신성(semantic novelty)은 감소했으며, 특히 영어 비주류국 소속 저자들에게서 더욱 뚜렷한 경향이 나타났다.
LLM의 생산성 이득이 지적 다양성 감소와 동반되는 현상을 최초로 실증적으로 입증한 중요한 연구로, 특히 저자 집단 간 이질적 효과를 통해 기술의 불균형적 영향을 드러냈으며, 구성수준이론이라는 심리학적 설명으로 AI 정책의 중요한 함의를 제공한다.
Science as exploration in a knowledge landscape: tracing hotspots or seeking opportunity?
 *Figure 2 The illustration of scientists’ trajectories in the knowledge space. a. The distribution of papers in the* 본 연구는 지리정보시스템(GIS) 기법을 활용하여 과학자들의 연구주제 전환 패턴을 지식공간(knowledge space)에서 탐색 과정으로 분석하고, 보수적 탐색 경향과 집단 행동의 메커니즘을 규명한다.
본 논문은 과학자의 주제 선택 행동을 지식공간 탐색으로 재프레이밍하고 GIS 기법을 창의적으로 적용하여, 개인의 보수성과 사회적 효과(network effects)라는 이중 메커니즘을 실증적으로 규명한 우수한 연구이다. 다만 학문 간 이질성과 시간적 동역학의 깊이 있는 분석으로 한층 강화될 여지가 있다.
Forecasting high-impact research topics via machine learning on evolving knowledge graphs
21백만 개의 과학논문으로부터 구축한 진화하는 지식그래프(evolving knowledge graph)와 머신러닝을 활용하여, 아직 발표되지 않은 새로운 연구 아이디어의 미래 영향력(impact)을 예측하는 기법을 제시한다.
과학 지식의 빠른 성장 속에서 미발표 연구의 미래 영향력을 조기에 예측하는 혁신적 접근법을 제시하며, 대규모 진화 지식그래프와 머신러닝의 결합으로 높은 예측 성능을 달성했다. 다만 도메인 특화성, 영향력 지표의 제한성, 해석 가능성 부족 등의 개선이 필요하며, 향후 과학 AI 어시스턴트 개발의 중요한 토대가 될 수 있다.
Forecasting the future of artificial intelligence with machine learning-based link prediction in an exponentially growing knowledge network
Fig. 1 | The number of papers published per month in the arXiv categories of
 *Fig. 2 | From arXiv to Science4Cast. Utilizing 143,000 AI and ML papers on* 143,000개의 AI 논문으로부터 64,000개 개념 노드를 가진 의미 네트워크(semantic network)를 구축하고, 머신러닝 기반 링크 예측(link prediction)을 통해 미래의 AI 연구 방향을 예측한다.
이 논문은 대규모 의미 네트워크에서 머신러닝 기반 링크 예측을 통해 미래 AI 연구 방향을 예측하는 실용적이고 확장 가능한 접근법을 제시하며, 수작업 특성의 우월성이라는 반직관적이지만 중요한 발견을 제공한다. 실제 과학 생산성 향상을 위한 연구 제안 도구 개발의 중요한 기초 연구이다.
Predicting Scientific Breakthroughs Based on Structural Dynamic of Citation Cascades
 *Figure 4. The new approach proposed in this study to constructing citation cascade networks for* 인용 네트워크의 동적 구조 진화를 추적하여 과학적 돌파(breakthrough) 논문을 예측하는 새로운 방법을 제안. 시계열 인용 캐스케이드(citation cascades)를 구성하고 위상 지표, PageRank, von Neumann 그래프 엔트로피의 동적 궤적을 활용하여 정적 방법 대비 7% 성능 향상을 달성.
본 연구는 인용 네트워크의 동적 진화를 처음으로 체계적으로 모델링하여 과학적 돌파 예측 정확도를 향상시킨 의미 있는 기여를 제시한다. 다만 노벨상 데이터셋 의존성과 일반화 가능성 측면에서 추가 검증이 필요하며, 실무 적용을 위해서는 더 광범위한 도메인과 시간 규모에서의 실험이 요구된다.
Coevolution of policy and science during the pandemic
COVID-19 팬데믹 기간 정책 문서와 과학 논문의 상호작용을 대규모 데이터베이스로 분석하여, 정책이 최신의 동료검증 과학을 실제로 활용하고 있음을 보여준다.
본 연구는 대규모 데이터 통합을 통해 과학-정책 연결에 관한 오래된 회의론을 실증적으로 반박하며, 팬데믹 대응에서 정책이 실제로 최신 동료검증 과학을 우선적으로 활용함을 명확히 보여준다. 다만 인용의 실제 영향력과 정책 효과성과의 연계 분석이 추가되면 더욱 설득력 있을 것이다.
Evolution of the social network of scientific collaborations
1991-1998년 8년간의 수학 및 신경과학 논문 데이터베이스를 분석하여 과학자 협력 네트워크의 진화 메커니즘을 규명한 연구로, scale-free 네트워크 특성과 preferential attachment 현상을 실증적으로 검증하고 모델링했다.
복잡계 네트워크 과학의 고전적 논문으로, 협력 네트워크의 동역학적 진화를 최초로 체계적으로 분석하고 preferential attachment를 실증적으로 검증하여 scale-free 네트워크 이론의 실증적 기초를 확립했다. 실증-모델-시뮬레이션의 삼각 검증 방법론과 내부/외부 링크 구분 모델은 이후 네트워크 과학 연구의 표준 방법론으로 광범위하게 채택되었다.
Large teams develop and small teams disrupt science and technology
Fig. 1 | Quantifying disruption. a, Simplified illustration of disruption.
 *Fig. 2 | Small teams disrupt whereas large teams develop. a–c, For* 65백만 개의 논문, 특허, 소프트웨어를 분석하여 소규모 팀은 파괴적(disruptive) 혁신을, 대규모 팀은 점진적(developmental) 개선을 주도한다는 것을 실증했다.
팀 과학 시대에 소규모 팀의 역할을 정량적으로 재평가한 획기적 연구로, 대규모 데이터와 혁신적 측정 방법론으로 과학정책의 다양성 추구 필요성을 강력하게 입증했다.
Category Overview
과학 연구의 투명성과 신뢰성을 확보하기 위한 연구 무결성(Research Integrity)과 학술 출판(Academic Publishing) 분야의 종합적 분석을 다룬다. 본 카테고리는 과학 생태계의 구조적 문제점부터 기술적 해결방안까지 아우르며, 특히 대규모 언어모델(Large Language Models)을 활용한 과학 메타데이터 분석과 출판 시스템의 혁신을 중점적으로 살펴본다. 다양성과 혁신의 역설, 마태 효과(Matthew effect) 같은 과학 펀딩의 불평등 구조, 그리고 학술 출판 과점(Oligopoly) 현상을 비판적으로 검토한다[1032, 1033, 1035, 1036, 1038]. 동시에 의도적 복제 검증(Replication Studies)을 통한 재현성(Reproducibility) 평가, 의미론적 및 신경망 기반의 연구 동향 예측(Research Trend Prediction), 그리고 오픈 액세스 데이터베이스(OpenAlex)의 메타데이터 품질 개선 방안을 제시한다[958, 959, 992, 1076]. 나아가 머신러닝(Machine-learning) 윤리 가이드라인 개발, 파이썬 기반 참고문헌 통합 도구(Bibliography Integration Tools), 그리고 과학 논문에서의 LLM 활용도 정량화 방법론을 통해 현대 과학 출판의 신뢰성을 보장하는 구체적 전략들을 제안한다[939, 1077, 1079].
⚠ 갭: 오픈사이언스 환경에서의 품질 관리와 연구 무결성 확보 방안이 미흡하다
🏛 정책: 연구 무결성 강화를 위한 제도적 장치와 오픈사이언스 생태계 구축이 시급하다
The Diversity-Innovation Paradox in Science
Fig. 1.
 *Fig. 1.* 미국 박사학위 취득자 120만 명을 분석하여 소수집단이 다수집단보다 더 높은 과학적 혁신을 생산하지만, 그들의 혁신적 기여가 과소평가되고 학술 경력으로 이어지지 않는 '다양성-혁신 역설'을 실증적으로 규명했다.
이 연구는 다양성과 혁신 사이의 역설을 대규모 자료로 최초 실증하여, 학계 불평등의 근본 원인이 '개인의 능력 부족'이 아닌 '제도적 편향'임을 명확히 했다. 방법론적 엄밀성과 정책적 함의가 높지만, 인구통계 측정의 한계와 지리적 범위가 제한적이다.
The Empowerment of Science of Science by Large Language Models: New Tools and Methods
Figure 1. Parameters and classification of notable LLMs
 *Figure 1. Parameters and classification of notable LLMs* 본 논문은 대규모 언어모델(LLM)의 핵심 기술들을 사용자 관점에서 체계적으로 검토하고, 과학계량학(SciSci) 분야에의 응용 가능성을 제시하는 종합 리뷰 논문이다.
본 논문은 LLM의 핵심 기술을 체계적으로 정리하고 과학계량학과의 융합 가능성을 제시함으로써, AI for Science의 새로운 방향을 제시하는 가치 있는 종합 리뷰이다. 다만 구체적인 실증 연구와 적용 사례로 보강된다면 더욱 실용적인 가이드가 될 것이다.
The Innovation Recognition Paradox: How Science Undervalues the Boundary-Crossing Work Women Produce
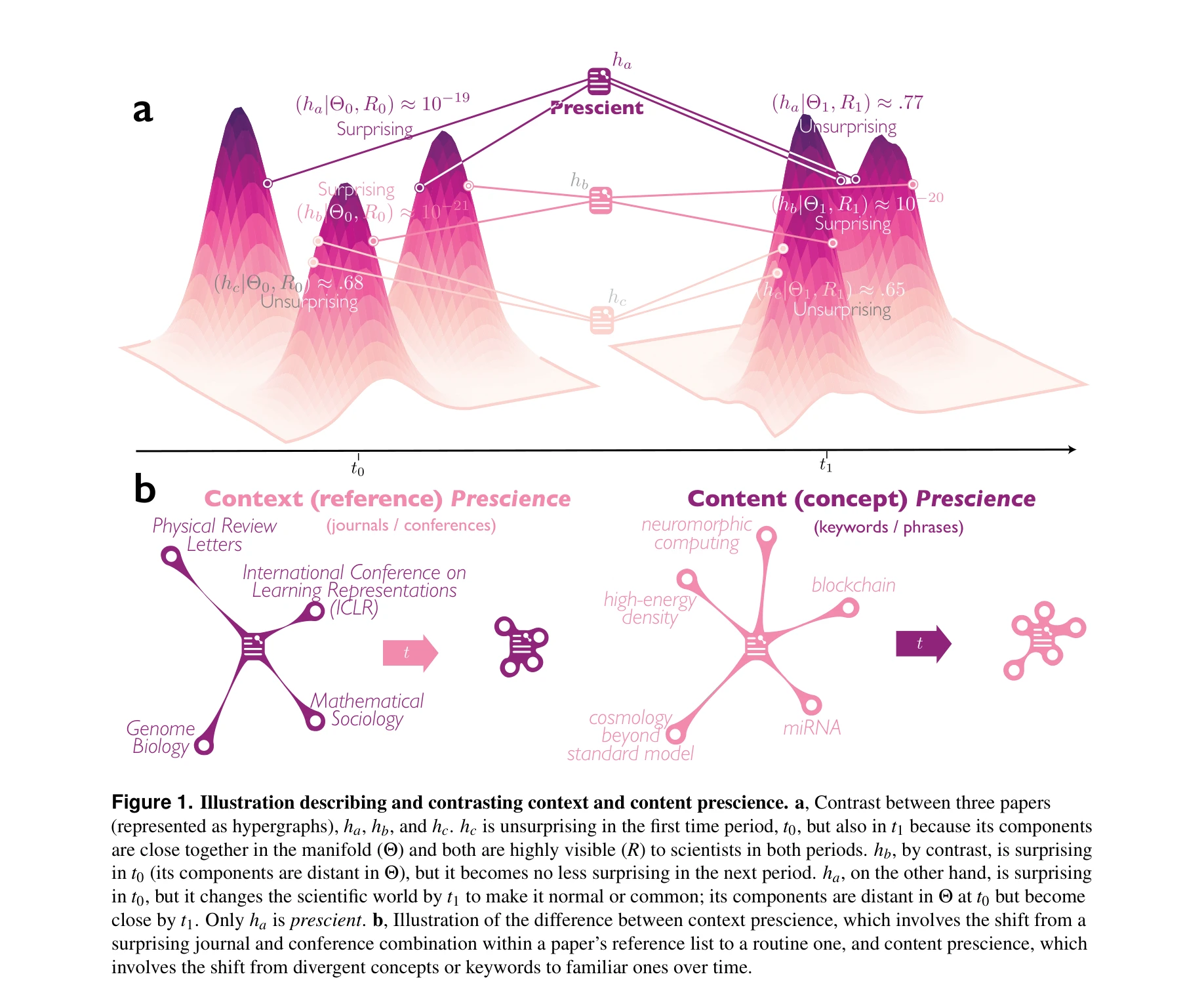
 *Figure 3 reveals striking gender differences in innovation patterns. Women’s work tends to be more innovative in context* 여성 과학자들은 남성과 다른 혁신 방식을 추구하며, 경계 횡단적 참고문헌 결합을 통한 맥락 혁신(context novelty)에서 더 뛰어나지만 과학 보상 체계가 이를 저평가한다.
본 연구는 과학 혁신의 성별 격차를 '능력 차이'가 아닌 '혁신 형태의 차이와 보상 구조의 불일치'로 재프레이밍하는 획기적인 통찰력을 제공하며, 경계 횡단 혁신이 과학 진보의 핵심임을 실증적으로 증명한다.
The Matthew effect in science funding
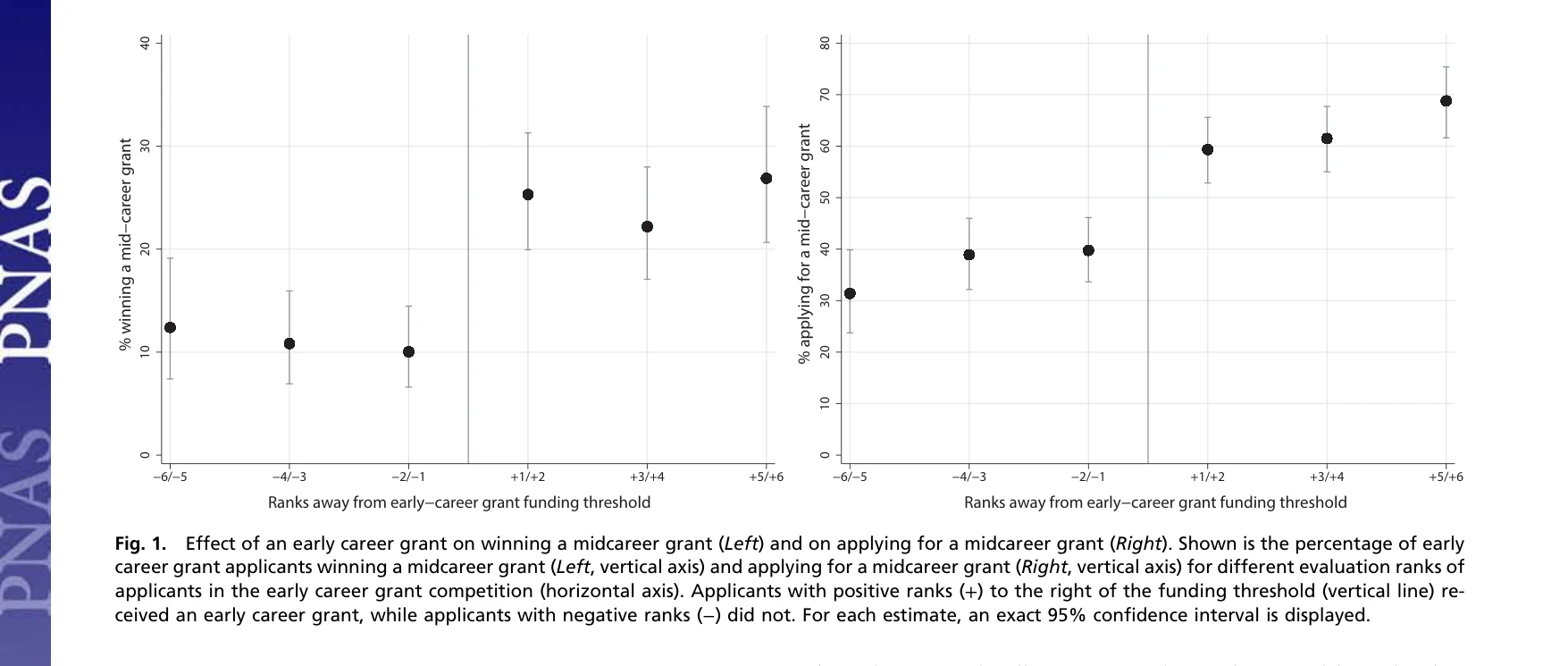
Fig. 1.
 *Fig. 1.* 과학 자금 배분에서 Matthew 효과(초기 성공이 이후 성공 확률을 높이는 현상)를 실증적으로 검증하여, 초기 자금 획득이 이후 8년간 2배 이상의 추가 자금 획득으로 이어짐을 보였다.
회귀 불연속 설계를 통해 Matthew 효과의 인과적 존재를 엄밀하게 입증하고, 참여 메커니즘이라는 새로운 생성 메커니즘을 제시한 우수한 실증 연구로, 과학 정책과 학술 경력 불평등 이해에 중요한 기여를 한다.
The Oligopoly of Academic Publishers in the Digital Era

Fig 1A presents, for Natural and Medical Sciences (NMS) and Social Sciences and Humanities
 *Fig 1A presents, for Natural and Medical Sciences (NMS) and Social Sciences and Humanities* 1973-2013년 4,500만 건의 논문을 분석하여 디지털 시대에 학술출판의 과점화(Oligopoly) 현상을 실증적으로 입증했다. Reed-Elsevier, Wiley-Blackwell, Springer, Taylor & Francis 등 상위 5개 출판사가 2013년 전체 논문의 50% 이상을 출판하고 있음을 보였다.
학술출판의 과점화 현상을 40년 장기 데이터로 처음 실증한 중요한 연구로, 학문분야별 편차를 명확히 규명했으나, WoS 색인 저널만 분석하고 메타데이터 정확성 이슈가 있다. 출판 생태계 정책 수립과 Open Access 운동의 학술적 근거를 제공하는 높은 실용적 가치를 지닌다.
Predicting research trends with semantic and neural networks with an application in quantum physics
Fig. 1.
 *Fig. 1.* 750,000개의 과학논문을 기반으로 시맨틱 네트워크(SEMNET)를 구축하여 양자물리학의 미래 연구 동향을 예측하고 혁신적인 연구 아이디어를 제안하는 방법론을 제시한다.
본 논문은 대규모 과학문헌으로부터 시맨틱 네트워크를 구축하고 신경망과 네트워크 이론을 결합하여 미래 연구 동향 예측 및 혁신적 아이디어 제안이라는 새로운 접근을 제시하는 의미 있는 연구이다. 양자물리학이라는 급속히 성장하는 분야에 적용하여 실용성을 입증했으나, 개념 추출 정확성 및 장기 예측 능력 개선을 통한 보완이 필요하다.
Quantifying large language model usage in scientific papers
Figure 1. The overall structure of our experiments. GPT4 was previously trained on data on a large fraction of the text
 *Figure 1. The overall structure of our experiments. GPT4 was previously trained on data on a large fraction of the text * GPT-4를 사용하여 유방암 치료를 위한 신약 조합을 가설로 생성하고 실험실에서 검증한 결과, 12개 중 3개의 조합이 양성 대조군을 초과하는 시너지 효과를 보였으며, 반복 실험에서 4개 중 3개가 추가로 확인되었다.
본 논문은 LLM의 할루시네이션을 과학적 창의성의 원천으로 재정의하고 실험적 검증으로 입증한 혁신적 연구이다. 신약 개발의 AI-인간-실험 협업 모델을 제시하며, 재현 가능성과 확장성 강화가 필요하다.
REFORMS: Consensus-based Recommendations for Machine-learning-based Science
기계학습 기반 과학 연구의 타당성, 재현성, 일반화 가능성 문제를 해결하기 위해 32개 항목으로 구성된 REFORMS 체크리스트를 개발하고, 8개 모듈별 상세 가이드라인을 제시한 합의 기반 권장사항.
본 논문은 ML 기반 과학의 재현성 위기를 해결하기 위해 다학제 전문가 합의를 바탕으로 개발한 REFORMS 체크리스트를 제시하여, 과학 커뮤니티에서 ML 도입의 신뢰성을 높이는 실질적이고 광범위하게 적용 가능한 도구를 제공한다.
Authorship, titles and open access as drivers of citation performance in orthopaedics: a scientometric analysis
정형외과 분야에서 저자 수, 논문 제목 특성, 개방 접근(Open Access) 여부가 인용 성과에 미치는 영향을 scientometric 분석으로 평가한 연구.
정형외과 분야의 대규모 scientometric 분석으로 협업, 개방 접근, 제목 구조가 인용 성과에 미치는 영향을 실증적으로 규명한 가치 있는 연구이며, 저자들이 윤리적 기준 유지의 중요성을 강조함으로써 단순한 메트릭 최적화를 넘는 균형잡힌 관점을 제시했다.
BibFusion: A Python package to integrate, deduplicate, and harmonize exported bibliographic records from Scopus and Web of Science for bibliometric analysis

Figure 1 provides a synopsis of the end-to-end
 *Figure 1 provides a synopsis of the end-to-end* BibFusion은 Scopus와 Web of Science의 서지 레코드를 통합, 중복 제거, 조화시켜 단일의 추적 가능한 분석 준비 코퍼스(corpus)를 생성하는 Python 패키지이다.
BibFusion은 Scopus-WoS 통합의 구조적 과제를 해결하는 재현 가능하고 감사 가능한 솔루션으로서, 명시적 ER 모델, 식별자 기반 보강, 투명한 감사 추적을 통해 과학계량 연구의 메타데이터 품질을 근본적으로 향상시킨다.
Citation Analysis as a Tool in Journal Evaluation
Science Citation Index(SCI) 데이터베이스를 이용하여 저널 인용 패턴을 체계적으로 분석하고, 인용 빈도와 영향력으로 저널을 평가하는 방법론을 제시한다.
본 논문은 Science Citation Index의 대규모 기계 가독 데이터를 처음으로 체계적으로 활용하여 과학 저널 평가의 새로운 방법론을 제시하였으며, 컴퓨터 기반 분석으로 기존의 수작업 한계를 극복하여 과학 정보학 분야에 매우 높은 기여도를 갖는다.
Design and Update of a Classification System: The UCSD Map of Science
Figure 1. Visualizations of the UCSD Map: 2D Mercator projection (left) with three 3D spherical insets (top), 1D circula
 *Figure 1. Visualizations of the UCSD Map: 2D Mercator projection (left) with three 3D spherical insets (top), 1D circula* 본 논문은 과학 전체를 포괄하는 분류 체계인 UCSD Map of Science를 설계하고 업데이트한 과정을 상세히 기술하며, 원본 5년 데이터 기반 지도를 10년 데이터로 확장하여 학문 분야의 구조를 시각화하고 분석한다.
본 논문은 과학 지도 설계의 실무적 노하우를 상세히 제시하고 장기 데이터를 통한 체계적인 업데이트를 최초로 수행한 중요한 기여를 한다. 다만 기술적 혁신보다는 기존 방법론의 신중한 적용과 포괄적인 비교 분석이 주요 강점이며, 학제 간 연구 및 정책 결정을 지원하는 실용적 가치가 매우 높다.
Estimating the Reproducibility of Psychological Science
심리학 분야 100개 발표 논문의 재현 연구를 수행한 결과, 재현 효과 크기가 원본의 절반 수준으로 나타나 심리학 연구의 재현성이 심각한 수준임을 실증적으로 규명했다.
본 논문은 심리학 연구의 재현 위기를 최초로 대규모 체계적으로 실증한 획기적 연구로, 학문의 신뢰성 재검토와 방법론 개선의 필요성을 강력하게 제시했다. 이는 심리학뿐만 아니라 전체 학문 공동체의 개혁을 촉발한 매우 영향력 있는 연구이다.
Evaluating the Replicability of Social Science Experiments in Nature and Science
Fig. 1 | Replication results after stage 1 and stage 2. a, Plotted are the 95% CIs of the replication effect sizes (stan
 *Fig. 1 | Replication results after stage 1 and stage 2. a, Plotted are the 95% CIs of the replication effect sizes (stan* 2010-2015년 Nature와 Science에 발표된 사회과학 실험 21개를 체계적으로 재현한 결과, 62%만이 원래 방향의 유의미한 효과를 보였으며 평균 효과크기는 원래의 50% 수준임을 보고한다.
이 연구는 최고 권위 저널의 사회과학 실험이 예상보다 낮은 재현율(62%)과 감소된 효과크기(50%)를 보임을 체계적으로 입증하여 과학 출판과 방법론의 신뢰성 문제를 중요하게 조명했으며, 사전 등록과 투명한 재현 프로토콜이 과학 커뮤니티 표준이 되도록 기여한 중요한 메타과학 연구이다.
Introducing multiverse analysis to bibliometrics: The case of team size effects on disruptive research
Figure 1 shows the range and the density of estimates from the multiverse of 180 equally
 *Figure 1 shows the range and the density of estimates from the multiverse of 180 equally* 본 논문은 통계적 모델 불확실성을 체계적으로 측정하는 다중우주분석(multiverse analysis)을 서지학에 처음 도입하여, 팀 규모가 혁신적 연구에 미치는 영향에 대한 기존 연구들의 상충하는 결과를 재평가한다.
본 논문은 서지학에 다중우주분석을 도입함으로써 모델 불확실성을 체계적으로 다루는 새로운 방법론을 제시하며, 상충된 선행 연구를 통합적으로 평가하여 서지학 연구의 투명성과 신뢰성을 크게 향상시킨다.
OpenAlex in focus: Metadata quality of publication type and language fields in an open peer review corpus
Figure 1 illustrates the differences between the Assigned Type (OpenAlex) and the Verified Type
 *Figure 1 illustrates the differences between the Assigned Type (OpenAlex) and the Verified Type* OpenAlex의 메타데이터 품질을 문헌 유형(publication type)과 언어(language) 필드 중심으로 분석하여, 6,640개 오픈 피어 리뷰 관련 논문에서 43%의 유형 불일치와 3.3%의 언어 불일치를 발견했다.
본 연구는 OpenAlex의 메타데이터 품질 문제를 구체적이고 정량적으로 입증함으로써, 해당 데이터베이스 사용 전 체계적 정제의 필요성을 강조한다. 문헌계량 및 오픈 사이언스 연구 커뮤니티에 실질적인 경고 신호를 제공하며, 오픈 인프라의 신뢰성 확보를 위한 개선 방향을 시사한다.
Category Overview
# AI for Science 카테고리 "Other" (1편) 개요 과학 커뮤니케이션(science communication)의 디지털화 시대에 정보 경로(information pathways)와 온라인 플랫폼의 역할이 점차 중요해지고 있습니다. [974]는 온라인 환경에서 과학 정보가 어떻게 전파되고 수용되는지에 대한 핵심적인 질문들을 다루고 있습니다. 이 연구는 소셜 미디어(social media)와 디지털 네트워크를 통한 과학 지식의 확산 메커니즘을 분석함으로써, 과학적 신뢰성(scientific credibility)과 대중의 이해도 사이의 관계를 규명합니다. 특히 온라인 과학 커뮤니케이션 환경에서 정보 신뢰성과 도달 범위 간의 긴장 관계를 조명합니다. 본 주제는 과학 교육(science education), 공중 보건 커뮤니케이션(public health communication), 그리고 과학 정책(science policy) 수립에 있어 중요한 함의를 제공합니다. 이러한 연구들은 더욱 효과적이고 책임감 있는 온라인 과학 커뮤니케이션 전략 개발에 기여할 수 있습니다.
Emergence of Scaling in Random Networks
실제 네트워크들이 공통적으로 보이는 멱법칙 분포(scale-free power-law distribution)는 네트워크 성장과 선호적 부착(preferential attachment)이라는 두 가지 메커니즘으로부터 자연스럽게 나타난다.
이 논문은 스케일-프리 네트워크(scale-free network) 개념을 처음 정식화하고, 성장과 선호적 부착이라는 단순한 메커니즘으로 복잡한 실제 네트워크의 멱법칙 분포를 설명함으로써 네트워크 과학 분야의 기초를 확립한 획기적 작업이다.
Robust Evidence for Declining Disruptiveness: Assessing the Role of Zero-Backward-Citation Works
Figure 1: Declining Disruptiveness Matches Major Benchmark Transformations in Science After Excluding Zero-
 *Figure 1: Declining Disruptiveness Matches Major Benchmark Transformations in Science After Excluding Zero-* Park et al.의 과학 파괴성(disruptiveness) 감소 연구에 대한 Holst et al.의 비판에 대응하며, 영인용(zero-backward-citation) 논문을 제외해도 실질적이고 통계적으로 유의미한 감소가 나타남을 보여준다.
과학 계량 분석에서 메타데이터 품질과 방법론의 중요성을 명확히 드러내며, 비판자의 회귀모델 자체가 원래 주장을 반박하는 결과를 제시함으로써 과학의 파괴성 감소라는 원본 연구의 견고성을 강하게 재확인한다.
The Open Catalyst 2022 (OC22) Dataset and Challenges for Oxide Electrocatalysts
Figure 1: Adsorbates, materials, calculations,
 *Figure 1: Adsorbates, materials, calculations,* OC20 데이터셋은 1.2백만 개 이상의 DFT 완화 계산을 포함하는 촉매 발견을 위한 대규모 오픈소스 데이터셋이며, 그래프 신경망 모델들의 성능 벤치마크와 커뮤니티 챌린지를 제공한다.
OC20은 촉매 발견을 위한 ML 응용 분야에서 혁신적인 대규모 공개 데이터셋으로, 명확한 도메인 챌린지와 함께 그래프 신경망 기반 모델 개발을 크게 촉진할 수 있는 중요한 리소스이다.
BibFusion: A Python package to integrate, deduplicate, and harmonize exported bibliographic records from Scopus and Web of Science for bibliometric analysis
Figure 1 provides a synopsis of the end-to-end
 *Figure 1 provides a synopsis of the end-to-end* BibFusion은 Scopus와 Web of Science의 서지 레코드를 통합, 중복 제거, 조화시켜 단일의 추적 가능한 분석 준비 코퍼스(corpus)를 생성하는 Python 패키지이다.
BibFusion은 Scopus-WoS 통합의 구조적 과제를 해결하는 재현 가능하고 감사 가능한 솔루션으로서, 명시적 ER 모델, 식별자 기반 보강, 투명한 감사 추적을 통해 과학계량 연구의 메타데이터 품질을 근본적으로 향상시킨다.
Community Detection in Graphs
그래프에서 커뮤니티 구조(community structure)를 검출하는 문제를 종합적으로 분석하고, 통계물리학 기반 방법론들을 중심으로 다양한 탐지 알고리즘들을 체계적으로 정리한 포괄적 리뷰 논문이다.
이 논문은 커뮤니티 검출 문제를 최초로 종합적으로 정리한 영향력 있는 리뷰로, 다양한 방법론의 통일된 이해를 제공하며 분야의 표준 참고문헌이 되었다. 다만 계산 확장성과 일부 미해결 이론적 문제들은 향후 연구 과제로 남아 있다.
Fast Unfolding of Communities in Large Networks
Figure 1. Visualization of the steps of our algorithm. Each pass is made of two phases:
 *Figure 1. Visualization of the steps of our algorithm. Each pass is made of two phases:* 대규모 네트워크에서 모듈성(modularity) 최적화 기반의 빠른 커뮤니티 검출 알고리즘을 제안하며, 선형에 가까운 시간복잡도로 수백만 개 노드를 처리할 수 있다.
매우 효율적이고 실용적인 커뮤니티 검출 알고리즘으로, 선형에 가까운 복잡도와 계층적 구조 해석 능력을 통해 대규모 네트워크 분석 분야에서 획기적 기여를 한다. 명확한 방법론과 강력한 실험 검증이 돋보이는 우수한 논문이다.
Information Pathways in Online Science Communication: The Role of Platform Actors and News Media
Figure 1: Network of coordinated accounts based on co-
 *Figure 1: Network of coordinated accounts based on co-* COVID-19 팬데믹을 사례로 1.24M 트윗과 211k 뉴스 기사를 분석하여 과학 논문의 정보 경로(information pathways)를 추적하고, 소셜 미디어 슈퍼스프레더(superspreaders)와 뉴스 미디어 간의 상호작용 구조를 규명한 연구이다.
이 논문은 COVID-19 과학 소통 생태계를 다층적으로 분석하여 소셜 미디어 슈퍼스프레더와 뉴스 미디어 간의 상호 강화 구조와 부실정보 증폭 메커니즘을 규명함으로써, 온라인 정보 생태계에 대한 혁신적 이해를 제공한다. 다만 인과관계 미확립과 사례 제한성에 대해 추가 검증이 필요하다.
Open Datasets in Learning Analytics: Trends, Challenges, and Best PRACTICE
Fig. 1. PRISMA flow diagram. Generated using the tool by Haddaway et al. [146].
 *Fig. 2. Distributions of dataset frequency across educational topics and levels of students.* 본 논문은 학습분석(Learning Analytics), 교육데이터마이닝(Educational Data Mining), 교육용 AI의 세 분야에서 공개 데이터셋의 현황을 파악하고, 데이터 공유 모범 사례를 제시하는 체계적 조사 연구이다.
본 논문은 학습분석 커뮤니티의 공개 데이터 현황에 대한 가장 포괄적이고 최신의 체계적 조사 연구이며, 실질적인 PRACTICE 지침 제공과 신규 데이터셋 인벤토리 공개를 통해 학습분석 분야의 개방 과학 실천을 촉진하는 중요한 기여를 한다.
Organisational accounts engaged in scholarly communication on Twitter: Patterns of presence, activity and engagement
Figure 1 presents the workflow used to identify organisational accounts that tweeted
 *Figure 2 shows the distribution of these accounts across the seven organisational* 트위터에서 학술 출판물에 대해 트윗한 9,842개 조직 계정(organizational accounts)을 식별하고, 이들의 소셜 미디어 자본(social media capital), 트윗 활동, 참여 수준의 패턴을 분석한 연구이다.
이 연구는 학술 커뮤니케이션에서 조직이 하는 중요한 역할을 체계적으로 규명하고, 재사용 가능한 공개 데이터셋을 제공함으로써 altmetrics 분야에 실질적인 기여를 한다. 다만 단일 플랫폼 분석과 기술적 깊이 면에서 개선의 여지가 있다.