Essence

Figure 1: Adsorbates, materials, calculations,
촉매 발견을 가속화하기 위해 1.28백만 개의 DFT 계산을 포함한 OC20 데이터셋과 3개의 도메인 챌린지 과제를 제시하여 머신러닝 모델의 일반화 능력 향상을 목표로 함.
저자: Lowik Chanussot, Abhishek Das, Siddharth Goyal, Thibaut Lavril, Muhammed Shuaibi, Morgane Riviere, Kevin Tran, Javier Heras-Domingo, Caleb Ho, Weihua Hu, Aini Palizhati, Anuroop Sriram, Brandon Wood, Junwoong Yoon, Devi Parikh, C. Lawrence Zitnick, Zachary Ulissi | 날짜: 2021-05-21 | DOI: 10.1021/acscatal.0c04525
Figure 1: Adsorbates, materials, calculations,
촉매 발견을 가속화하기 위해 1.28백만 개의 DFT 계산을 포함한 OC20 데이터셋과 3개의 도메인 챌린지 과제를 제시하여 머신러닝 모델의 일반화 능력 향상을 목표로 함.
Figure 1: Adsorbates, materials, calculations,
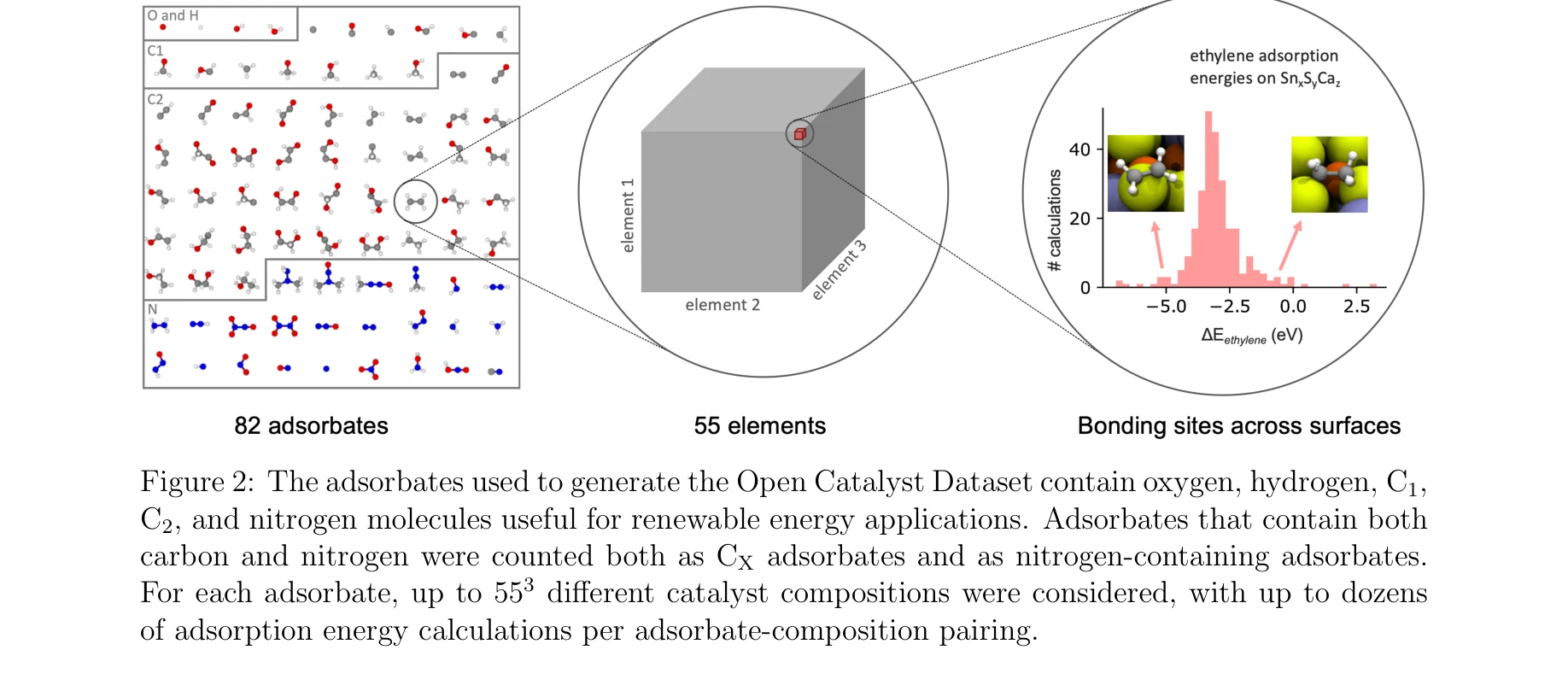
Figure 2: The adsorbates used to generate the Open Catalyst Dataset contain oxygen, hydrogen, C1,
총평: 촉매 머신러닝 분야에서 획기적인 대규모 데이터셋을 제공하고 명확한 벤치마크 과제와 공개 인프라를 제시하여 커뮤니티 기반 모델 개발을 촉진하는 핵심 기여이나, 단순화된 모델 가정이 실제 촉매 응용으로의 전이 시 한계가 있을 수 있음.