Essence
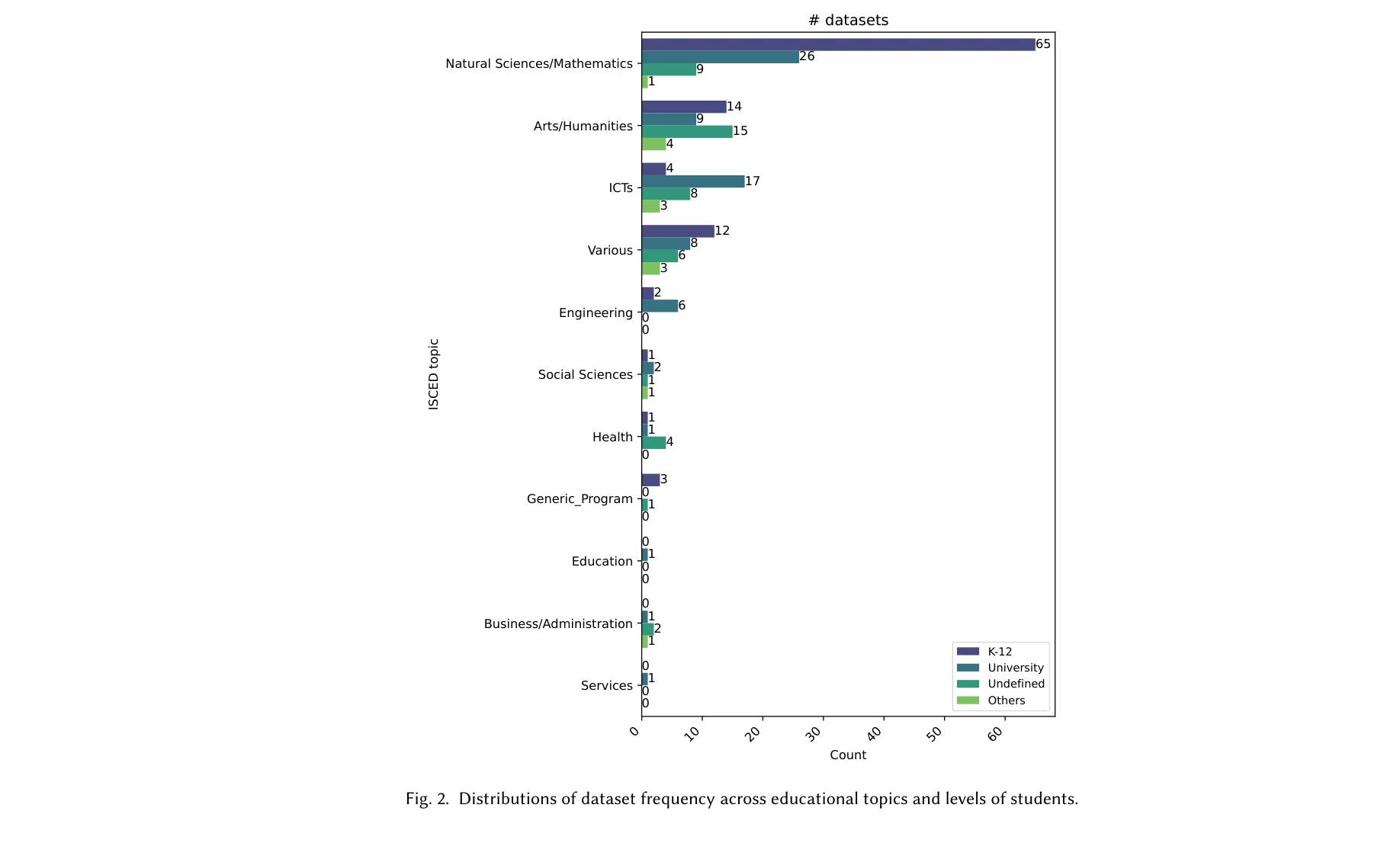
Fig. 2. Distributions of dataset frequency across educational topics and levels of students.
본 논문은 학습분석(Learning Analytics), 교육데이터마이닝(Educational Data Mining), 교육용 AI의 세 분야에서 공개 데이터셋의 현황을 파악하고, 데이터 공유 모범 사례를 제시하는 체계적 조사 연구이다.
저자: Valdemar Švábenský, Brendan Flanagan, Erwin Daniel López Zapata, Atsushi Shimada | 날짜: 2026-02-19 | DOI: 10.1145/3798096
Fig. 2. Distributions of dataset frequency across educational topics and levels of students.
본 논문은 학습분석(Learning Analytics), 교육데이터마이닝(Educational Data Mining), 교육용 AI의 세 분야에서 공개 데이터셋의 현황을 파악하고, 데이터 공유 모범 사례를 제시하는 체계적 조사 연구이다.
Fig. 2. Distributions of dataset frequency across educational topics and levels of students.
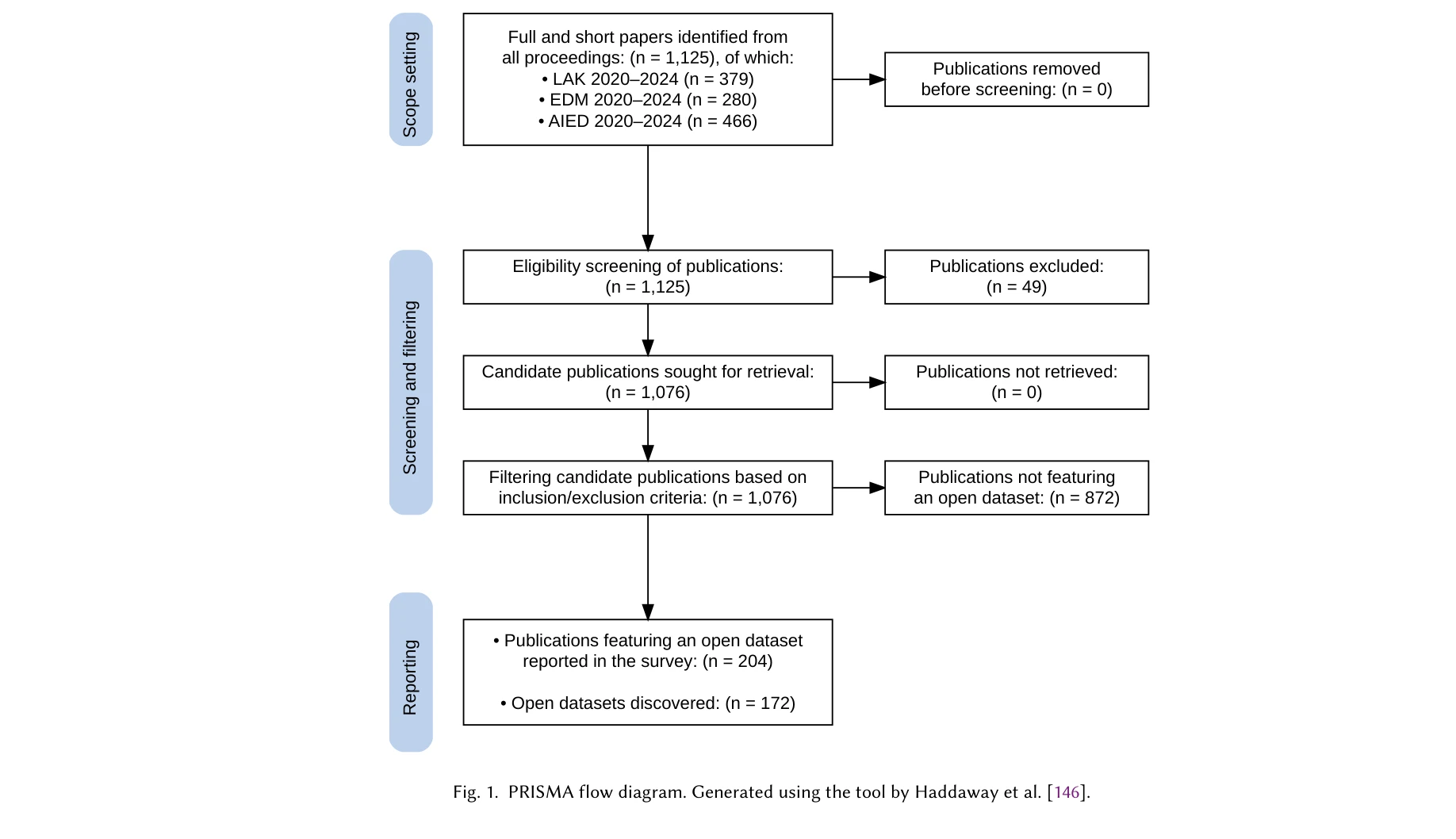
Fig. 1. PRISMA flow diagram. Generated using the tool by Haddaway et al. [146].
총평: 본 논문은 학습분석 커뮤니티의 공개 데이터 현황에 대한 가장 포괄적이고 최신의 체계적 조사 연구이며, 실질적인 PRACTICE 지침 제공과 신규 데이터셋 인벤토리 공개를 통해 학습분석 분야의 개방 과학 실천을 촉진하는 중요한 기여를 한다.