Essence

Figure 1: Accuracy score progression of OLMo-7B on 8 core end-tasks score from Catwalk evaluation suite
OLMo는 훈련 데이터, 훈련 코드, 평가 도구까지 모두 공개한 완전 개방형 언어 모델(Open Language Model)이다. 이를 통해 언어 모델에 대한 과학적 연구를 가능하게 한다.
저자: Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi | 날짜: 2024-06-07 | DOI: 10.48550/arXiv.2402.00838
Figure 1: Accuracy score progression of OLMo-7B on 8 core end-tasks score from Catwalk evaluation suite
OLMo는 훈련 데이터, 훈련 코드, 평가 도구까지 모두 공개한 완전 개방형 언어 모델(Open Language Model)이다. 이를 통해 언어 모델에 대한 과학적 연구를 가능하게 한다.
Figure 1: Accuracy score progression of OLMo-7B on 8 core end-tasks score from Catwalk evaluation suite
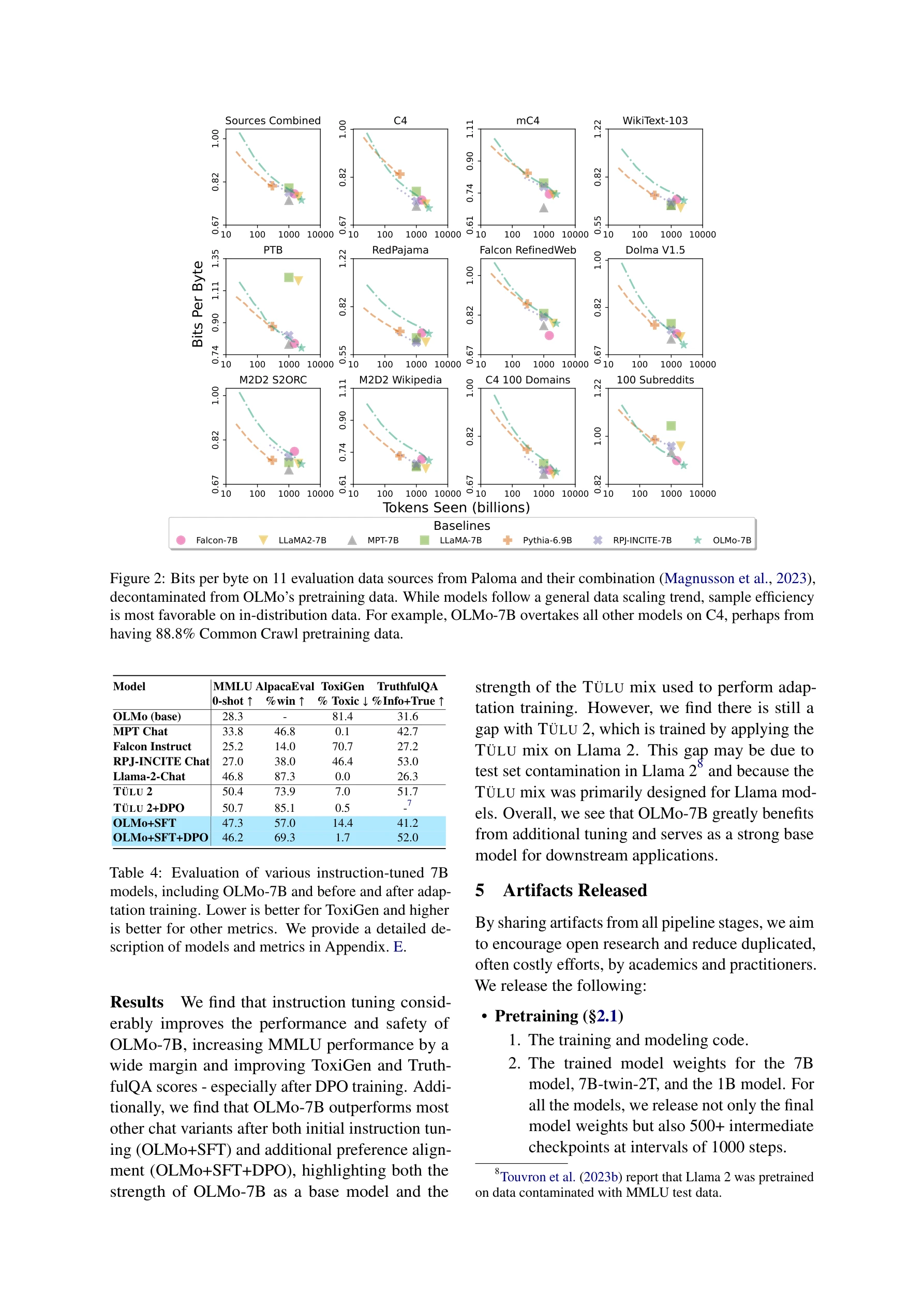
Figure 2: Bits per byte on 11 evaluation data sources from Paloma and their combination (Magnusson et al., 2023),
총평: OLMo는 진정한 의미의 완전 개방형 언어 모델을 제공함으로써 언어 모델 연구의 투명성과 재현성을 획기적으로 향상시킨다. 데이터, 코드, 도구까지 모두 공개하는 이 종합적인 접근은 학술 커뮤니티에 큰 기여를 하며 향후 언어 모델 연구의 새로운 방향을 제시한다.