저자: Weixin Liang, Yaohui Zhang, Zhengxuan Wu, Haley Lepp, Wenlong Ji, Xuandong Zhao, Hancheng Cao, Sheng Liu, Siyu He, Zhi Huang, Diyi Yang, Christopher Potts, Christopher D. Manning, James Zou | 날짜: 2025-08-04 | DOI: 10.1038/s41562-025-02273-8
Essence
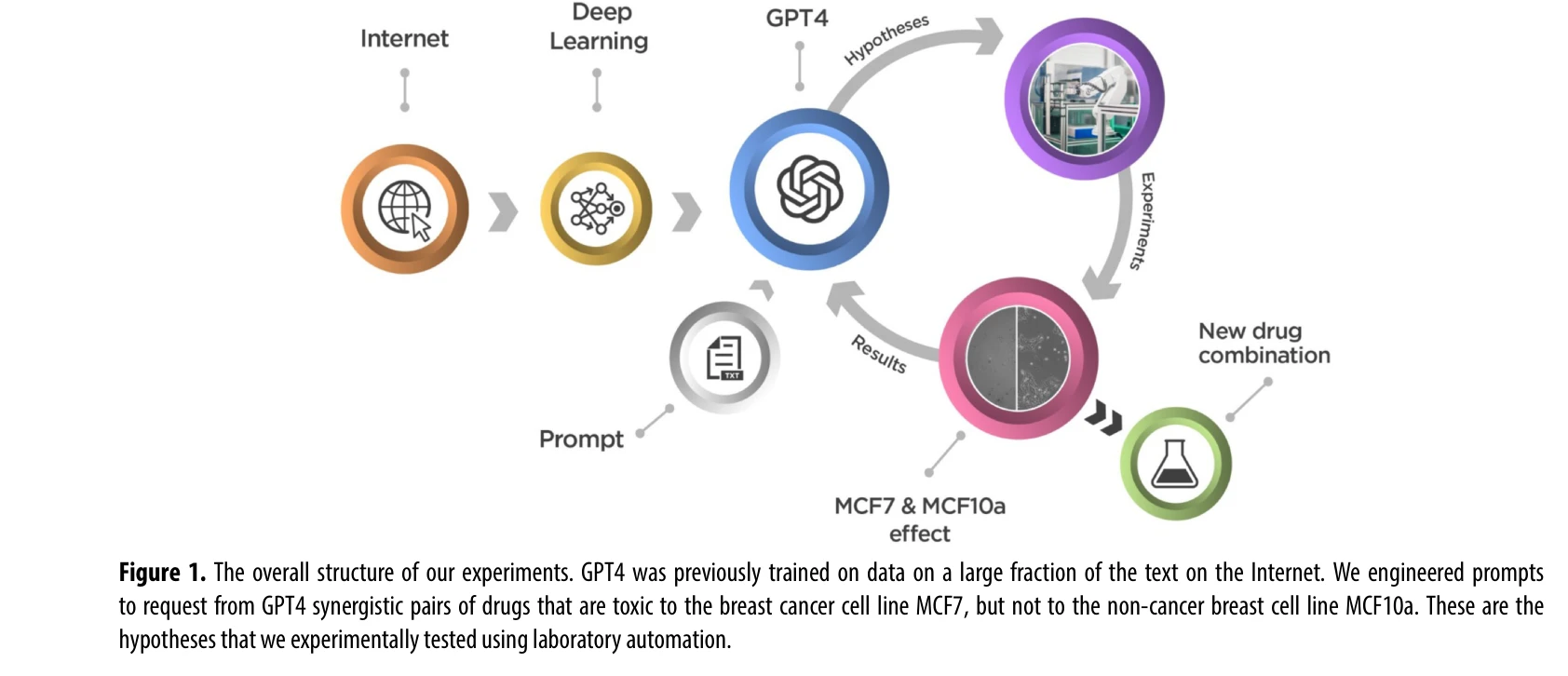
Figure 1. The overall structure of our experiments. GPT4 was previously trained on data on a large fraction of the text
GPT-4를 사용하여 유방암 치료를 위한 신약 조합을 가설로 생성하고 실험실에서 검증한 결과, 12개 중 3개의 조합이 양성 대조군을 초과하는 시너지 효과를 보였으며, 반복 실험에서 4개 중 3개가 추가로 확인되었다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 LLM의 할루시네이션을 과학적 창의성의 원천으로 재정의하고 실험적 검증으로 입증한 혁신적 연구이다. 신약 개발의 AI-인간-실험 협업 모델을 제시하며, 재현 가능성과 확장성 강화가 필요하다.