Essence
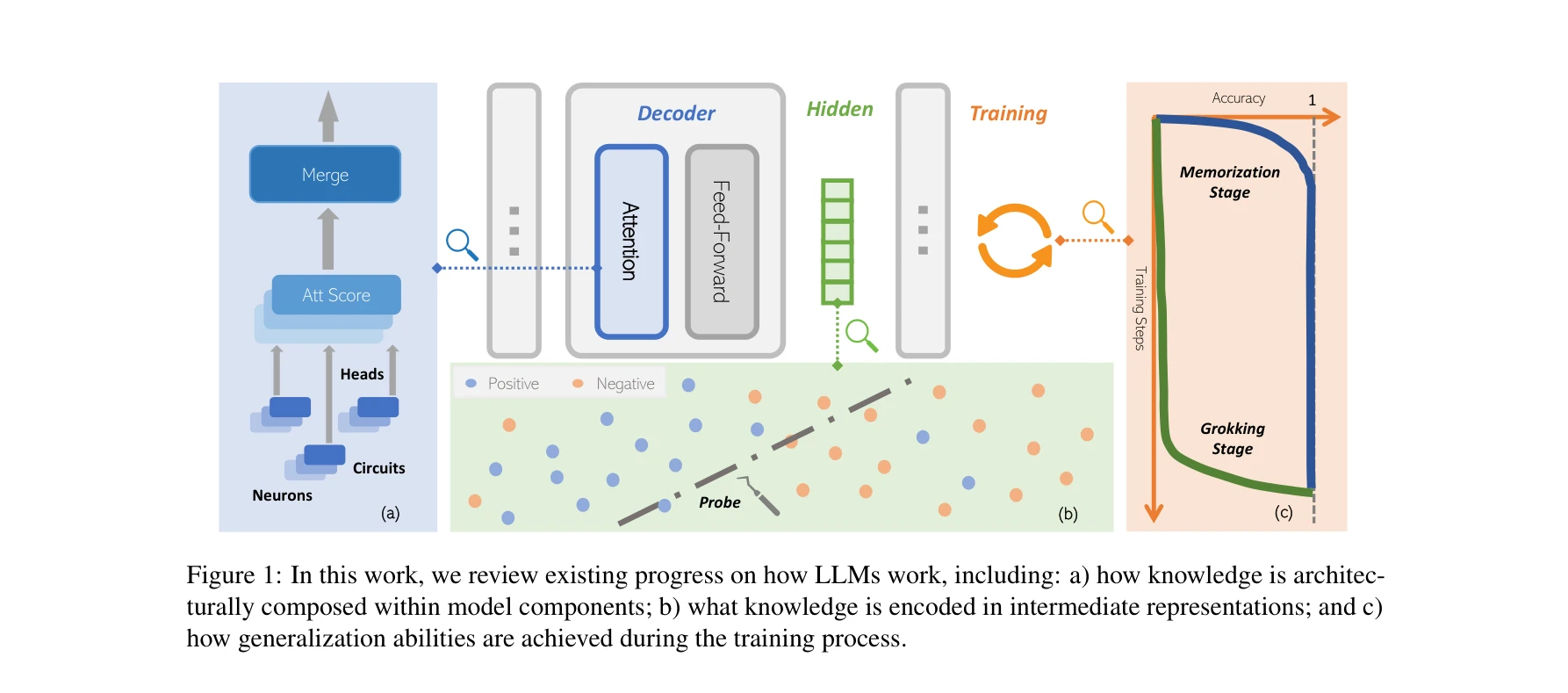
대규모 언어모델의 작동 메커니즘: (a) 모델 컴포넌트 내 지식의 아키텍처 구성, (b) 중간 표현에 인코딩된 지식, (c) 훈련 과정에서의 일반화 능력 발달
이 논문은 설명가능성(explainability) 관점에서 대규모 언어모델(LLM)의 내부 작동 메커니즘을 체계적으로 검토한 종합 리뷰 논문이다. 기계적 해석가능성(mechanistic interpretability), 표현 공학(representation engineering), 훈련 역학 분석을 통해 LLM의 지식 구성, 부호화, 학습 과정을 밝히고, 이러한 인사이트가 모델 편집, 프루닝, 인간 정렬에 어떻게 활용될 수 있는지 보여준다.
