How

LLM-driven Dataset Simulation: 개체 리스트와 속성이 주어졌을 때, 각 (개체, 속성) 조합에 대해 LLM을 쿼리하여 속성값 추정
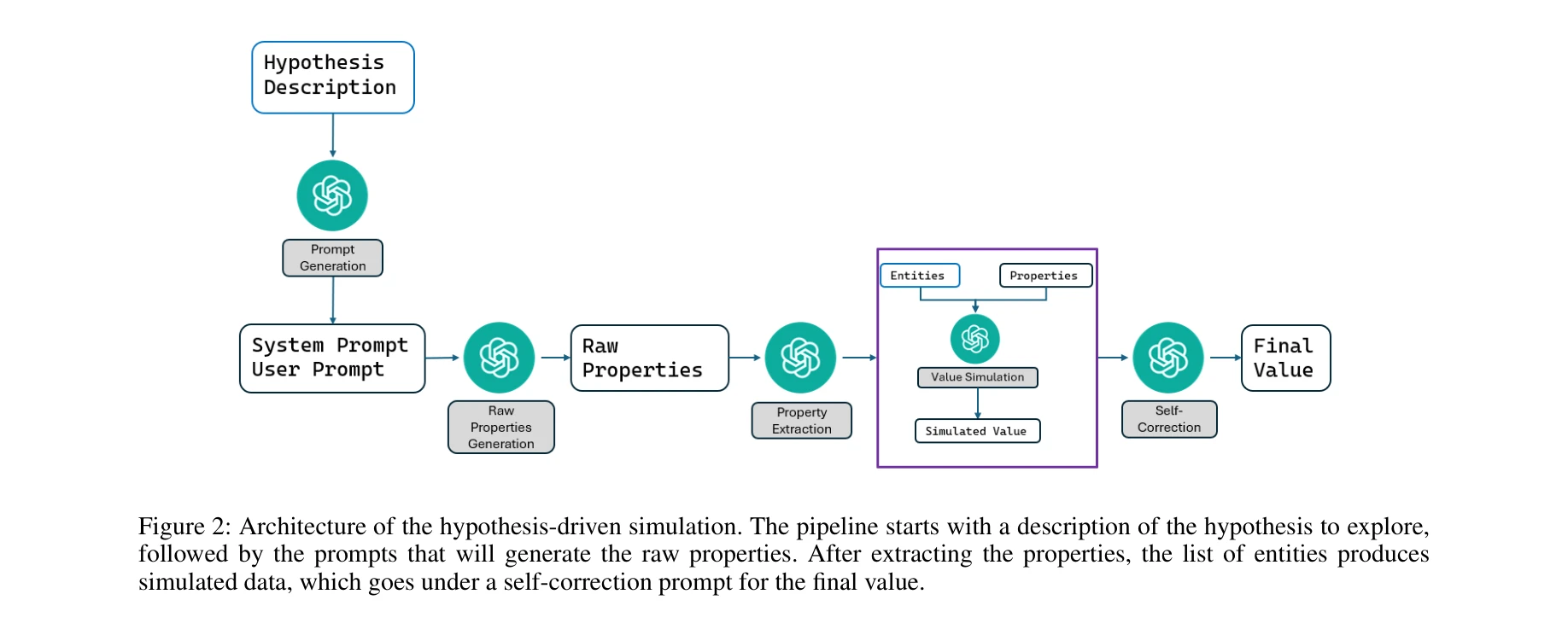
Hypothesis-driven Dataset Simulation 파이프라인: 고수준 가설 설명에서 시작하여 속성 생성, 개체 리스트 구성, 데이터셋 시뮬레이션까지 자동화
방법론
- LLM-driven Dataset Simulation:
- 입력: 구체적 개체 리스트(예: 100명의 공포 소설가), 속성 리스트(예: 부모 이혼 여부, ACE 점수)
- 처리: 각 (개체, 속성) 조합마다 LLM에 쿼리하여 추정값 획득
- 출력: 표 형식의 시뮬레이션 데이터셋
- Hypothesis-driven Dataset Simulation:
- Prompt Generation: 실험자의 가설 설명을 입력받아 LLM이 시스템 프롬프트와 사용자 프롬프트 자동 생성
- Property Simulation: 생성된 프롬프트를 통해 자유형식 텍스트로 속성 정의 및 가능한 값 범위 기술
- Property Parsing: 자유형식 텍스트를 구조화된 형식(속성명, 설명, 가능값)으로 파싱
- Self-Correction: LLM이 자신의 속성값 추정을 재검토하고 오류 수정(hallucination 감소 목표)
- 다양한 도메인 실험:
- 동물의 이진 특성(동물원 데이터셋): 간단한 baseline
- 국가의 다중값 속성: 더 복잡한 도메인
- 운동선수의 속성: 인물 관련 데이터