Essence

아리스토텔레스의 인용구와 함께 시각화 설명의 중요성을 강조하는 그림. 버블 정렬 예시로 텍스트 설명과 시각적 설명의 이해도 차이를 보여줌
정리(Theorem) 이해를 위해 LLM이 5분 이상의 긴 형식 설명 비디오를 에이전트 기반으로 생성하는 새로운 접근법을 제시하며, 다중 모드 설명이 텍스트 기반 평가보다 더 깊은 추론 오류를 드러낼 수 있음을 입증한다.
저자: Max Ku, C.P. Chong, Jonathan Leung, Krish Shah, Ai‐Ming Yu, Wenhu Chen | 날짜: 2025 | DOI: 미제공
아리스토텔레스의 인용구와 함께 시각화 설명의 중요성을 강조하는 그림. 버블 정렬 예시로 텍스트 설명과 시각적 설명의 이해도 차이를 보여줌
정리(Theorem) 이해를 위해 LLM이 5분 이상의 긴 형식 설명 비디오를 에이전트 기반으로 생성하는 새로운 접근법을 제시하며, 다중 모드 설명이 텍스트 기반 평가보다 더 깊은 추론 오류를 드러낼 수 있음을 입증한다.
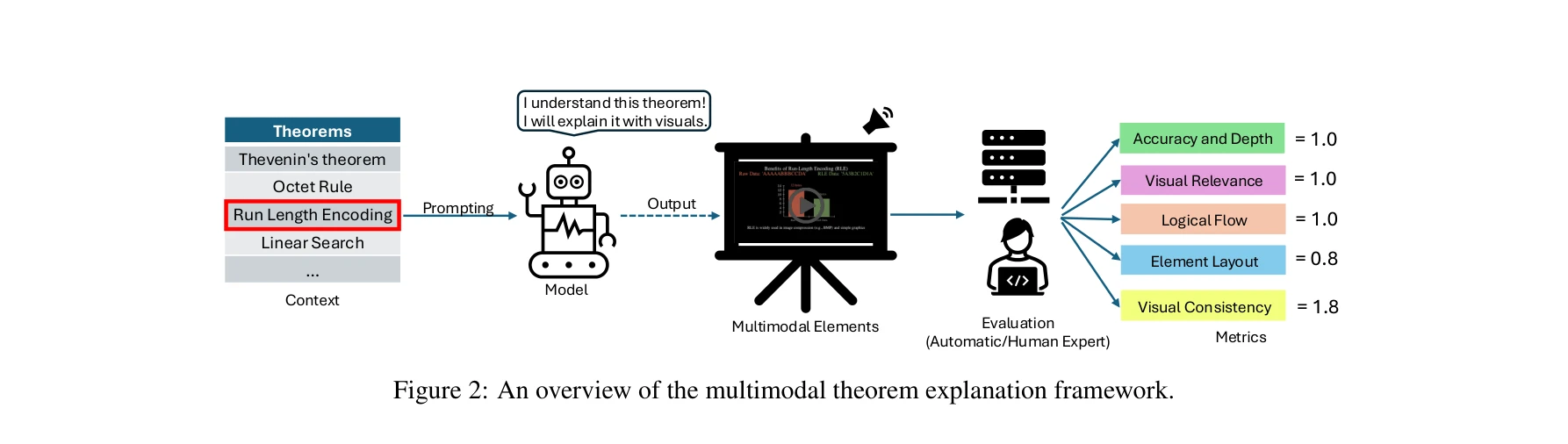
다중 모드 정리 설명 프레임워크 개요. 정리 입력부터 정확도/심화도, 시각적 관련성, 논리적 흐름, 요소 레이아웃, 시각적 일관성 등 5개 평가 지표 산출까지의 파이프라인
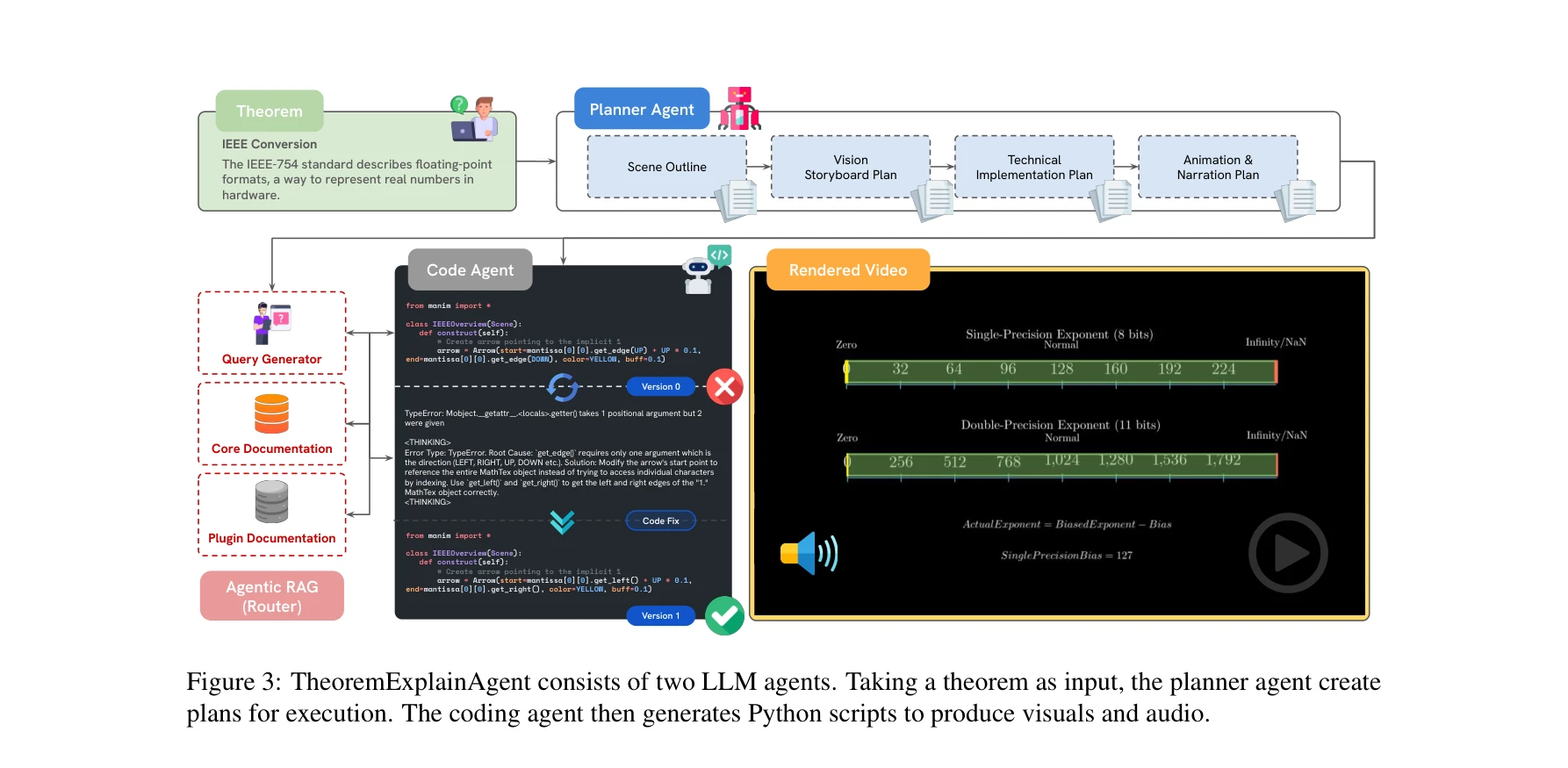
TheoremExplainAgent의 두 에이전트 구조. 플래너 에이전트가 비전, 스토리보드, 애니메이션·나레이션, 기술 구현 계획을 생성하고, 코딩 에이전트가 에이전트 RAG를 통해 Manim 코드를 생성 및 디버깅함. IEEE 변환 예시에서 TypeError 해결 과정 표시
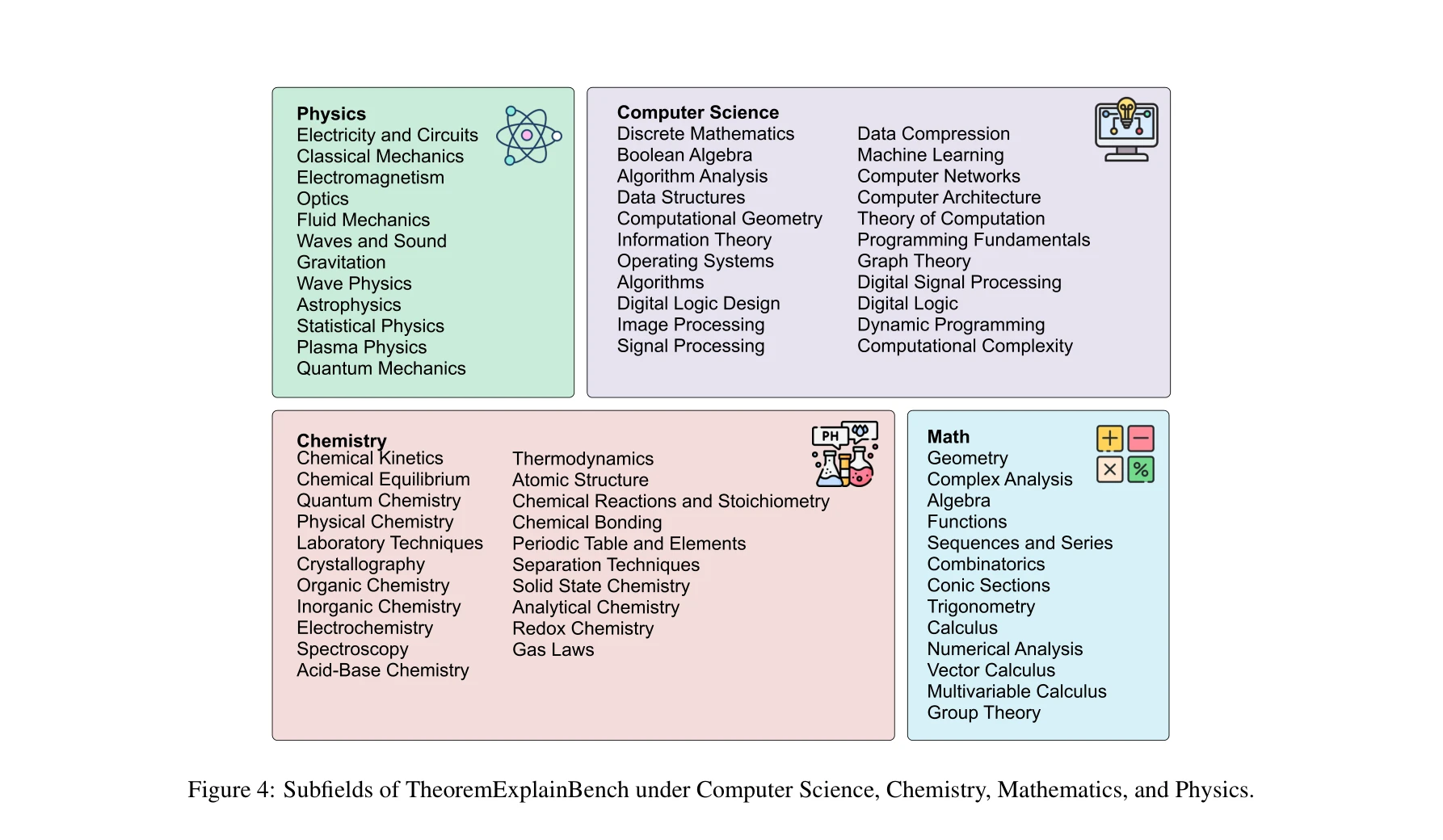
TheoremExplainBench가 포함하는 컴퓨터과학, 화학, 수학, 물리의 세부 분야. 각 분야별 14-32개 하위 주제 카테고리 포함
시스템 아키텍처:
평가 메트릭 (5개 차원):
벤치마크 구성: