Essence
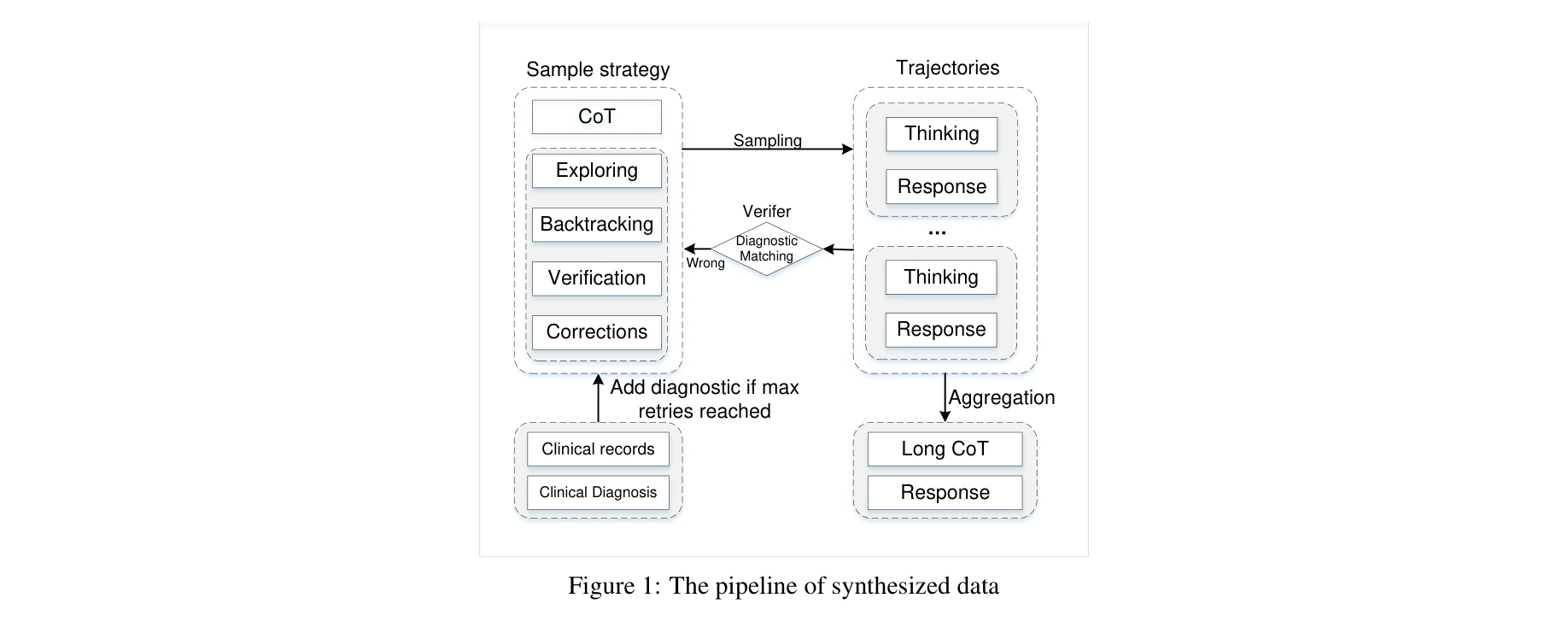
그림 1: 합성 데이터 생성 파이프라인
본 논문은 실제 임상 기록을 기반으로 한 20,000개의 임상 데이터셋에서 학습하여, 질병 진단에서 추론 능력을 강화한 의료 특화 대규모 언어모델(LLM) ClinicalGPT-R1을 제시한다. 지도학습 미세조정(SFT)과 강화학습(RL)의 두 단계 학습을 통해 진단 추론 능력을 향상시키며, 중국어 진단 작업에서 GPT-4o를 능가하는 성능을 달성한다.
저자: Wuyang Lan, Wenzheng Wang, Changwei Ji, Guoxing Yang, Yongbo Zhang, Xiaohong Liu, Song Wu, Guangyu Wang | 날짜: 2025 | DOI: N/A
그림 1: 합성 데이터 생성 파이프라인
본 논문은 실제 임상 기록을 기반으로 한 20,000개의 임상 데이터셋에서 학습하여, 질병 진단에서 추론 능력을 강화한 의료 특화 대규모 언어모델(LLM) ClinicalGPT-R1을 제시한다. 지도학습 미세조정(SFT)과 강화학습(RL)의 두 단계 학습을 통해 진단 추론 능력을 향상시키며, 중국어 진단 작업에서 GPT-4o를 능가하는 성능을 달성한다.
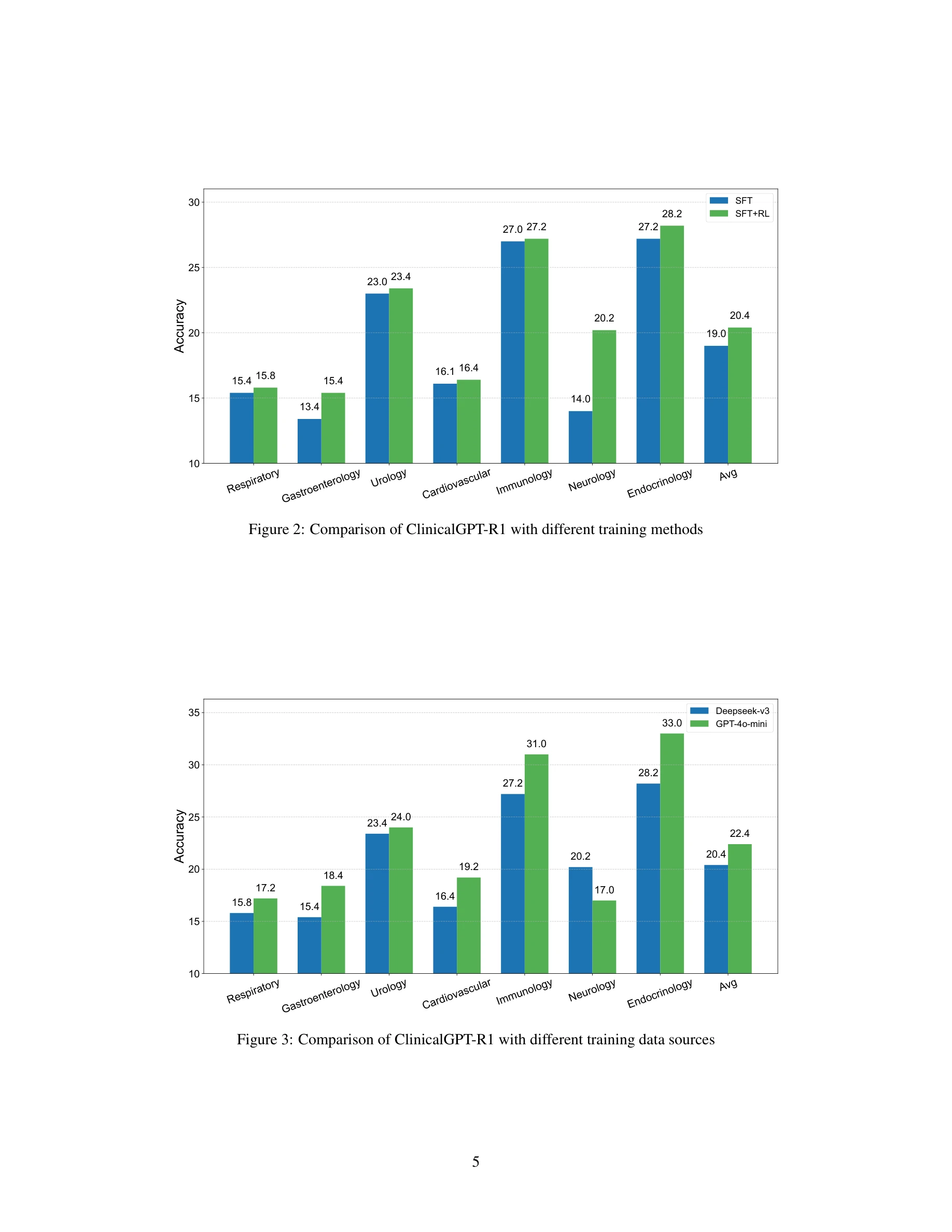
그림 2: 서로 다른 훈련 방법에 따른 ClinicalGPT-R1 성능 비교 (SFT vs SFT+RL)
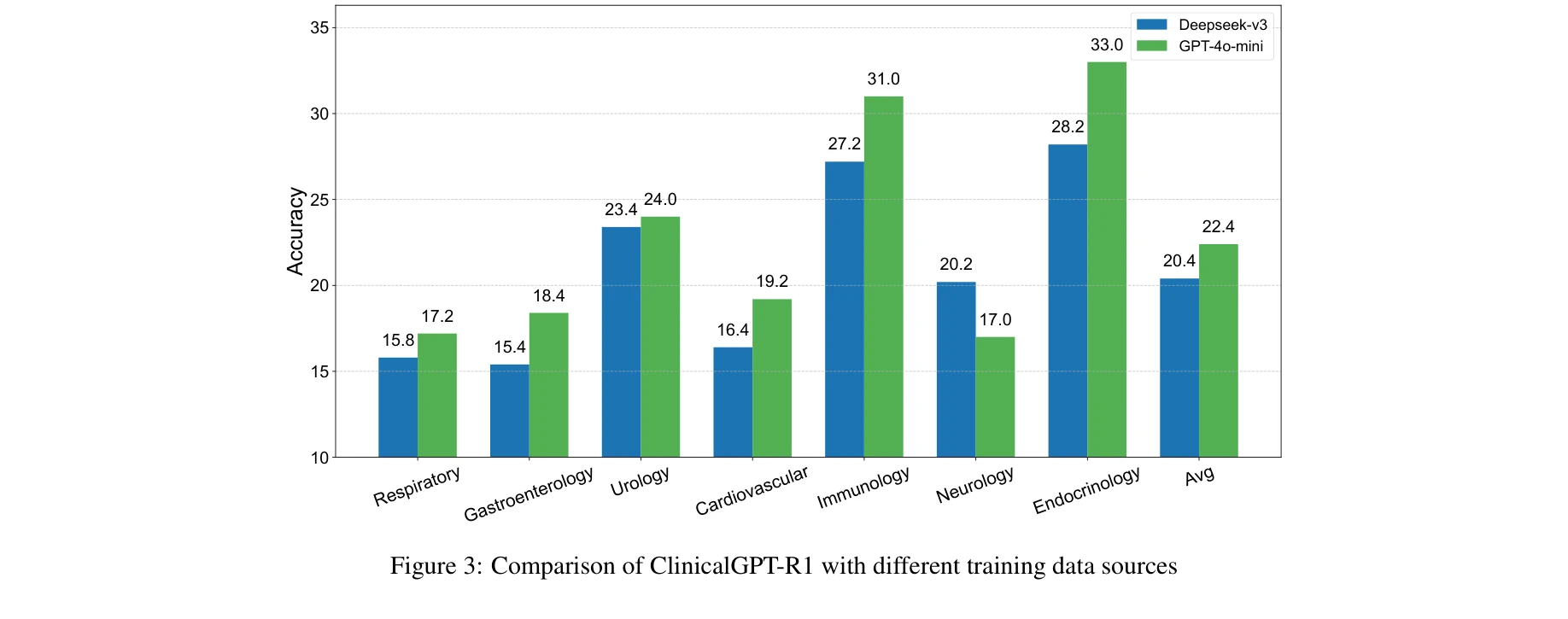
그림 3: 서로 다른 훈련 데이터 소스에 따른 ClinicalGPT-R1 성능 비교
그림 1: 임상 기록 기반 합성 데이터 생성 파이프라인 상세도
의료 데이터 구축:
장형 추론(Long CoT) 생성:
두 단계 학습:
보상 설계:
한계:
후속 연구 방향:
총평: ClinicalGPT-R1은 일반 도메인의 추론 기법을 의료에 체계적으로 적용하고 실제 임상 기록 기반의 데이터셋을 활용한 점에서 창의적이나, 절대 성능 수치의 낮음과 평가의 제한성, 그리고 중국어 중심의 성과로 인해 일반적 임상 응용성이 아직 미흡하다. 의료 AI 분야에서 추론 강화의 중요성을 보여주는 선도적 연구이나, 실용화를 위해서는 더욱 강력한 성능 개선과 임상 타당성 검증이 필요하다.