Essence
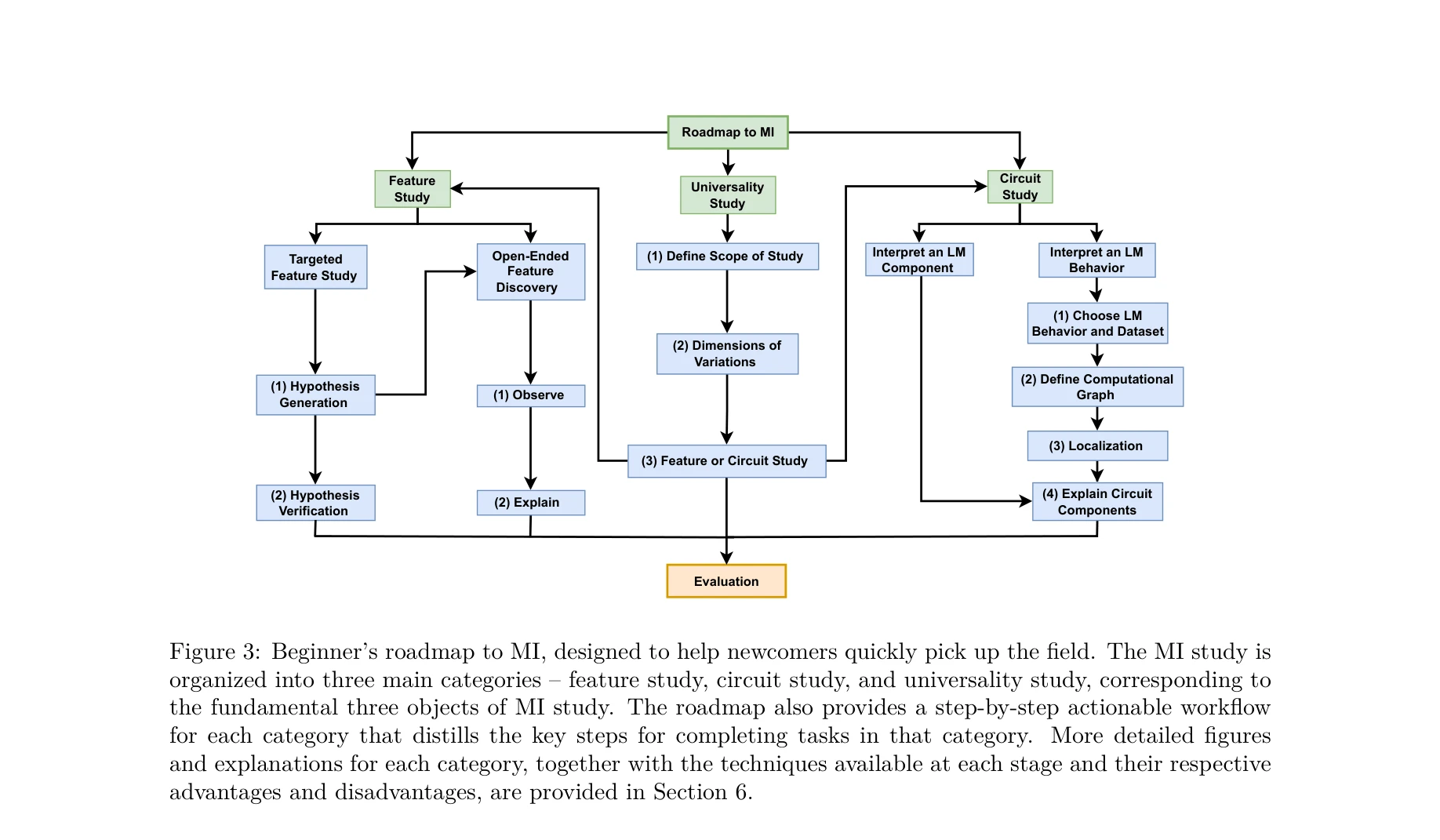
Figure 3: Beginner’s roadmap to MI, designed to help newcomers quickly pick up the field. The MI study is
트랜스포머 기반 언어모델의 내부 계산을 역공학하여 이해하는 기계적 해석가능성(Mechanistic Interpretability, MI)에 대한 종합 리뷰로, 초보자를 위한 실무 가이드를 제시한다.
저자: Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, Ziyu Yao | 날짜: 2024 | URL: https://arxiv.org/abs/2407.02646
Figure 3: Beginner’s roadmap to MI, designed to help newcomers quickly pick up the field. The MI study is
트랜스포머 기반 언어모델의 내부 계산을 역공학하여 이해하는 기계적 해석가능성(Mechanistic Interpretability, MI)에 대한 종합 리뷰로, 초보자를 위한 실무 가이드를 제시한다.
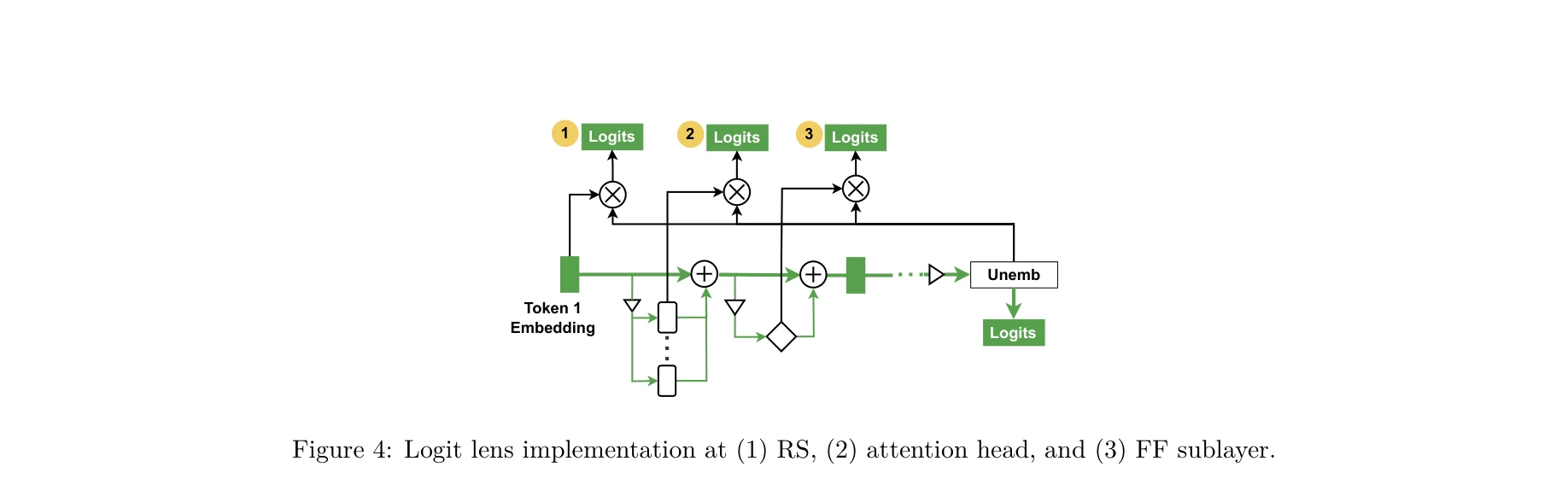
Figure 4: Logit lens implementation at (1) RS, (2) attention head, and (3) FF sublayer.
총평: 이 논문은 빠르게 성장하는 MI 분야에서 초보자부터 경험자까지 모두를 위한 실용적이고 포괄적인 가이드를 제공하며, 작업 중심의 분류체계와 구체적 워크플로우를 통해 해석가능성 연구의 새로운 표준을 제시한다. 현장 적용을 위한 실제 고려사항과 미래 방향을 함께 제시한 점에서 높은 가치를 지닌다.