Essence
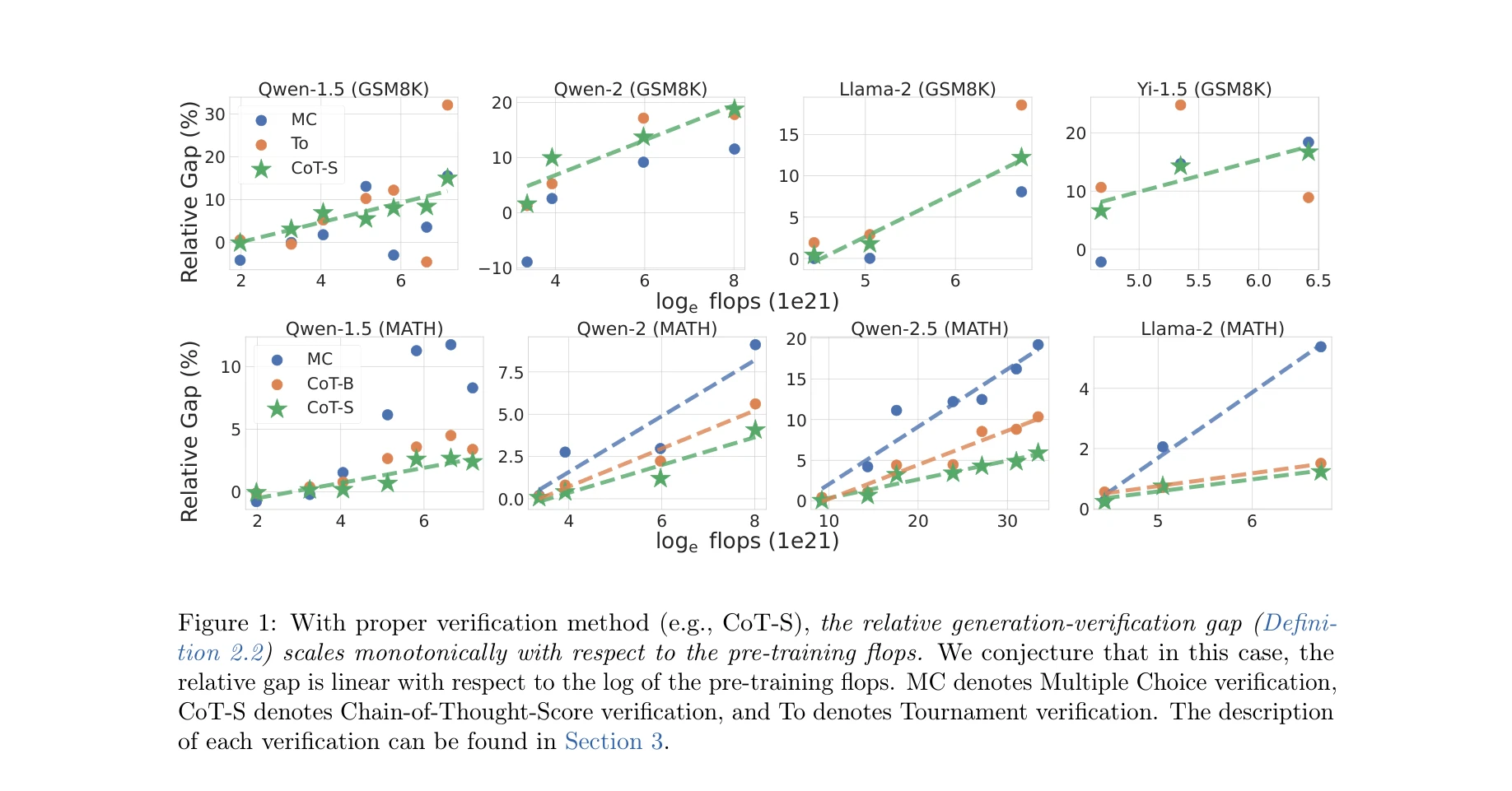
Figure 1: 적절한 검증 방법(예: CoT-S)을 사용할 때, 상대 생성-검증 갭이 사전학습 연산량(flops)에 대해 단조증가하는 현상
본 논문은 대규모 언어모델(LLM)의 자기개선(self-improvement) 메커니즘을 체계적으로 분석하며, 생성-검증 갭(Generation-Verification Gap, GV-Gap)이라는 핵심 지표를 통해 언어모델이 자신의 출력을 검증하여 성능을 개선할 수 있는 능력의 한계와 가능성을 규명한다.
How
Figure 3: 교차 개선에서의 GV-Gaps. 각 행(고정된 생성자)에 대해, 검증자 능력이 증가할수록 갭이 증가
자기개선 프레임워크의 형식화:
- 생성 단계: 프롬프트 분포 μ에서 생성자 f가 여러 응답 y를 생성. 중요한 조건은 생성 분포의 변동성(improvable generation)이 존재해야 함
- 검증 단계: 검증자 모델 g를 통한 대체 유틸리티(proxy utility) ûg를 정의. 핵심 지표인 생성-검증 갭(GV-Gap)을 다음과 같이 정의:
```
gap(f, g) := J(f[w(ûg)]) - J(f)
```
여기서 w는 검증 점수를 가중치로 변환하는 함수. 상대 갭(relative gap)은 최대 가능 개선에 대한 정규화
- 모델 업데이트: 두 가지 방식 고려:
- KL 정규화 강화학습(RLHF): w(s) = exp(s/β)
- 거부 샘플링(Rejection Sampling): w(s) = 1[s ≥ τ]
실험 설정:
- 모델 계열: Qwen-1.5/2/2.5, Llama-2, Yi-1.5 등 다양한 크기의 모델
- 검증 방법: Multiple Choice(MC), Chain-of-Thought-Score(CoT-S), Tournament(To) 등
- 작업: GSM8K(수학), MATH, 정보 검색, 추론 작업 등
핵심 발견:
- CoT-S 같은 강한 검증 방법에서만 스케일링 현상이 나타남
- 약한 검증 방법(MC)은 스케일링 현상을 보이지 않음
- 모델의 추론 능력을 초과하는 작업에서는 자기개선이 불가능
Evaluation
Novelty: 4.5/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4.5/5 Overall: 4.2/5
총평: 본 논문은 LLM 자기개선의 핵심 지표를 정의하고 광범위한 실증 분석을 통해 스케일링 현상을 최초로 규명한 의미 있는 연구이다. 생성-검증 갭이라는 개념이 향후 자기개선 알고리즘 설계의 중요한 기준이 될 것으로 예상되며, 다만 결과의 일반화 가능성 확대와 작동 메커니즘에 대한 더 깊은 분석이 필요하다.