Essence

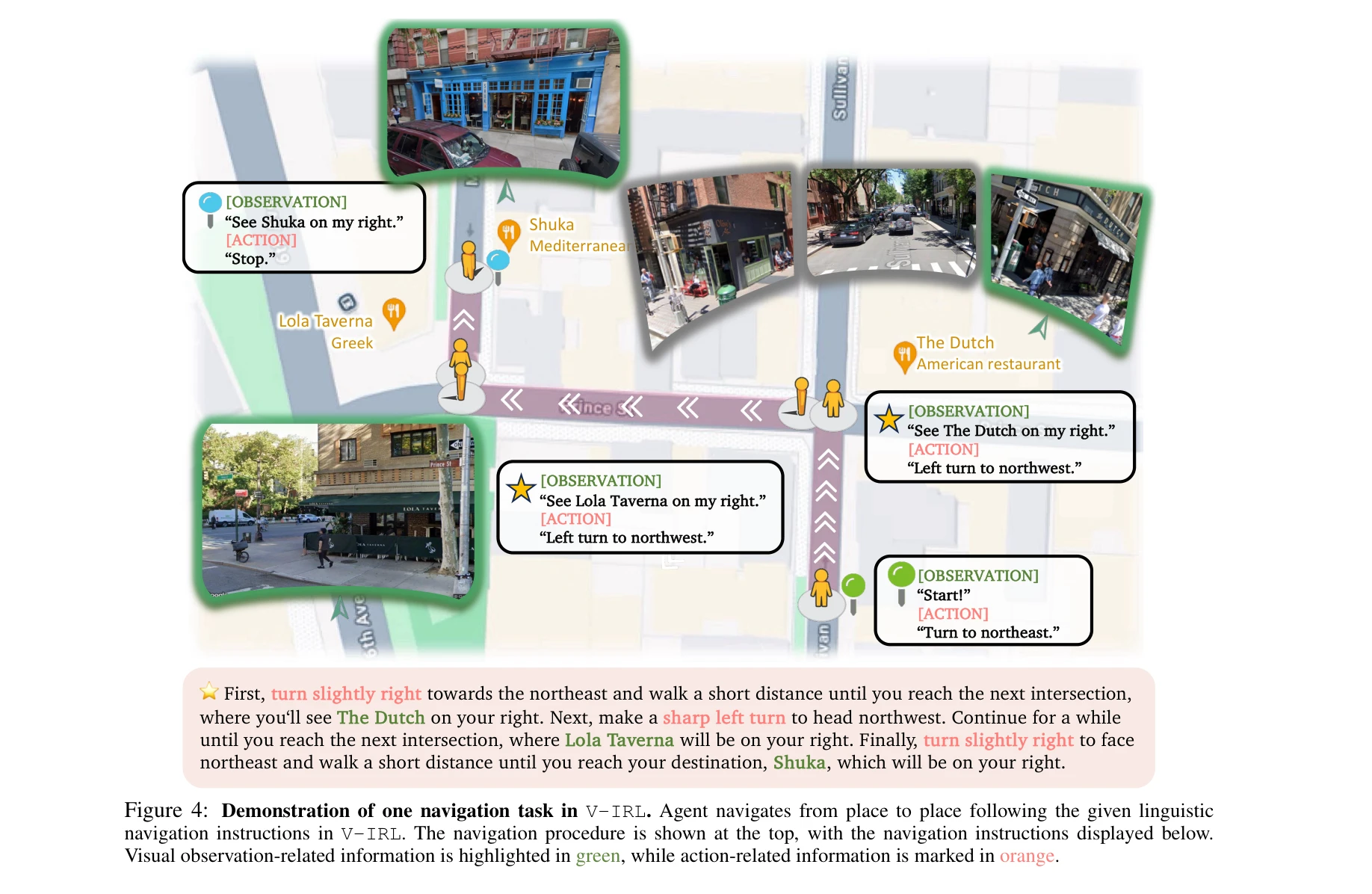
Figure 1: V-IRL 시각 네비게이션 환경에서 RL과 SFT의 비교 연구. OOD 곡선은 서로 다른 텍스트 액션 공간을 사용한 동일 작업의 성능을 나타냄
본 논문은 기초 모델의 사후훈련(post-training) 단계에서 지도학습 미세조정(SFT)과 강화학습(RL)의 일반화(generalization) 능력을 비교하는 체계적 연구로, RL은 규칙 기반 추론과 시각 작업에서 우수한 일반화 성능을 보이는 반면, SFT는 훈련 데이터의 암기(memorization)에 치중한다는 핵심 발견을 제시한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4.5/5 Significance: 4.5/5 Clarity: 4/5 Overall: 4.2/5
총평: 본 논문은 대규모 기초 모델 훈련에서 광범위하게 사용되는 두 주요 기법의 일반화 능력을 체계적으로 비교한 중요한 실증 연구로, "RL은 일반화, SFT는 암기"라는 명확한 구분을 통해 향후 모델 개발 전략에 실질적 지침을 제공한다. 다만 작업 범위와 모델 다양성 측면에서의 확장이 필요하며, SFT-RL 상호작용의 최적화 메커니즘에 대한 더 깊은 분석이 요구된다.