저자: Jiaxin Huang, Shixiang Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, Jiawei Han | 날짜: 2022 | DOI: N/A
Essence
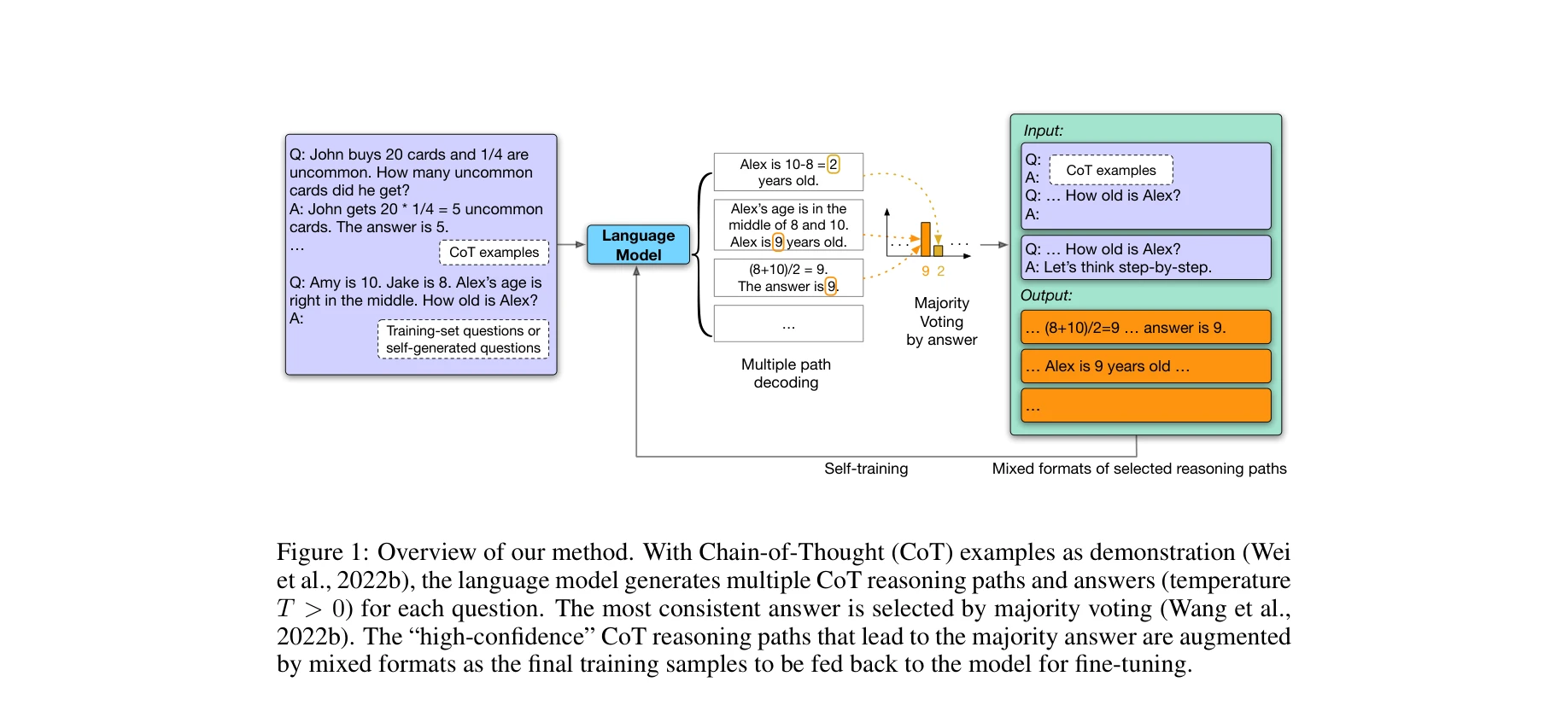
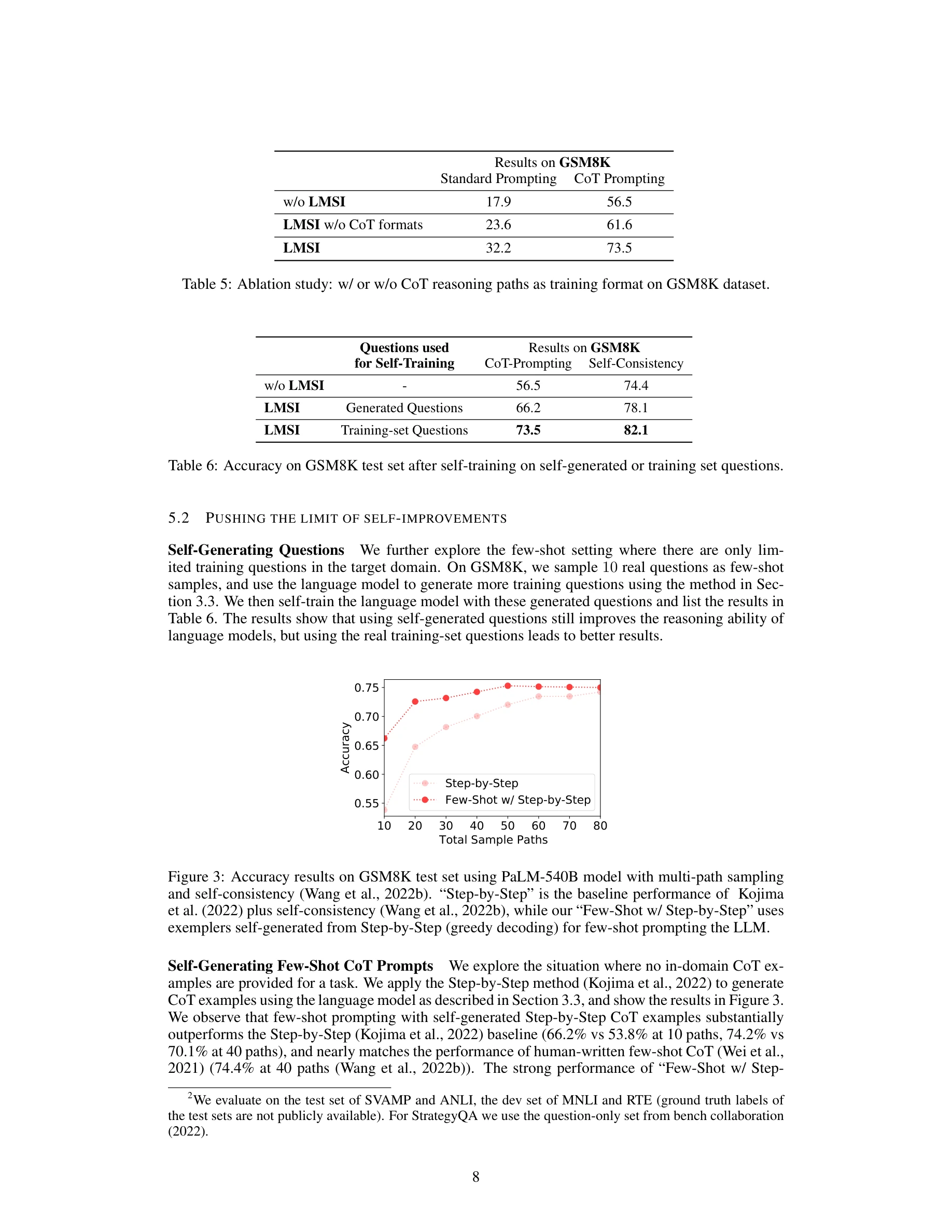
그림 1: 방법의 개요. Chain-of-Thought 예시를 활용하여 언어모델이 여러 개의 CoT 추론 경로를 생성하고, 다수결 투표(Majority Voting)로 고신뢰도 답변을 선택한 후, 이를 파인튜닝 데이터로 활용
대규모 언어모델(LLM)이 레이블 없는 데이터만으로 자기 생성 고신뢰도 추론(reasoning) 경로를 통해 자가 개선(self-improve)할 수 있음을 입증한 논문이다. Chain-of-Thought 프롬팅과 자기 일관성(self-consistency)을 활용하여 감독 신호 없이 모델의 추론 능력을 향상시킨다.
Evaluation
총평: 이 논문은 레이블 없는 데이터로 대규모 언어모델이 자가 개선할 수 있음을 명확히 입증한 중요한 연구다. Chain-of-Thought와 자기 일관성을 창의적으로 조합하여 강력한 자동 감독 신호를 얻었으며, 도메인 내외 다수 데이터셋에서 상태 추적 수준의 성능을 달성했다. 다만 신뢰도 평가의 정교성, 오류 증폭 위험, 계산 비용 등의 한계가 있으나, 감독 신호 의존성을 크게 줄일 수 있다는 점에서 실무적 가치가 매우 높다.