Essence
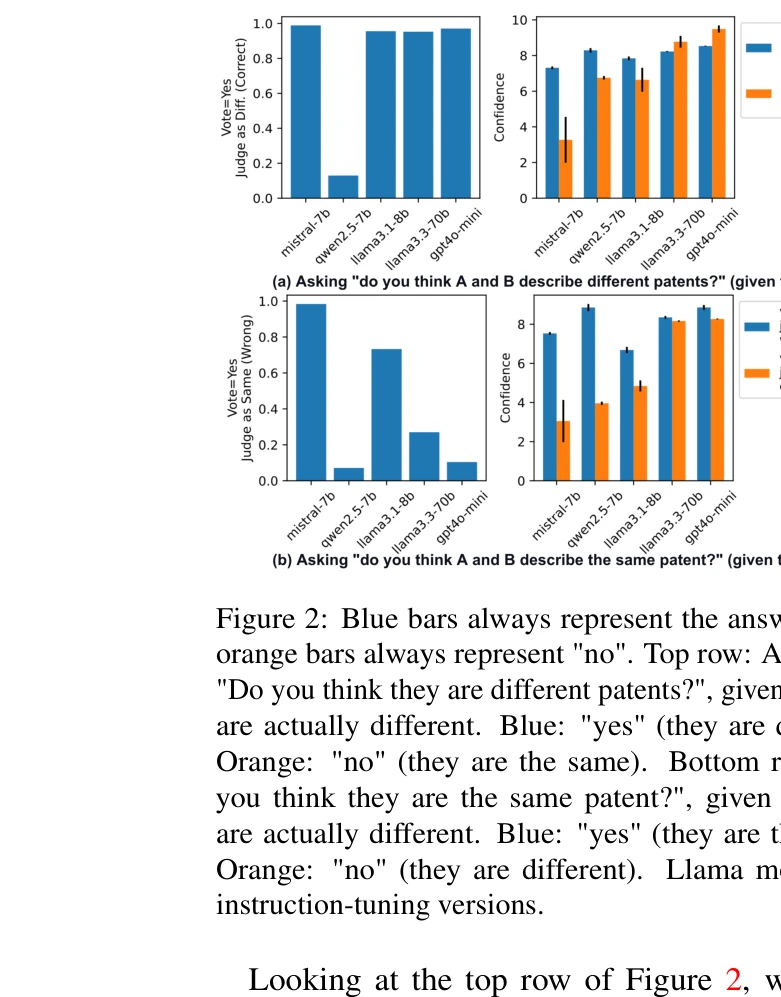
특허 쌍 구분 작업에서 LLM의 정확도 비교: "다른 특허인가?"와 "같은 특허인가?" 질문에 대한 응답 분포
본 논문은 대규모 언어모델(LLM)의 기술 판단 능력을 평가하기 위해 USPTO 특허 분류 작업을 활용하여, 모델이 보유한 지식(lay-in knowledge)과 실제 활용하는 지식(working knowledge) 간의 격차를 진단하는 프레임워크를 제안한다.
저자: Yongtao Liu, Marti Checa, Rama Vasudevan | 날짜: 2025 | DOI: 제공되지 않음
특허 쌍 구분 작업에서 LLM의 정확도 비교: "다른 특허인가?"와 "같은 특허인가?" 질문에 대한 응답 분포
본 논문은 대규모 언어모델(LLM)의 기술 판단 능력을 평가하기 위해 USPTO 특허 분류 작업을 활용하여, 모델이 보유한 지식(lay-in knowledge)과 실제 활용하는 지식(working knowledge) 간의 격차를 진단하는 프레임워크를 제안한다.
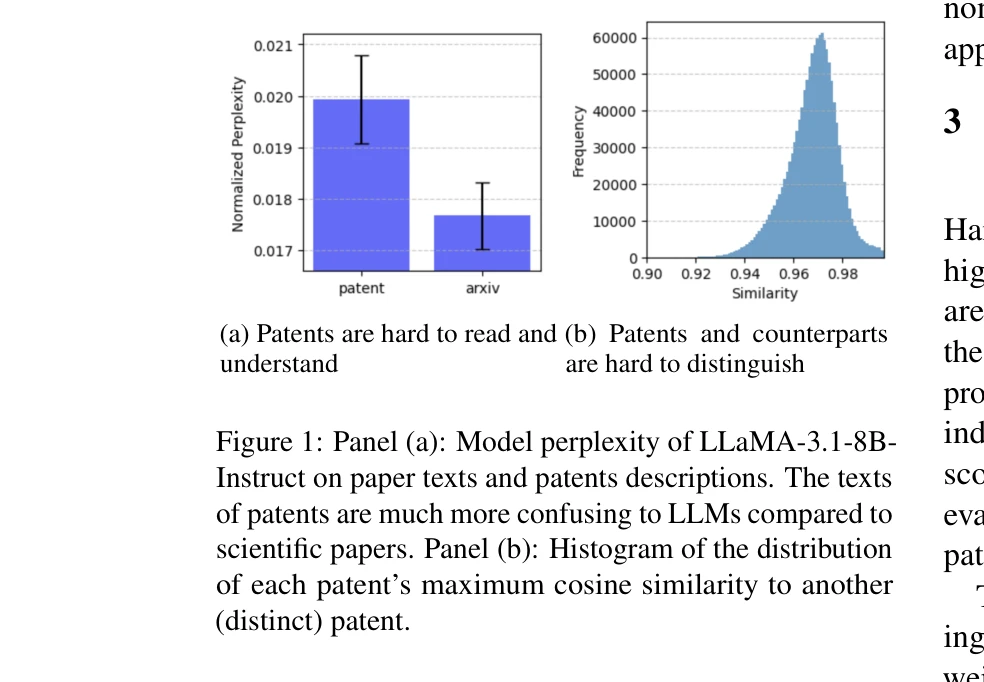
Panel (a): ArXiv 논문과 특허 설명서의 모델 혼란도(perplexity) 비교 / Panel (b): 각 특허와 가장 유사한 다른 특허 간 코사인 유사도 분포
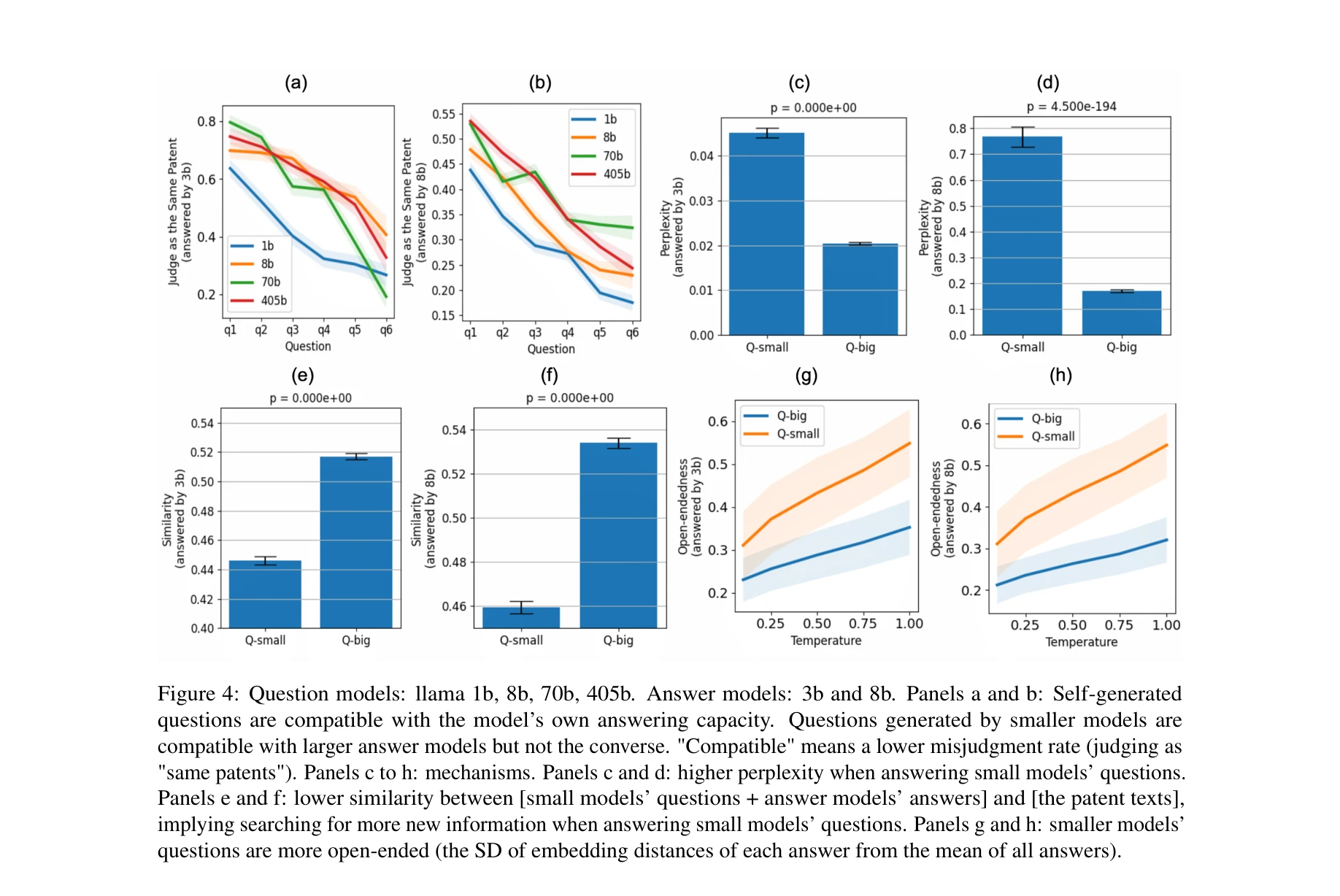
질문 생성 모델과 답변 모델의 조합에 따른 성능: 자가생성 질답 vs. 외부 정보 기반 질답 비교
총평: 본 논문은 LLM의 실제 능력 평가에 중요한 "미사용 지식" 문제를 체계적으로 규명하고, 특허라는 도메인을 통해 개념 이해의 핵심 요소인 차별화 능력을 창의적으로 테스트한다. 다만, 도메인 특이성과 외부 정보의 완전성 가정으로 인해 일반화에 제약이 있으며, 진단 이후 개선 방안 제시까지는 미흡한 상태이다.