Achievement
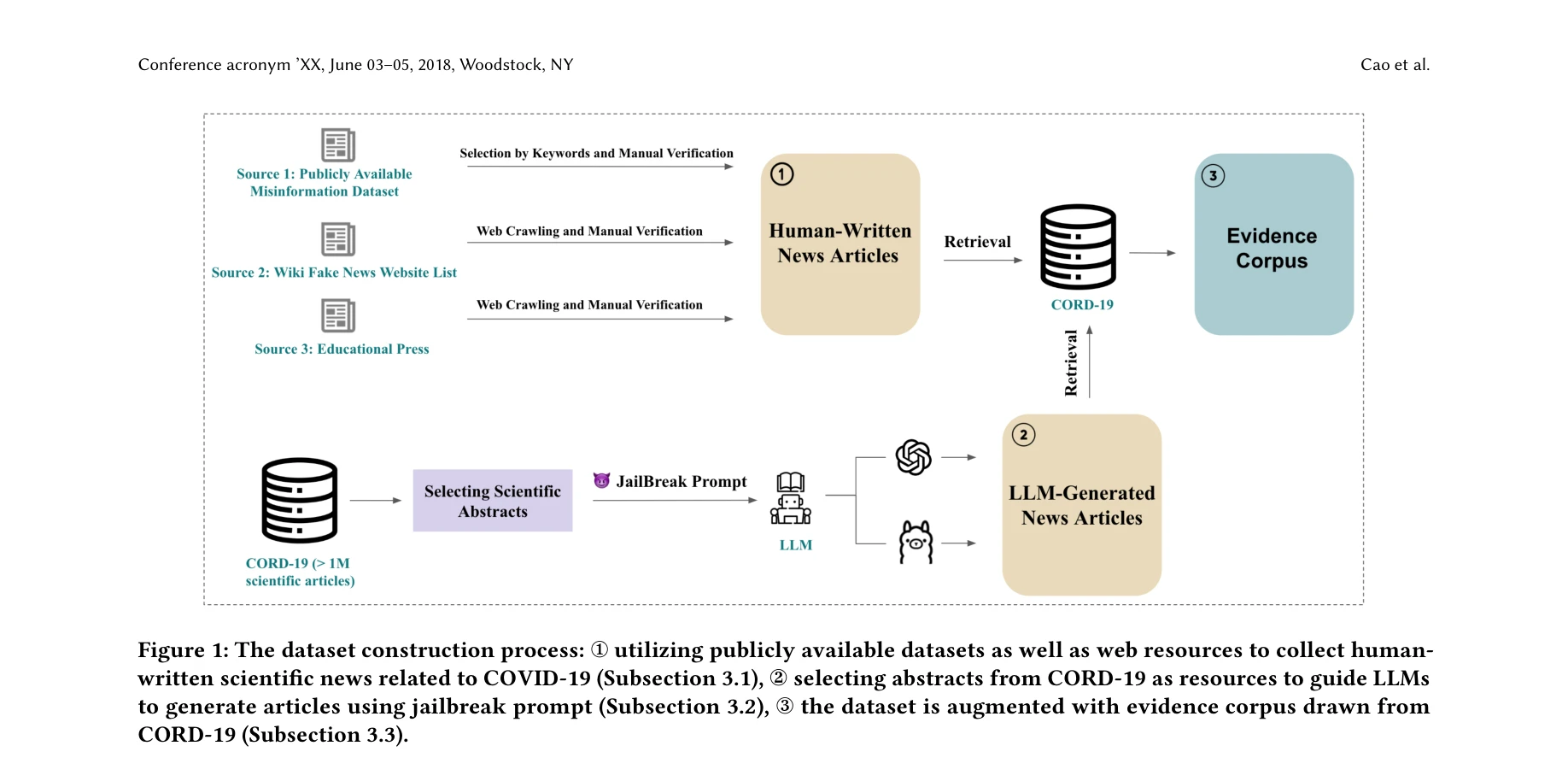
데이터셋 구축 프로세스: 공개 데이터셋, 웹 리소스, LLM 기반 생성을 통한 균형잡힌 코퍼스 수집
- CoSMis(SciNews) 데이터셋 개발: 2,400개의 COVID-19 관련 뉴스(신뢰 1,200개, 부신뢰 1,200개)와 CORD-19 과학 초록 페어링. 인간 작성(1,200개)과 LLM 생성(1,200개) 균형 포함으로 실제 시나리오 반영
- 과학적 타당성 차원(DoV) 정의: 과학 뉴스의 오보를 다차원으로 평가하는 프레임워크 제시
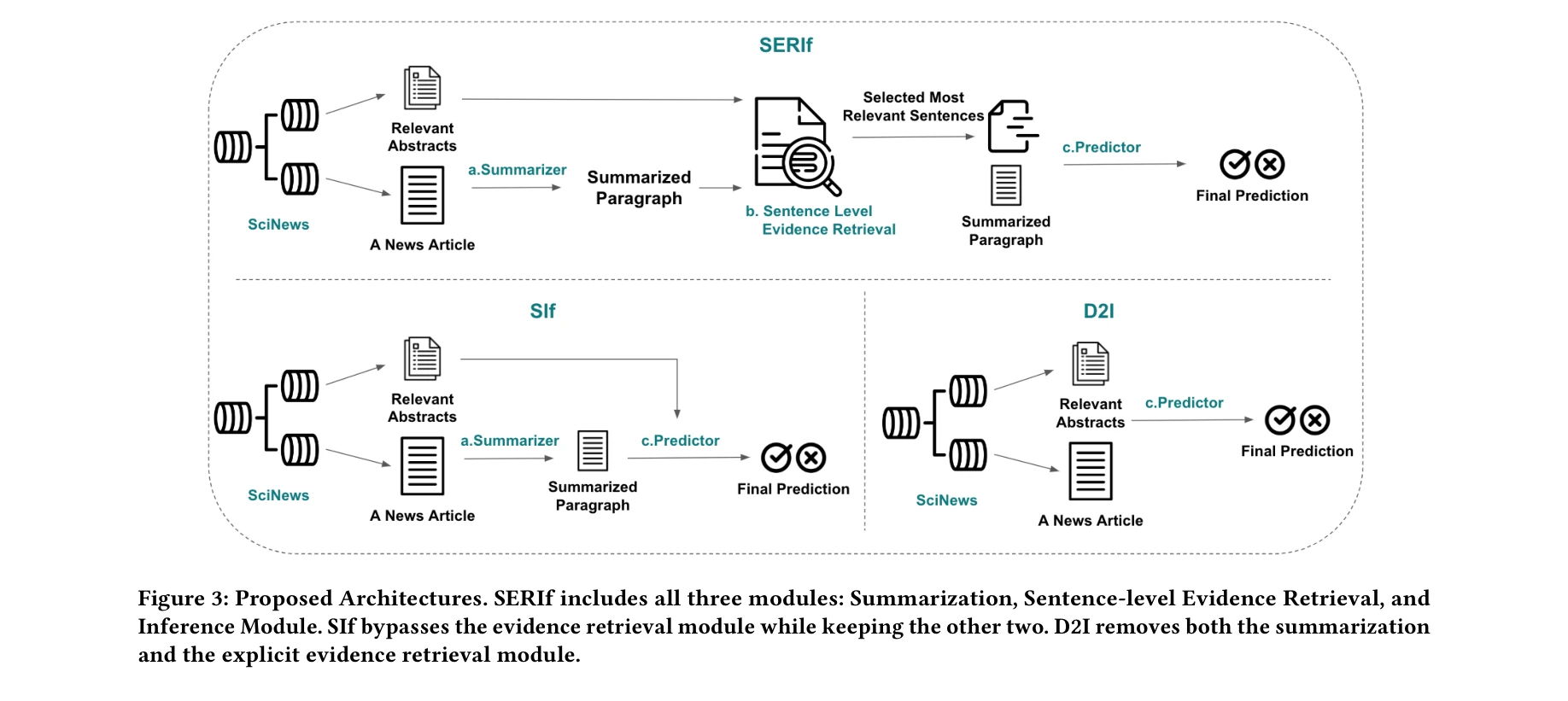
- 3가지 LLM 파이프라인: SERIf(Summarization-Evidence Retrieval-Inference), SIf(Evidence Retrieval 제외), D2I(Direct-to-Inference) 아키텍처로 점진적 처리 단계 감소 설계
- 설명가능성 제공: DoV 기반 Chain-of-Thought prompting으로 모델 의사결정 과정의 해석 가능성 확보