Essence
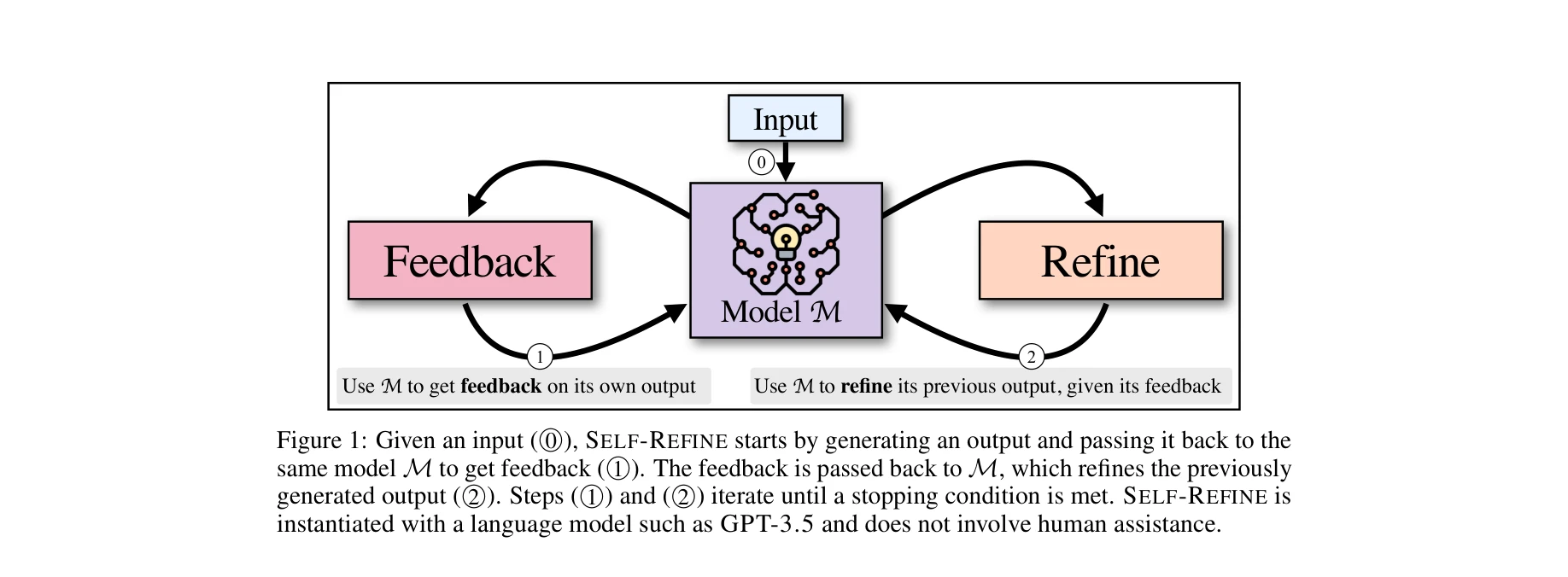
Figure 1: SELF-REFINE의 기본 작동 원리. 동일한 모델 M이 초기 생성, 피드백 제공, 개선을 반복적으로 수행
대규모 언어 모델(LLM)이 자신의 출력에 대해 피드백을 제공하고 이를 바탕으로 자동으로 개선하는 반복적 자기 정제 방식을 제시한다. 추가 훈련이나 외부 보상 모델 없이 단일 LLM만으로 약 20% 절대 성능 향상을 달성한다.
저자: Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao 외 | 날짜: 2023 | DOI: 10.48550/arXiv.2303.17651
Figure 1: SELF-REFINE의 기본 작동 원리. 동일한 모델 M이 초기 생성, 피드백 제공, 개선을 반복적으로 수행
대규모 언어 모델(LLM)이 자신의 출력에 대해 피드백을 제공하고 이를 바탕으로 자동으로 개선하는 반복적 자기 정제 방식을 제시한다. 추가 훈련이나 외부 보상 모델 없이 단일 LLM만으로 약 20% 절대 성능 향상을 달성한다.

Figure 2: SELF-REFINE의 실제 예시. 대화 생성(상단)과 코드 최적화(하단) 작업에서의 초기 출력과 피드백, 개선된 출력

Figure 3: SELF-REFINE 알고리즘 구조. 피드백과 정제 단계를 반복하는 의사코드
총평: 이 논문은 거대 언어 모델이 자신의 피드백을 통해 반복적으로 스스로를 개선할 수 있다는 간단하면서도 효과적인 아이디어를 제시한다. 추가 훈련 없이 기존 LLM에 즉시 적용 가능하면서도 평균 20% 성능 향상을 달성하여 실무적 가치가 높으나, 계산 비용 증가, 피드백 품질 의존성, 일부 작업에서의 제한된 효과 등이 개선과제로 남아있다.