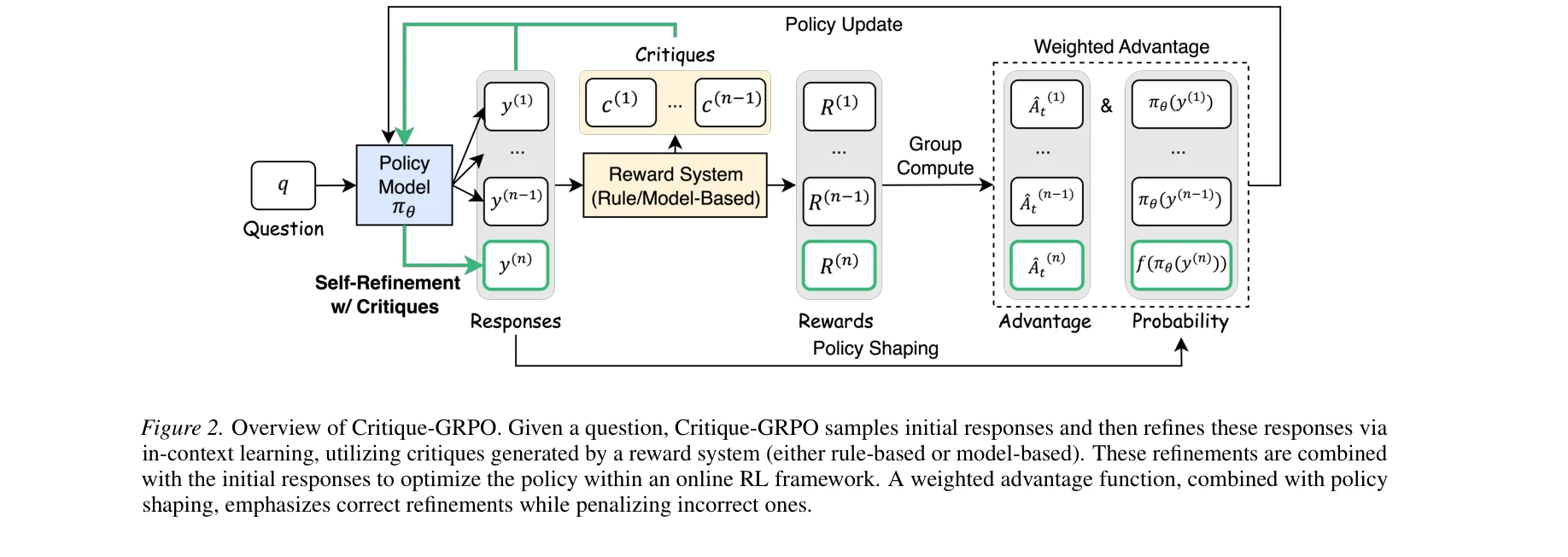
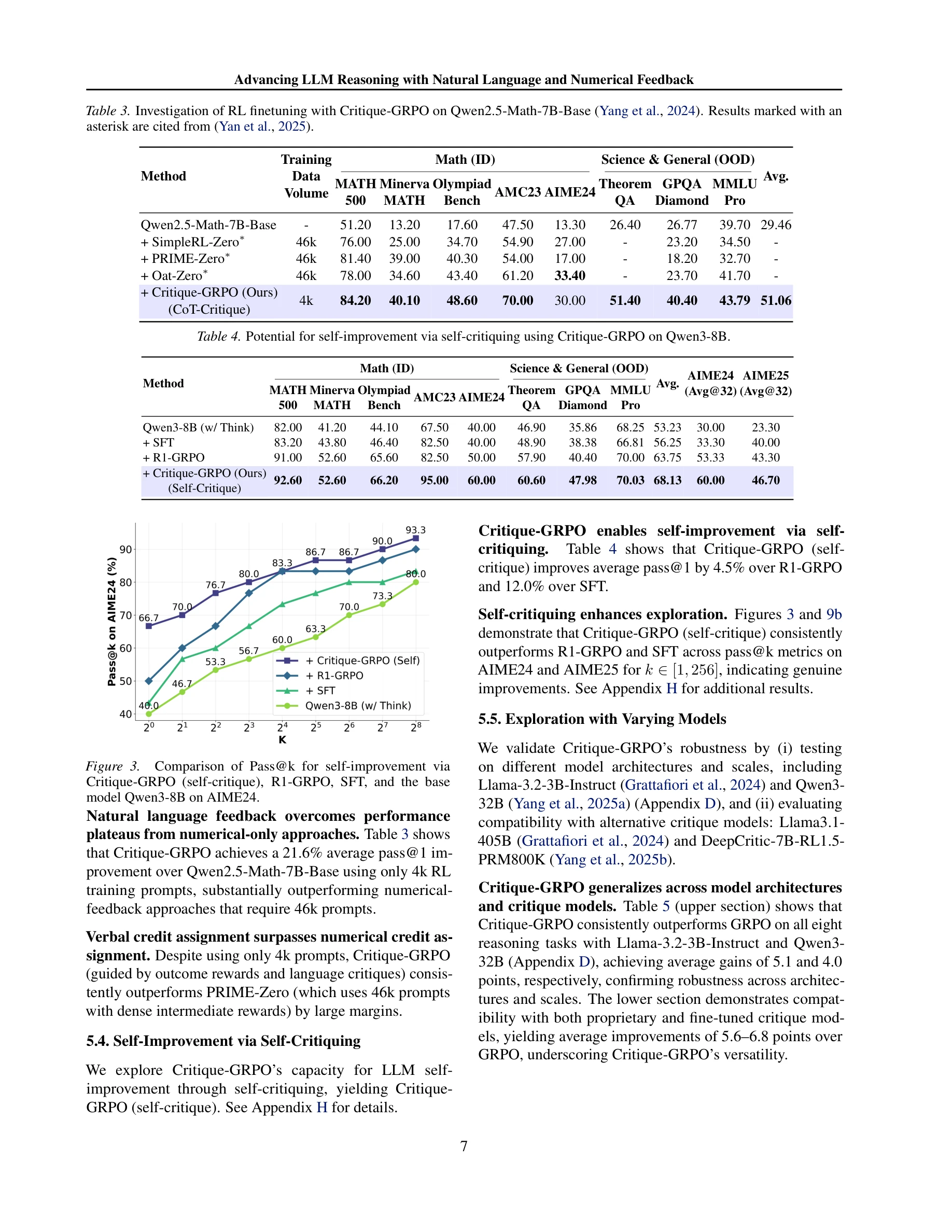
Essence
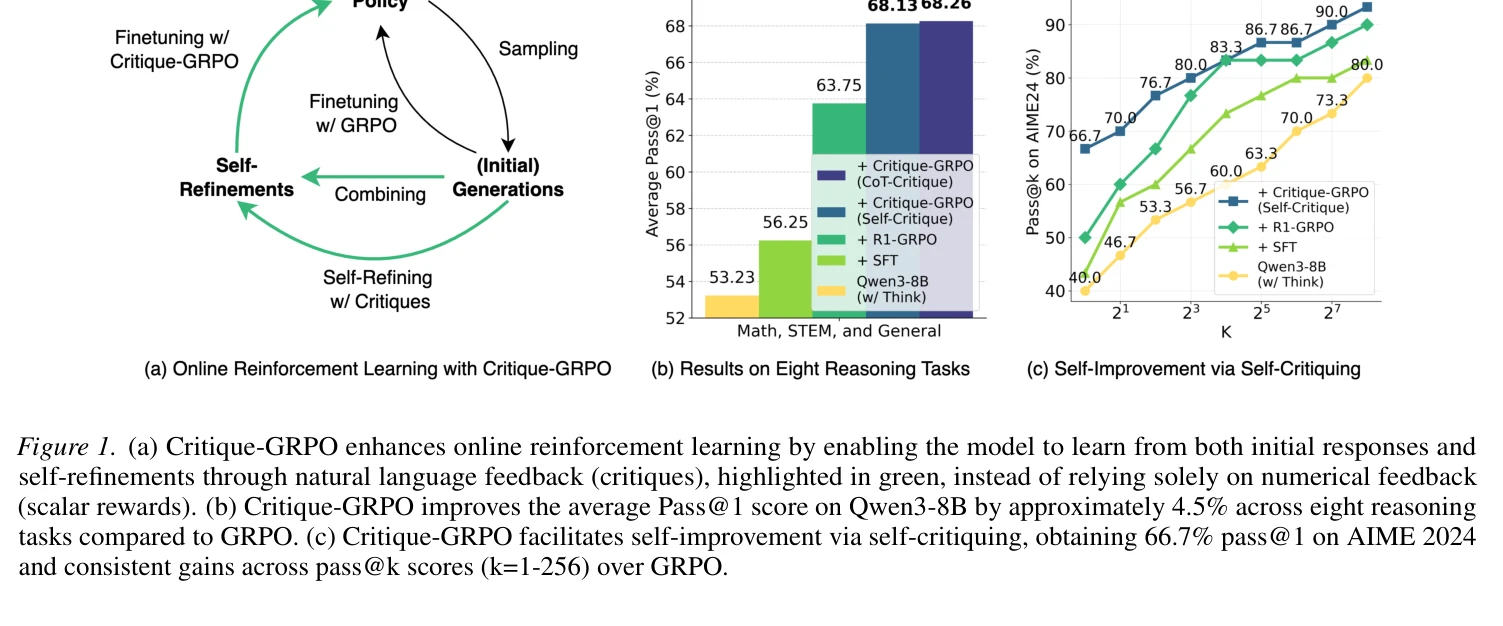
그림 1: (a) Critique-GRPO는 수치 피드백만이 아닌 자연어 피드백(비판)을 통해 초기 응답과 자기 개선 모두에서 학습 가능. (b) Qwen3-8B에서 8가지 추론 과제 평균 Pass@1 4.5% 개선. (c) 자기 비판을 통한 자기 개선으로 AIME 2024에서 66.7% Pass@1 달성.
본 논문은 순수 수치 보상(numerical rewards)의 한계를 극복하기 위해 자연언어 비판(natural language critiques)을 온라인 강화학습(online RL) 프레임워크에 통합한 Critique-GRPO를 제안한다. 이는 LLM의 추론 능력을 향상시키는 새로운 접근 방식이다.