저자: Yongheng Zhang, Qiguang Chen, Jingxuan Zhou, Peng Wang, Jiasheng Si, Jin Wang, Wenpeng Lu, Libo Qin | 날짜: 2024 | DOI: arXiv:2410.04463
Essence

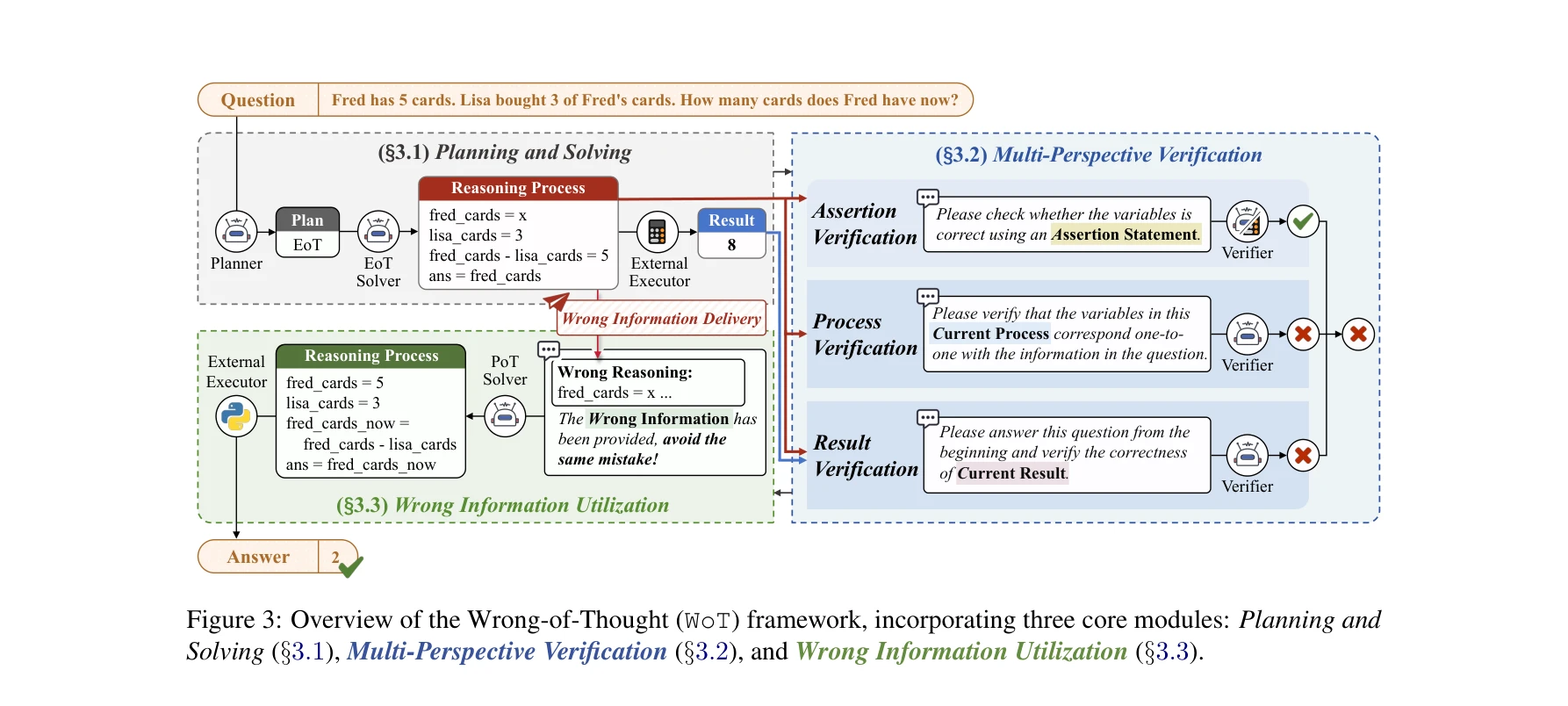
그림 1: 기존 다중 사고 통합 방법(a)은 단일 검증만 사용하고 오류 정보를 활용하지 않는 반면, WoT(b)는 다중 관점 검증과 오류 정보 활용을 제공한다.
대규모 언어 모델(LLM)의 추론 성능을 향상시키기 위해 다중 관점에서 검증하고 이전 오류 정보를 활용하는 WoT(Wrong-of-Thought) 프레임워크를 제안한다. 기존 XoT의 단일 검증 방식과 오류 정보 무시 문제를 해결하여 8개 데이터셋과 5개 LLM에서 우수한 성능을 달성했다.
How
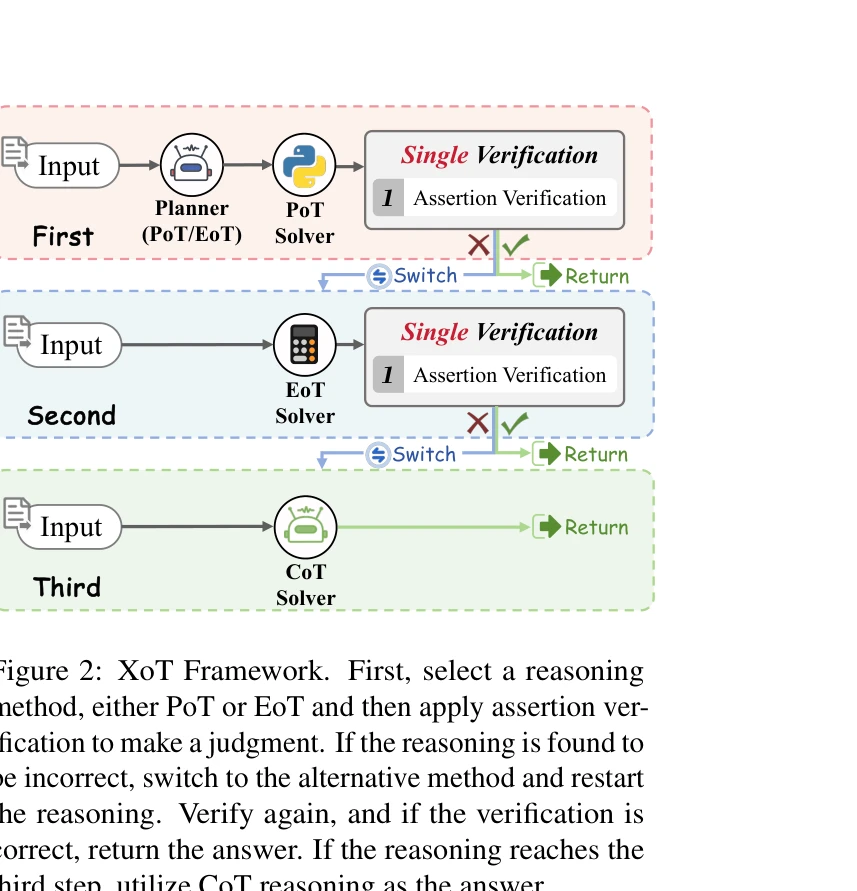
그림 2: XoT 프레임워크. 추론 방법 선택 후 어설션 검증을 통해 판단하고, 오류 시 다른 방법으로 전환하여 재시작한다.
다중 관점 검증(Multi-Perspective Verification)
- 어설션 검증: XoT의 기존 방식을 채용하여 중간 변수를 어설션 문장으로 형식화하고 외부 도구로 실행 검증
- 프로세스 검증: 계산 결과를 제외한 추론 과정만 제시하여 LLM이 각 단계의 변수가 문제의 정보와 일대일로 대응되는지 확인하도록 유도
- 결과 검증: 추론 과정과 계산 결과를 모두 제시한 후, 문제를 처음부터 다시 풀어서 결과의 일관성 검증
- 투표 메커니즘: 식(1)을 통해 세 검증 방법의 결과 중 가장 일치도가 높은 판단을 최종 결과로 선택
$$\hat{V} = \arg\max_{V_t \in V} \sum_{t=1}^{N} \sum_{R \in M_i} \mathbb{1}(V_t = R)$$
오류 정보 활용(Wrong Information Utilization)
- 이전 추론에서 발생한 오류 정보를 현재 풀이 문맥에 포함시킴
- 식(2)로 표현되는 조건부 확률을 최대화하여 오류 정보 WI가 추가된 상태에서 최적의 추론 경로 R을 생성
$$\hat{R} = \arg\max_{R \in M_i} P(R|Q, I, WI)$$
- 재검증 후에도 오류 발생 시, 현재와 이전의 오류 정보를 모두 CoT 추론의 부정적 예시로 활용
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: WoT는 단순하지만 효과적인 개선책을 통해 LLM의 추론 성능을 일관되게 향상시키며, 광범위한 실험으로 그 유효성을 입증했다. 다만 검증 오버헤드와 오류 정보 활용의 심화 방안에 대한 추가 연구가 필요하다.