Essence
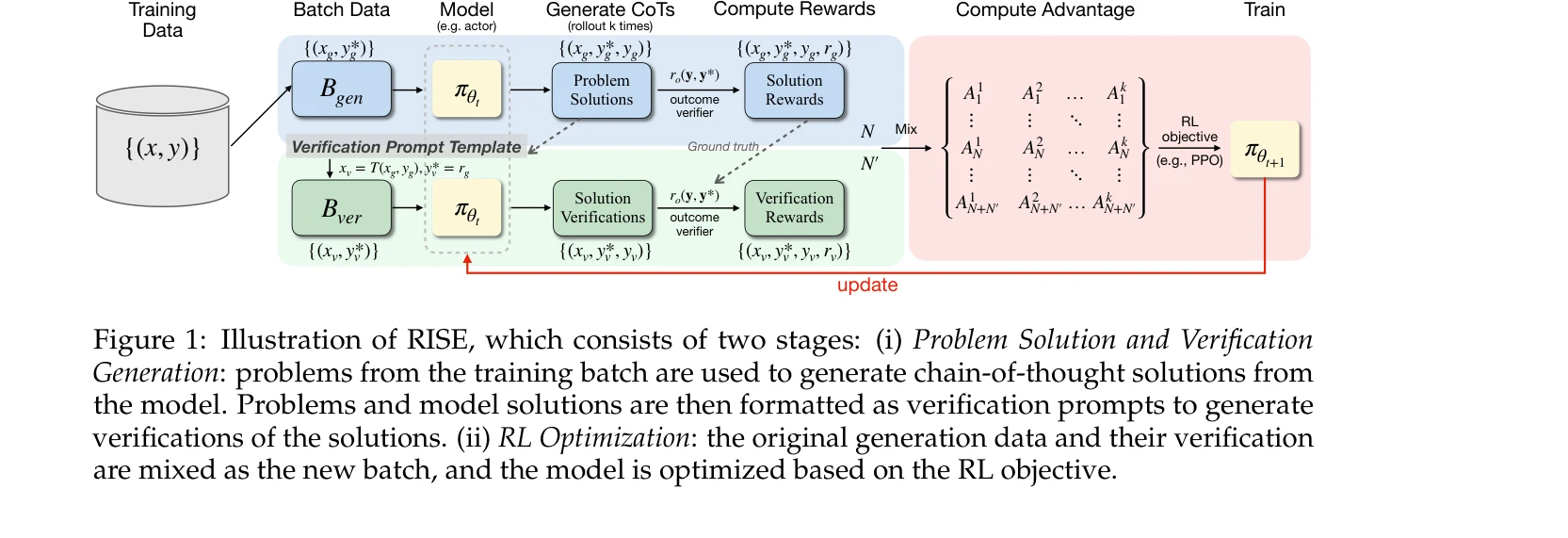
RISE 프레임워크: (i) 문제 풀이 및 검증 생성 단계와 (ii) RL 최적화 단계로 구성
대규모 언어모델(LLM)의 "표면적 자기반성(superficial self-reflection)" 문제를 해결하기 위해, 검증 가능한 보상(verifiable rewards)을 활용하여 문제 풀이 능력과 자기검증 능력을 동시에 온라인으로 학습하는 RISE 프레임워크를 제안한다.
저자: Xiaoyuan Liu, Tian Liang, Zhiwei He, Jiahao Xu, Wenxuan Wang | 날짜: 2025 | DOI: 10.48550/arXiv.2505.13445
RISE 프레임워크: (i) 문제 풀이 및 검증 생성 단계와 (ii) RL 최적화 단계로 구성
대규모 언어모델(LLM)의 "표면적 자기반성(superficial self-reflection)" 문제를 해결하기 위해, 검증 가능한 보상(verifiable rewards)을 활용하여 문제 풀이 능력과 자기검증 능력을 동시에 온라인으로 학습하는 RISE 프레임워크를 제안한다.
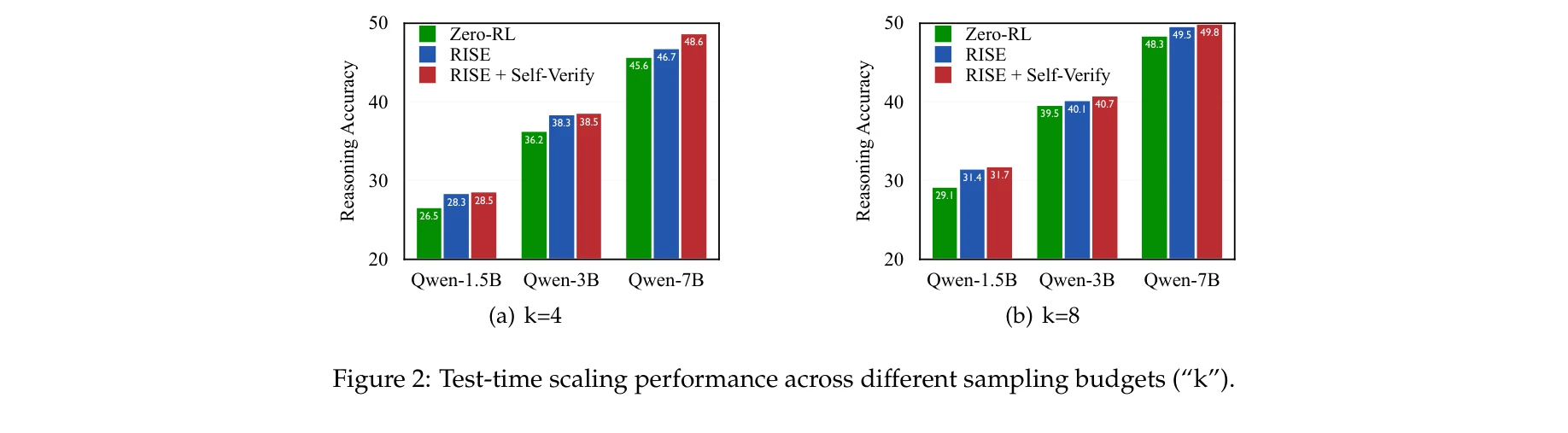
다양한 샘플링 예산에서의 테스트 타임 성능 비교 (k값)

RISE와 다른 접근법 간의 비교 분석
총평: 본 논문은 검증 가능한 보상을 활용하여 LLM의 문제 풀이와 자기검증 능력을 동시에 강화하는 실용적이고 효과적인 온라인 RL 프레임워크를 제안하며, 수학적 추론 벤치마크에서의 일관된 성능 개선과 상세한 분석으로 학계의 주목할 만한 기여이다.