Essence
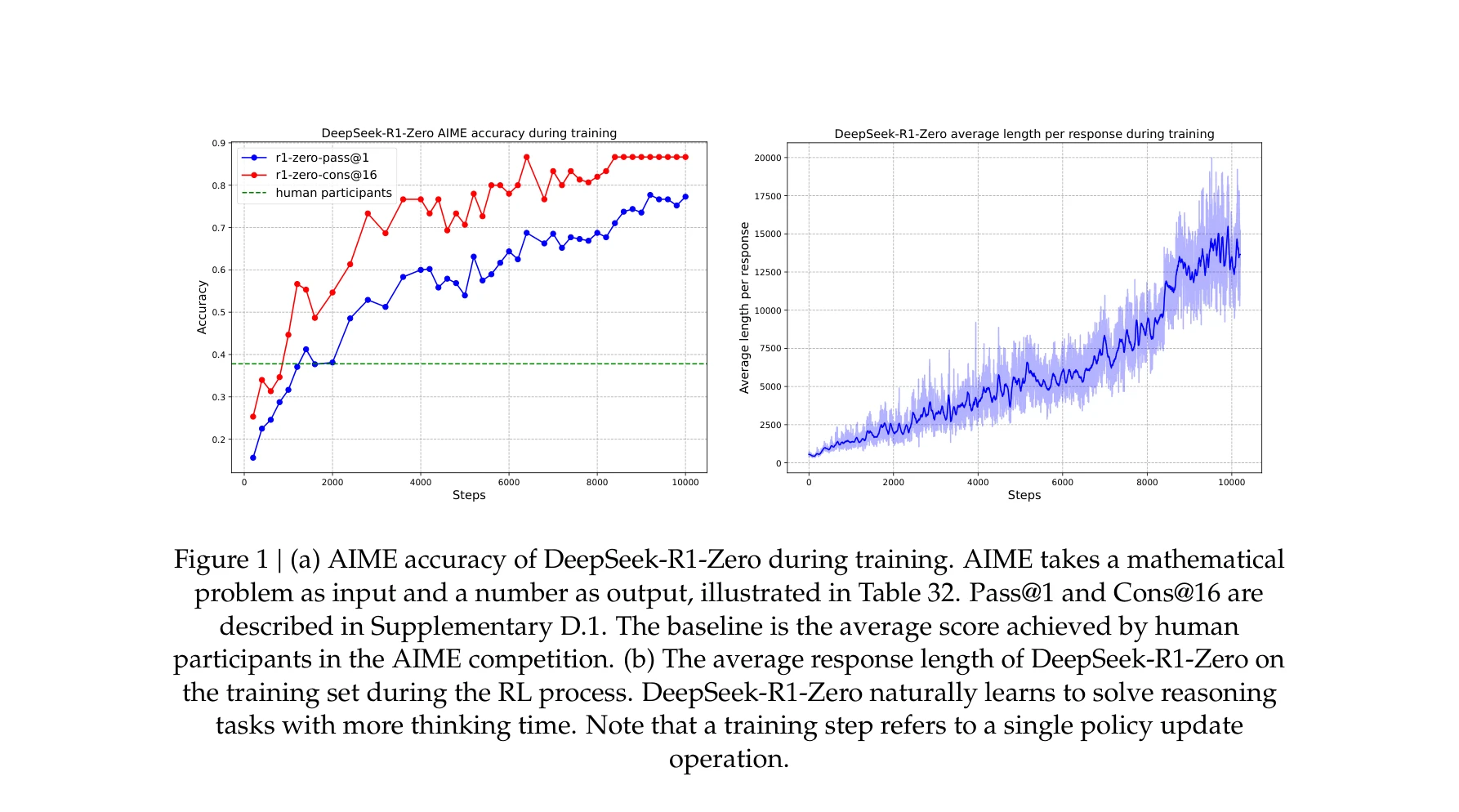
Figure 1: (a) RL 훈련 과정에서 DeepSeek-R1-Zero의 AIME 정확도. (b) RL 프로세스 중 응답의 평균 길이 증가.
본 논문은 인간이 주석을 단 추론 궤적(reasoning trajectory) 없이 순수 강화학습(RL)을 통해 대형언어모델(LLM)의 추론 능력을 유도할 수 있음을 보여준다. RL 훈련 과정에서 모델은 자발적으로 자기 검증, 재검토, 동적 전략 적응 등의 고급 추론 패턴을 개발한다.
Evaluation
Novelty: 5/5 Technical Soundness: 5/5 Significance: 5/5 Clarity: 4/5 Overall: 4.75/5
총평: 본 논문은 LLM의 추론 능력 발전에 있어 인간 주석의 필요성을 근본적으로 재검토하며, 순수 RL만으로 고급 추론 패턴의 자발적 발현을 입증한 혁신적 연구이다. AIME에서 인간 수준을 초과하는 성능 달성과 함께 모델의 자기 진화 과정을 명확히 보여주는 점이 높이 평가되나, 개방형 작업으로의 확장과 신경망 보상 모형의 안정화가 향후 과제로 남아있다.