Essence
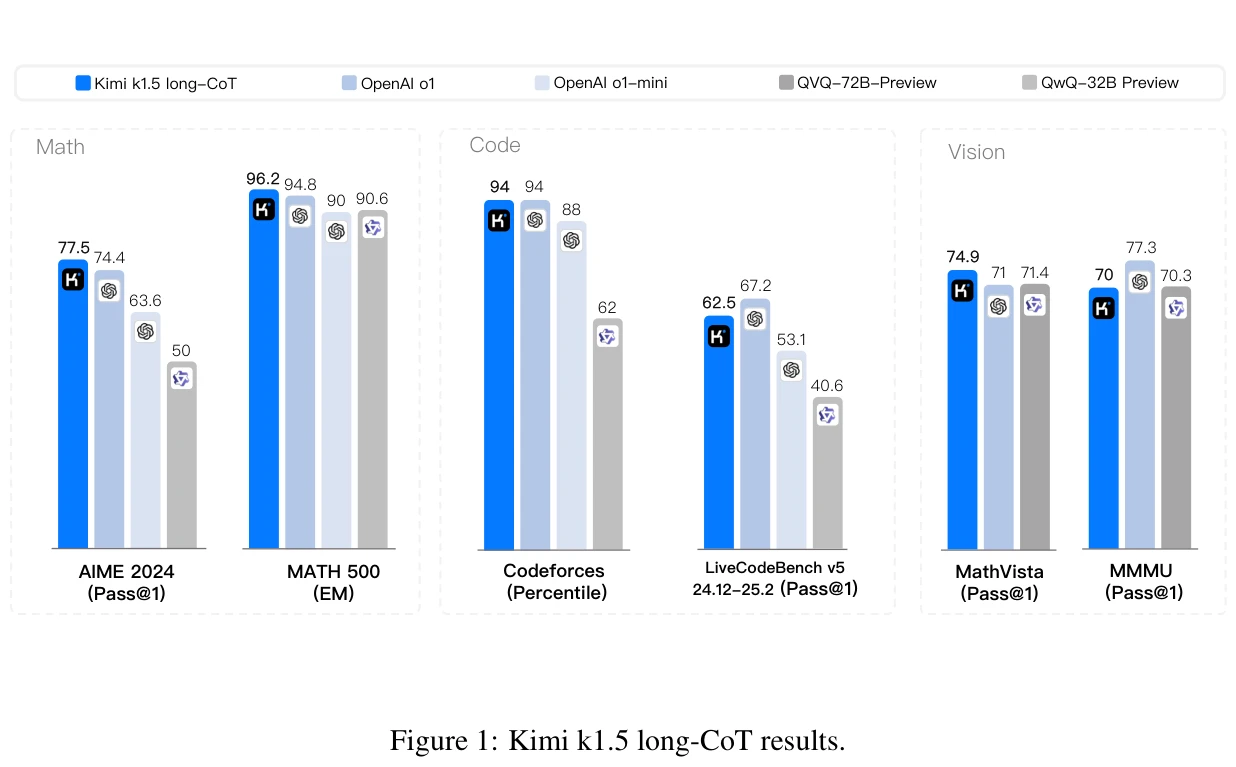
본 논문은 대규모 언어모델(LLM)의 강화학습(RL) 기반 훈련을 통해 추론 성능을 대폭 향상시킨 Kimi k1.5 모델을 제시한다. 긴 맥락(long context) 확장과 개선된 정책 최적화를 기반으로 복잡한 기법(MCTS, 가치함수 등) 없이도 o1 수준의 성능을 달성했다.
저자: Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Feng Tang, Flood Sung, Guangda Wei, Guokun Lai, Haiqing Guo | 날짜: 2025 | DOI: arXiv:2501.12599v4
본 논문은 대규모 언어모델(LLM)의 강화학습(RL) 기반 훈련을 통해 추론 성능을 대폭 향상시킨 Kimi k1.5 모델을 제시한다. 긴 맥락(long context) 확장과 개선된 정책 최적화를 기반으로 복잡한 기법(MCTS, 가치함수 등) 없이도 o1 수준의 성능을 달성했다.
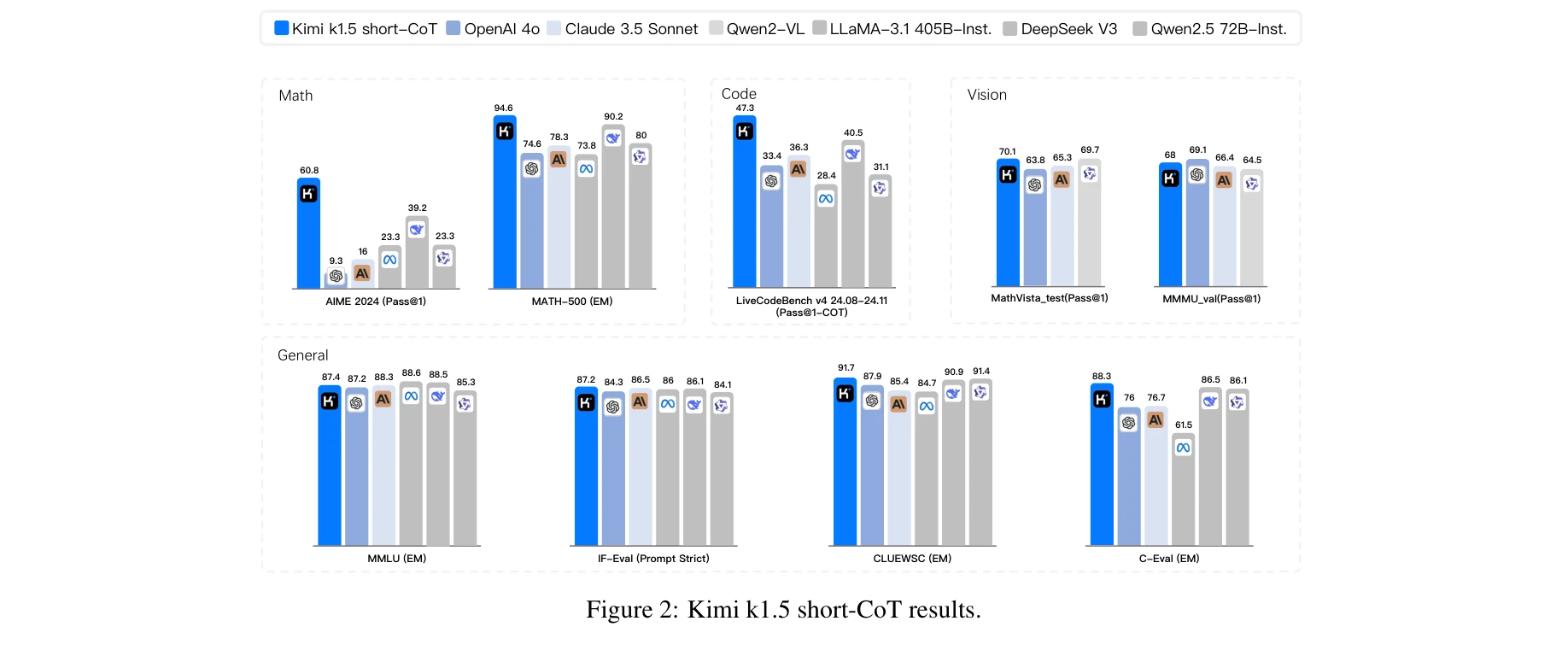
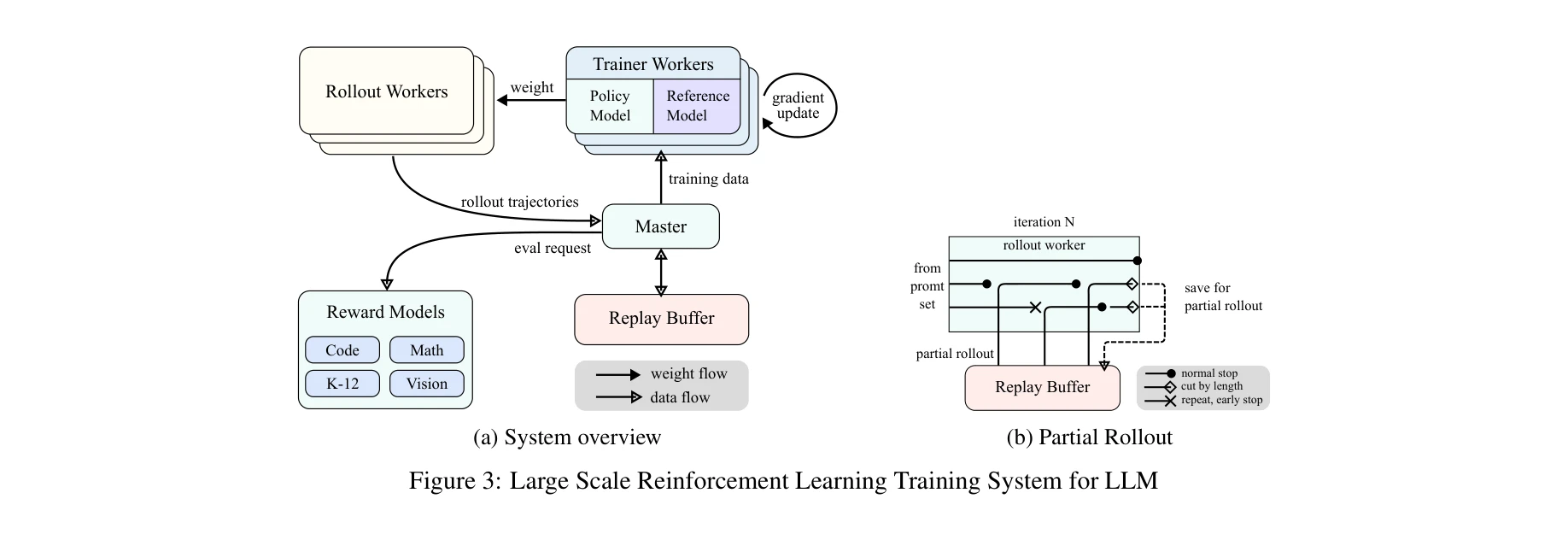
총평: 본 논문은 긴 맥락과 간단한 정책 최적화만으로 o1 수준의 추론 성능을 달성한 점에서 실질적 기여도가 크다. 특히 Long2Short 기법으로 단문 모델도 대폭 향상시킨 결과는 실무적 가치가 높으나, 훈련 데이터 공개 미흡과 이론적 근거 보강이 이루어진다면 더욱 설득력 있는 연구가 될 것으로 판단된다.