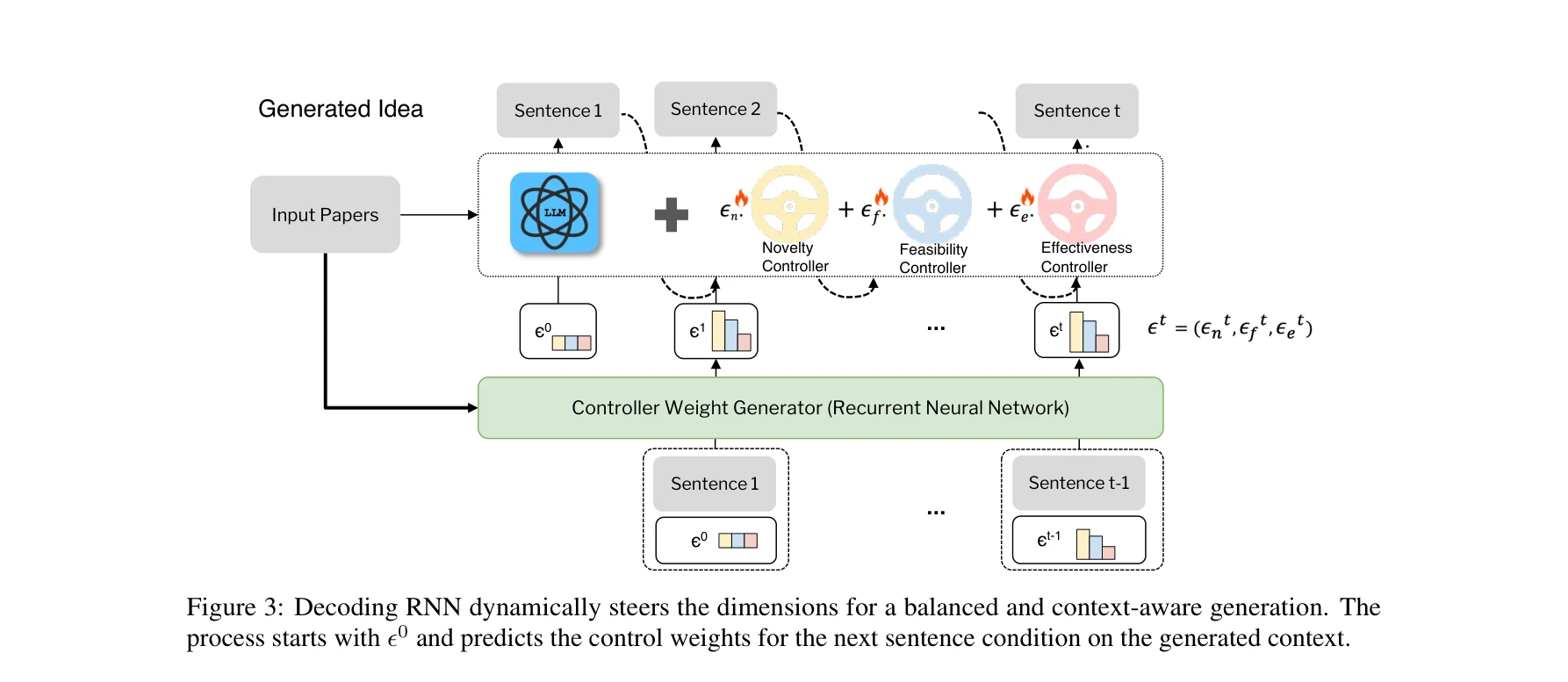
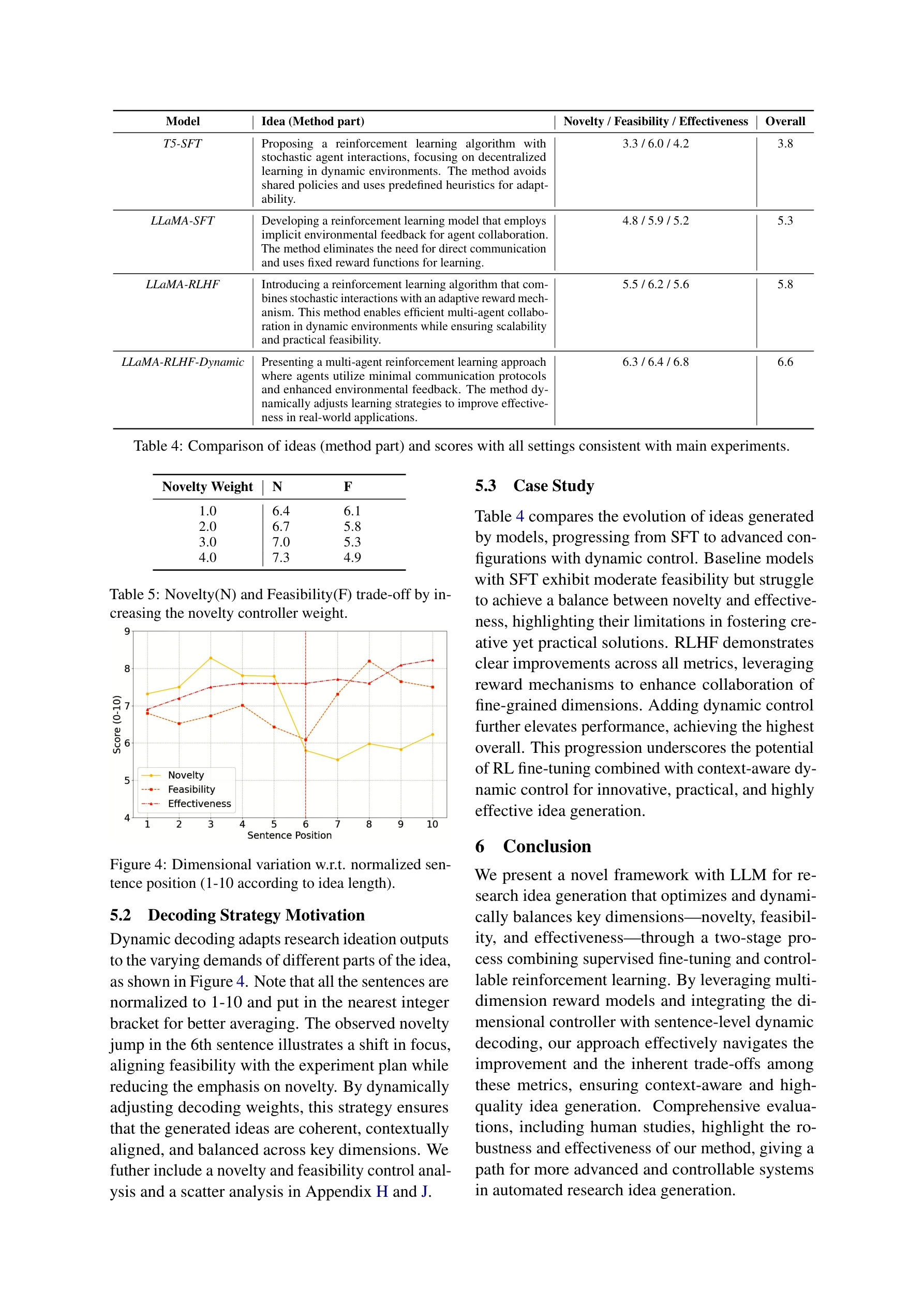
Essence
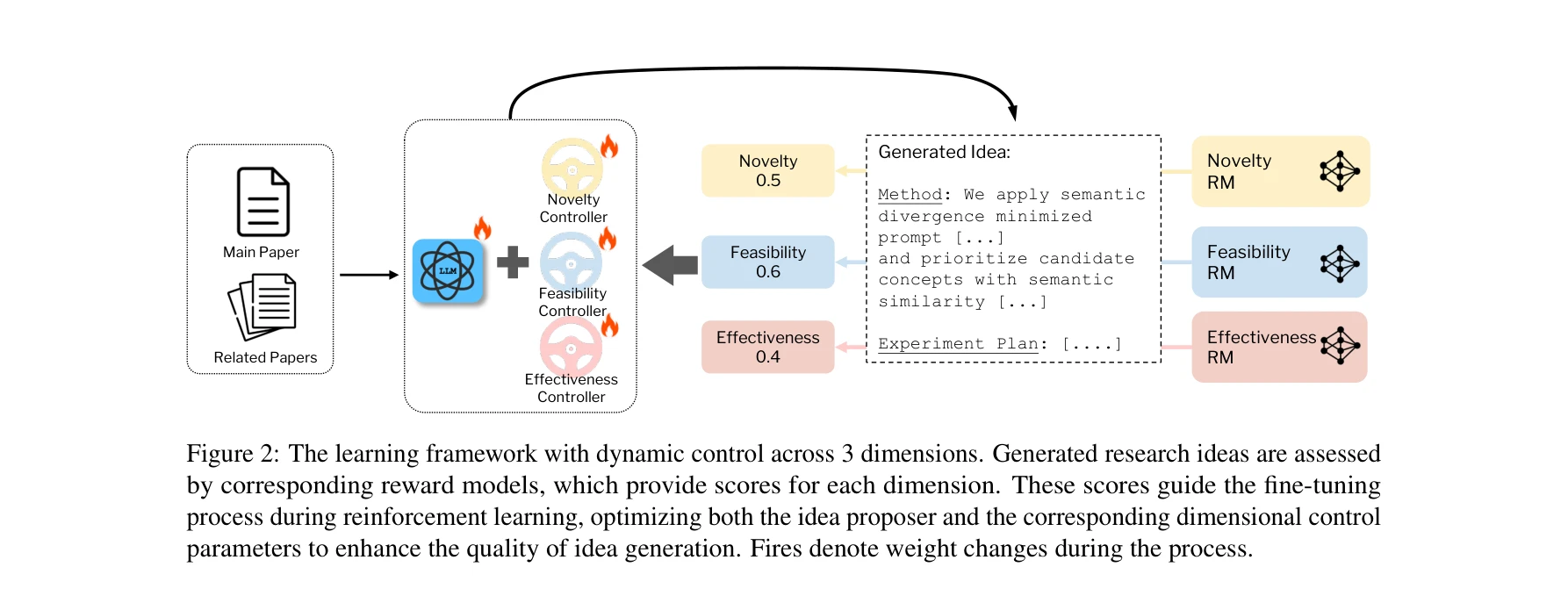
Figure 2: 3가지 차원에 걸친 동적 제어를 포함한 학습 프레임워크. 생성된 연구 아이디어는 각 차원에 대한 점수를 제공하는 보상 모델로 평가되며, 이는 강화학습 미세조정 과정 중에 아이디어 제안자와 차원별 제어 파라미터를 최적화하도록 안내
대규모 언어모델(LLM)을 활용하여 연구 아이디어 생성을 자동화하되, 참신성(novelty), 실현성(feasibility), 효과성(effectiveness)의 세 가지 핵심 차원 간의 균형을 동적으로 조정하는 두 단계 학습 프레임워크를 제시한다. 감독학습(SFT)과 제어 가능한 강화학습(RL)을 결합하여 차원별 보상 모델을 통해 미세한 피드백으로 최적화한다.