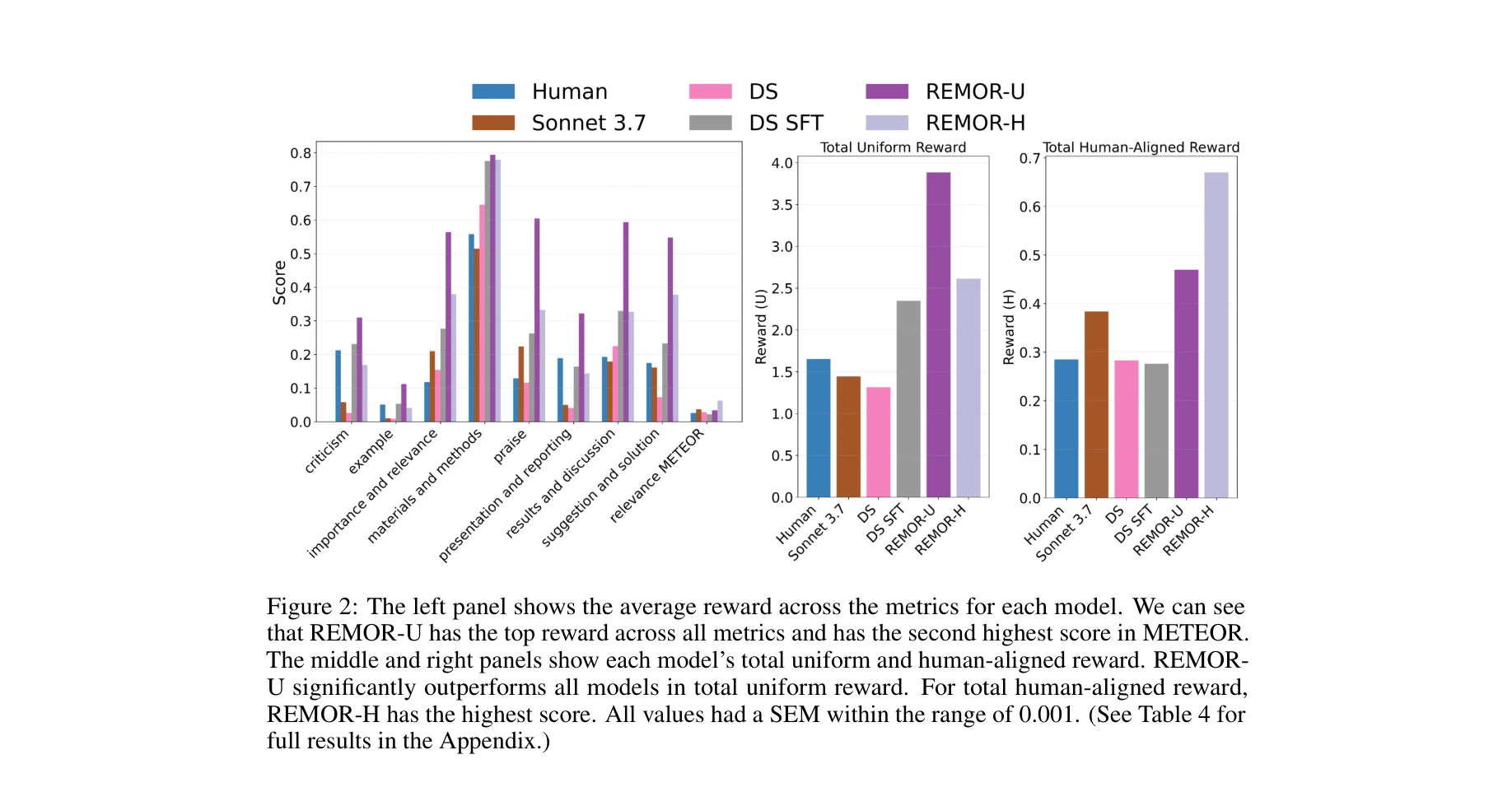
Essence
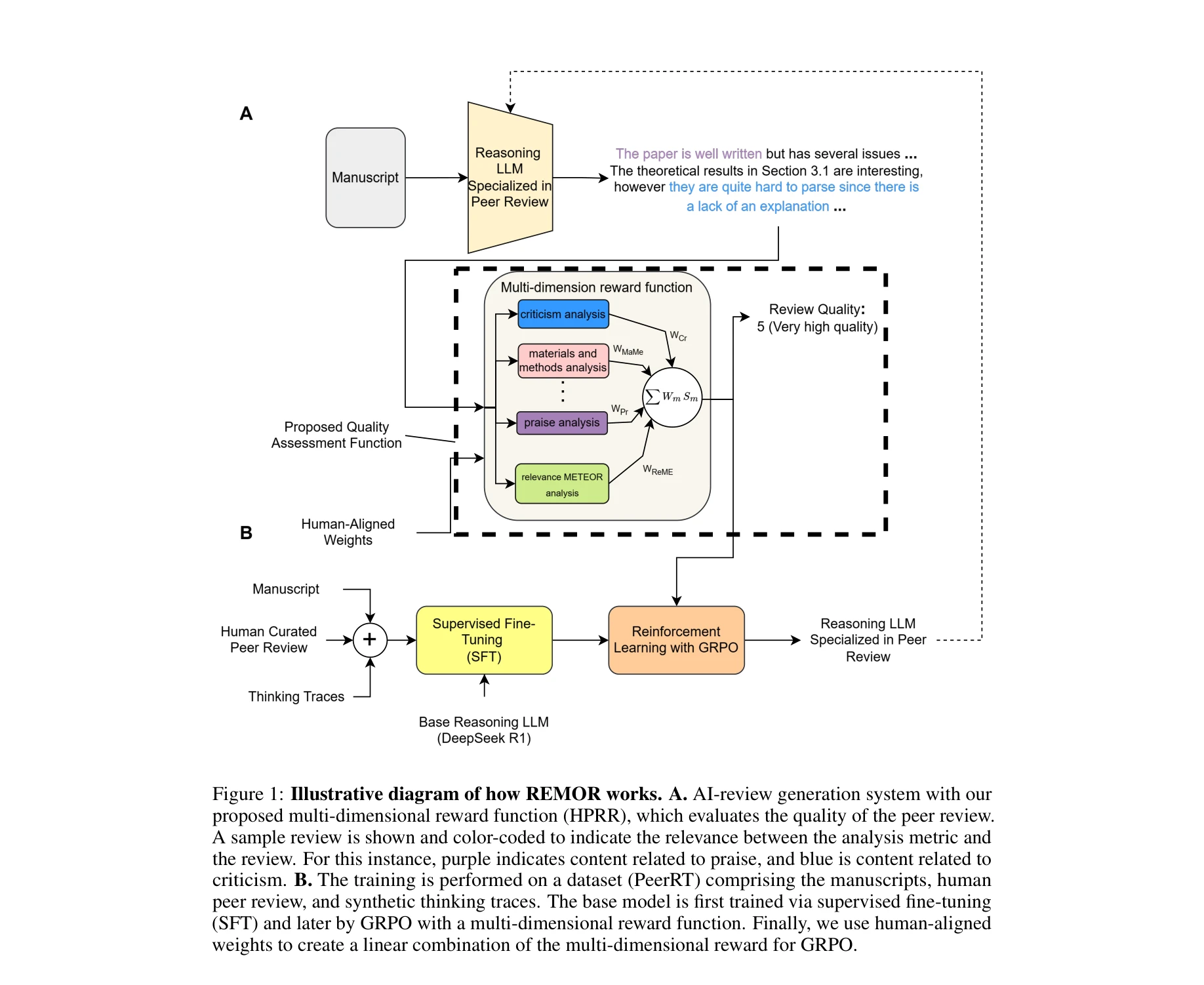
REMOR의 작동 방식: (A) 다중 차원 보상 함수(HPRR)를 통한 AI 리뷰 생성 시스템, (B) PeerRT 데이터셋을 이용한 감독 미세조정(SFT) 및 GRPO 학습 프로세스
본 논문은 추론(reasoning) 기능을 갖춘 대형언어모델(LLM)과 다목적 강화학습(MORL)을 결합하여 인간 수준 이상의 깊이 있고 균형잡힌 학술 논문 심사평을 자동 생성하는 REMOR 시스템을 제안한다. 기존 AI 심사평의 얕은 분석과 과도한 칭찬 문제를 다목적 보상함수와 추론 능력으로 극복한다.
Evaluation
Novelty: 4.5/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 3.5/5 Overall: 4/5
총평: REMOR은 추론과 강화학습을 심사평 생성에 창의적으로 결합하여 인간 수준 이상의 성능을 달성한 의미 있는 기여이다. 특히 다차원 보상함수와 PeerRT 데이터셋의 공개는 학계에 실질적 자산이 될 것이다. 다만 인간 평가의 규모, 보상함수 설계의 정당성, 타분야 일반화 가능성에 대한 더 깊은 검증이 논문의 영향력을 강화할 것이다.