저자: Yixuan Weng, Minjun Zhu, Guangsheng Bao, Hongbo Zhang, Jindong Wang, Yue Zhang, Linyi Yang | 날짜: 2024 | DOI: 10.48550/ARXIV.2411.00816
Essence
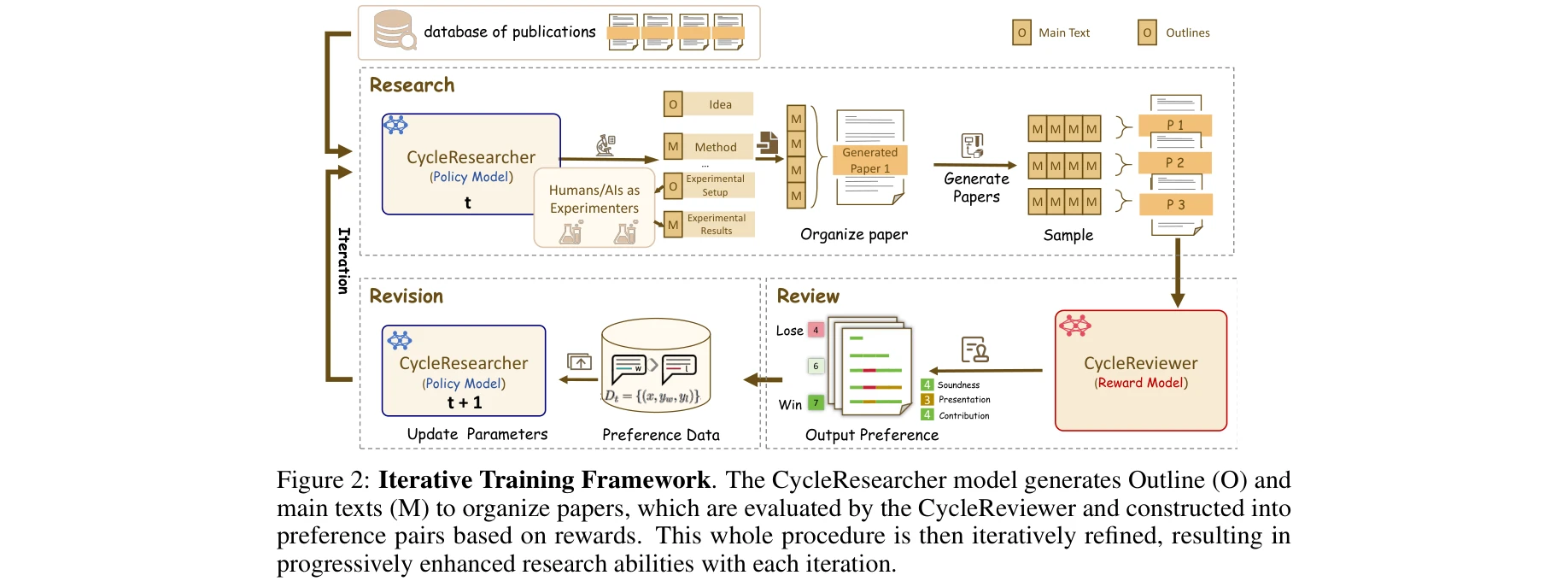
반복적 훈련 프레임워크: CycleResearcher가 논문을 생성하고 CycleReviewer가 평가하여 선호도 쌍을 구성한 후 정책을 최적화하는 사이클
본 논문은 오픈소스 LLM을 활용하여 논문 작성, 동료 검토, 수정의 전체 연구 사이클을 자동화하는 통합 프레임워크를 제안한다. CycleReviewer가 인간 리뷰어보다 26.89% 더 우수한 성능을 보이며, CycleResearcher가 생성한 논문이 인간 전문가 수준(5.36점)에 근접하는 성과를 달성했다.
Evaluation
총평: 본 논문은 오픈소스 LLM으로 전체 연구 수행-동료 검토-수정 사이클을 자동화하는 야심찬 시도로, CycleReviewer가 인간 리뷰어를 초과하는 성과와 대규모 고품질 데이터셋의 공개는 큰 기여이다. 다만 실험 검증의 시뮬레이션 성격, 도메인 일반화의 미흡, 그리고 학술 윤리 문제의 불완전한 처리가 지적되며, 이들이 해결될 경우 과학 자동화 분야에서 중요한 이정표가 될 가능성이 높다.