Achievement
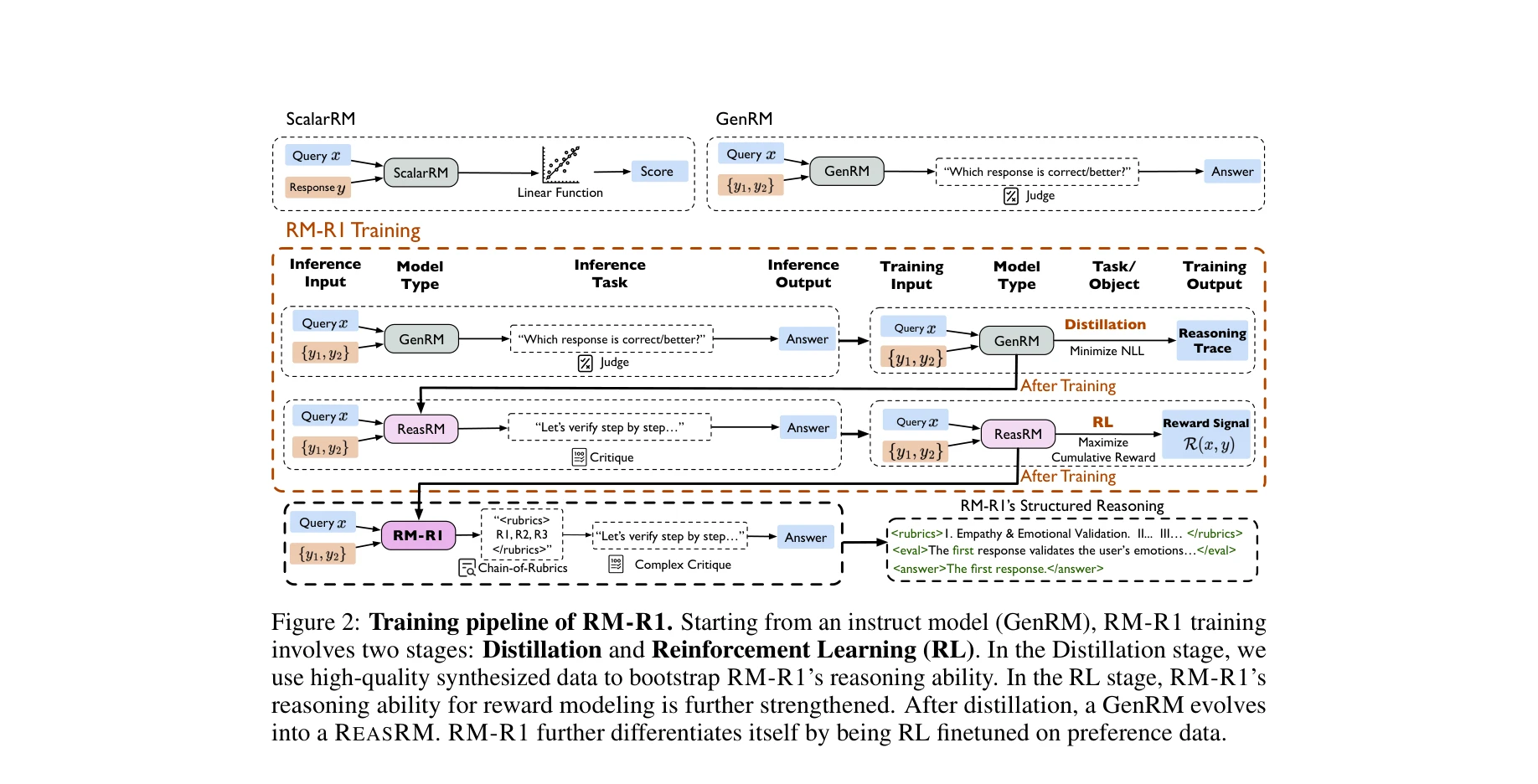
RM-R1의 훈련 파이프라인: 증류 단계에서 고품질 합성 데이터로 추론 능력을 부트스트랩하고, RL 단계에서 추가로 강화
- 벤치마크 성능: RewardBench, RM-Bench, RMB 세 가지 벤치마크에서 평균적으로 최고 성능 달성. 70B/340B 오픈웨이트 모델, GPT-4o, Claude 모델을 최대 4.9% 능가
- 해석 가능성: RM-R1은 일관되고 고도로 해석 가능한 추론 궤적(reasoning traces)을 생성하여 "왜 이 응답이 더 나은가"를 명확히 설명
- 스케일링 효율: 7B에서 32B까지의 모델 패밀리에서 일관된 성능 향상을 보여 스케일 효율성 입증