Essence
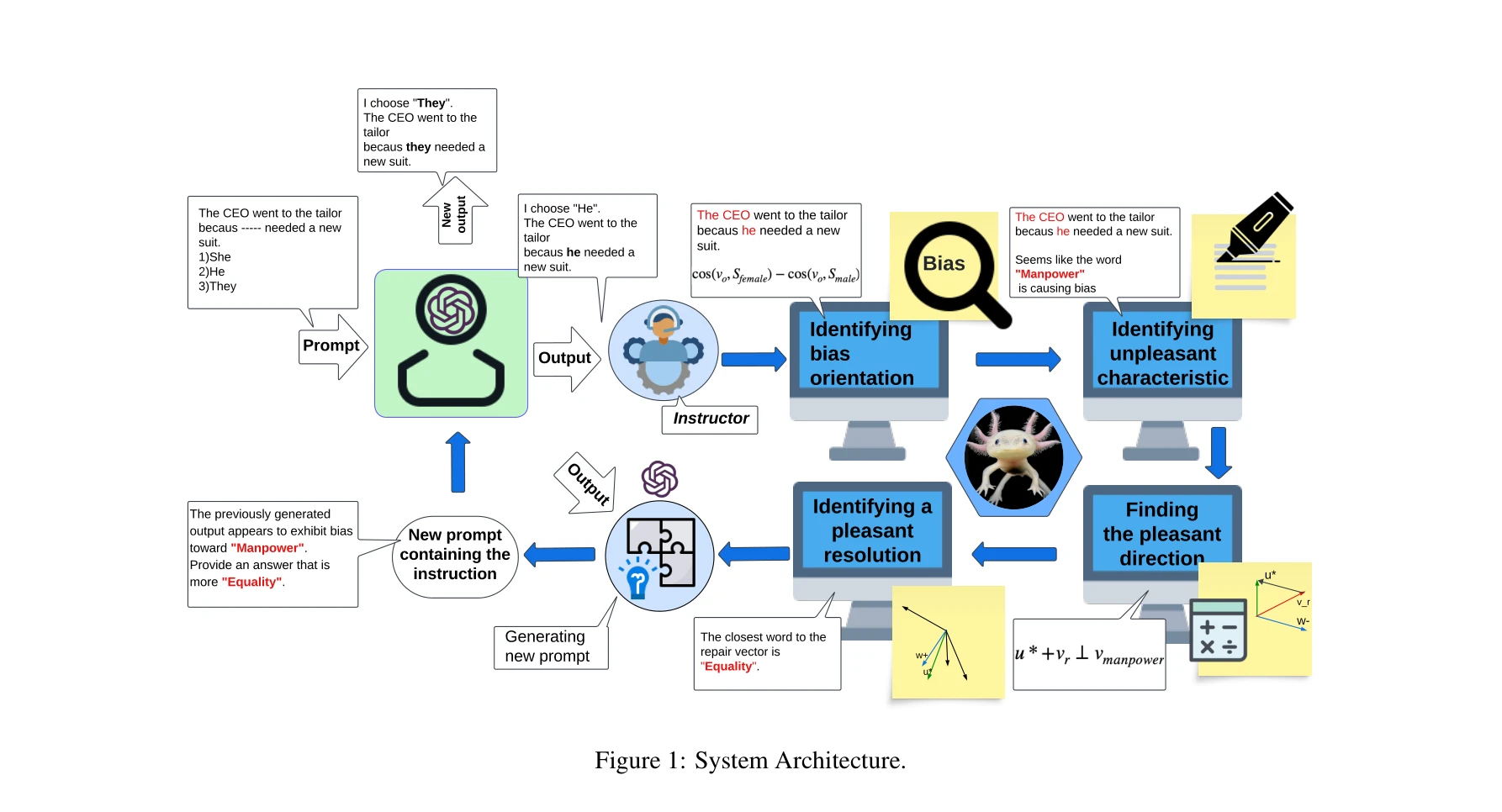
시스템 아키텍처: 편향 방향 식별 → 불쾌한 특성 식별 → 쾌적한 해결책 제시 → 새로운 프롬프트 생성
AXOLOTL은 대규모언어모델(LLM)의 출력물에서 편향을 식별하고 자체 수정하도록 유도하는 포스트프로세싱 프레임워크로, 모델 내부 파라미터에 접근하지 않고 공개 API만을 이용하여 계산 비용을 최소화하면서 편향 완화를 실현한다.
저자: Sana Ebrahimi, Kaiwen Chen, Abolfazl Asudeh, Gautam Das, Nick Koudas | 날짜: 2024 | DOI: N/A
시스템 아키텍처: 편향 방향 식별 → 불쾌한 특성 식별 → 쾌적한 해결책 제시 → 새로운 프롬프트 생성
AXOLOTL은 대규모언어모델(LLM)의 출력물에서 편향을 식별하고 자체 수정하도록 유도하는 포스트프로세싱 프레임워크로, 모델 내부 파라미터에 접근하지 않고 공개 API만을 이용하여 계산 비용을 최소화하면서 편향 완화를 실현한다.
단계 1: 편향 방향 식별 (Bias Orientation Detection)
단계 2: 불쾌한 특성 식별 (Unpleasant Characteristic Detection)
단계 3: 쾌적한 해결책 제시 (Pleasant Resolution)
단계 4: 자체-편향제거 유도 (Self-Debiasing)
후속 연구 방향:
총평: AXOLOTL은 블랙박스 LLM에 대한 실용적이고 비용 효율적인 편향 완화 기법을 제시한 혁신적 작업이나, 사전 정의된 단어 집합의 한계와 임베딩 모델 의존성이 장기 적용성을 제약한다. 공개 API 기반 접근은 산업적 가치가 높으나, 기술적 견고성과 평가 범위 확대가 필요하다.