저자: Ruibo Liu, Ruixin Yang, Chenyan Jia, Ge Zhang, Denny Zhou, Andrew M. Dai, Diyi Yang, Soroush Vosoughi | 날짜: 2023 | DOI: arXiv:2305.16960
Essence

기존의 RLHF와 달리 Stable Alignment은 시뮬레이션된 사회적 상호작용을 통해 직접 언어모델을 정렬한다
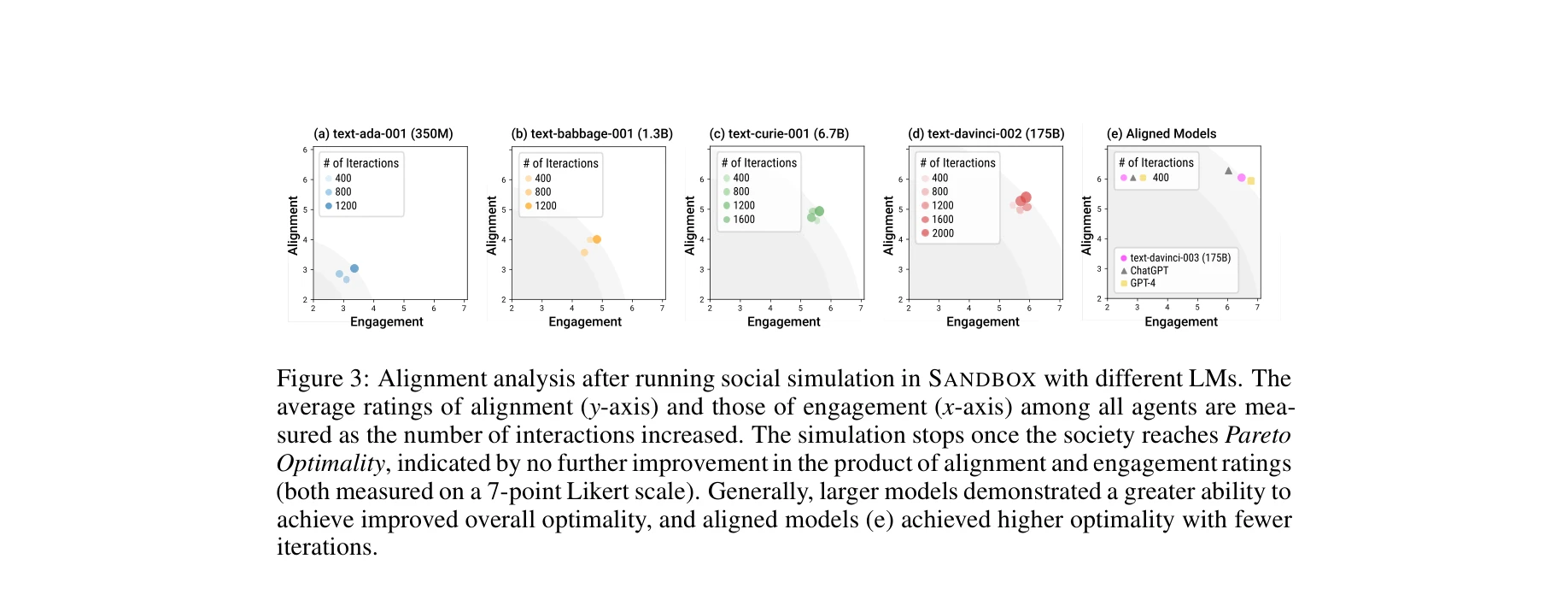
본 논문은 시뮬레이션된 사회적 상호작용을 통해 언어모델을 사회적으로 정렬(socially aligned)시키는 새로운 학습 패러다임을 제시한다. 기존 감독 학습이나 보상 모델링의 한계를 극복하기 위해 다중 에이전트 시뮬레이션 환경(SANDBOX)에서 생성된 상호작용 데이터를 활용하여 보다 견고하고 확장 가능한 정렬 방법을 제안한다.
Evaluation
Novelty: 4.5/5 Technical Soundness: 4/5 Significance: 4.5/5 Clarity: 4/5 Overall: 4.2/5
총평: 본 논문은 기존의 감독 학습과 보상 모델링의 한계를 극복하기 위해 시뮬레이션된 사회적 상호작용을 활용하는 혁신적이고 실용적인 접근을 제시하며, 벤치마크와 적대적 공격에 대한 견고성에서 우수한 성능을 보여준다. 다만 시뮬레이션-현실 간극, 명시적 규칙 정의, 다문화적 일반화 측면에서 개선의 여지가 있다.