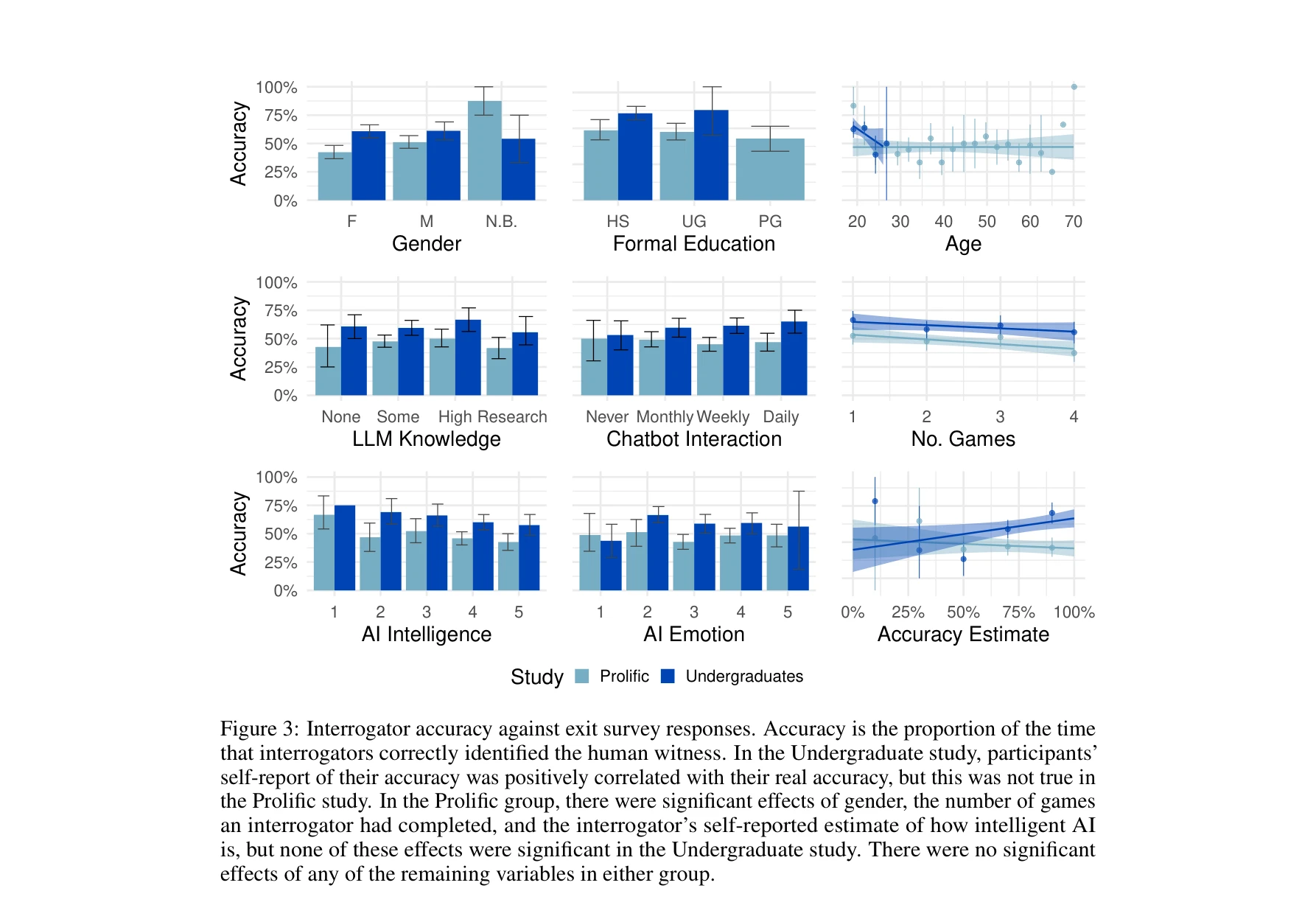
Essence
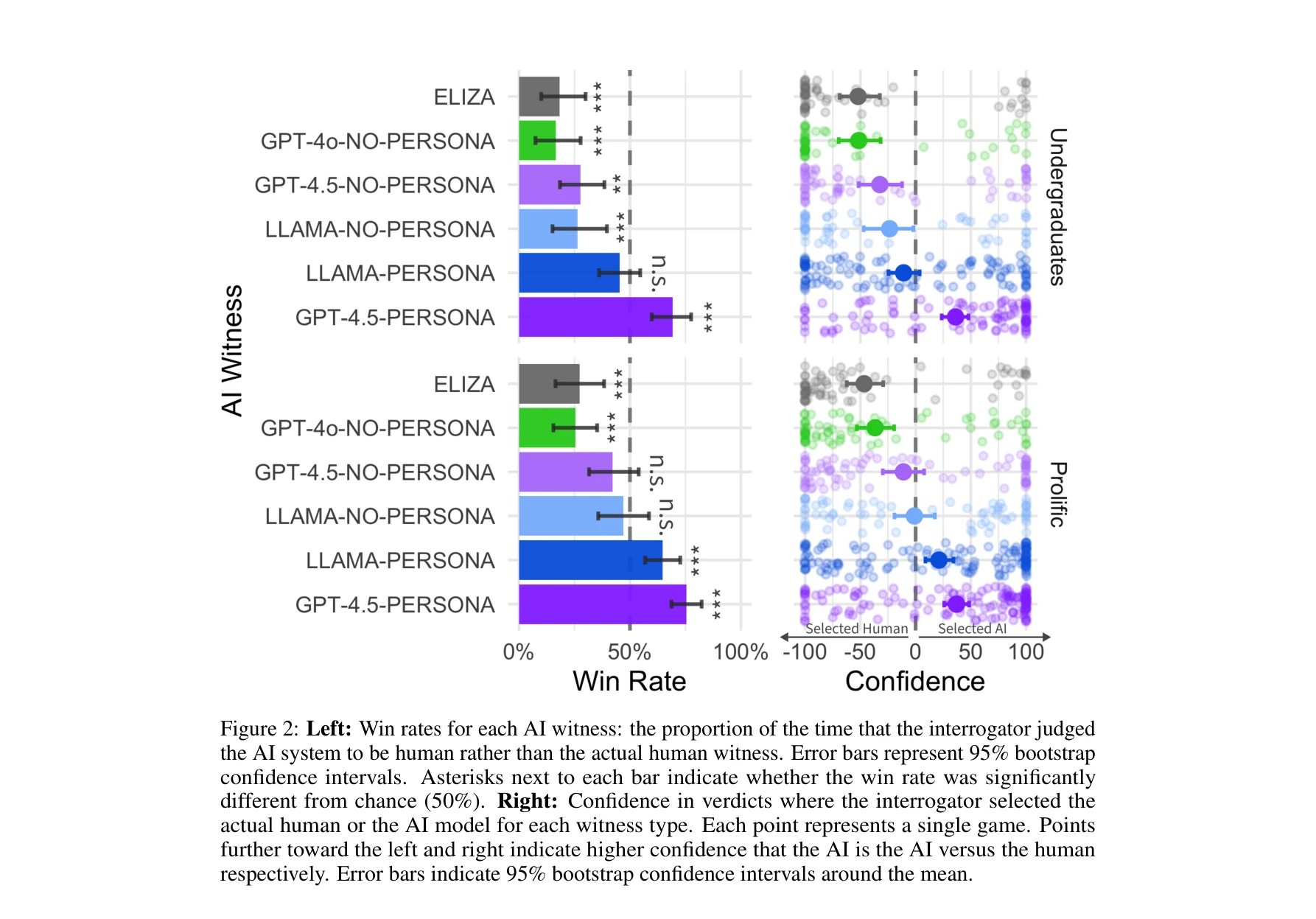
각 AI 증인의 승률(interrogator가 AI 시스템을 인간으로 판단한 비율). 오차막대는 95% 부트스트랩 신뢰구간을 나타냄
본 논문은 현대 대규모 언어모델(LLM)이 튜링 테스트(Turing test)의 세 명 참가자 버전을 최초로 통과했음을 보여주는 실증적 증거를 제시한다. GPT-4.5가 적절한 페르소나(persona) 프롬프트 하에서 73%의 확률로 인간으로 판단되었으며, 이는 실제 인간 참가자보다 유의미하게 높은 비율이다.