Achievement
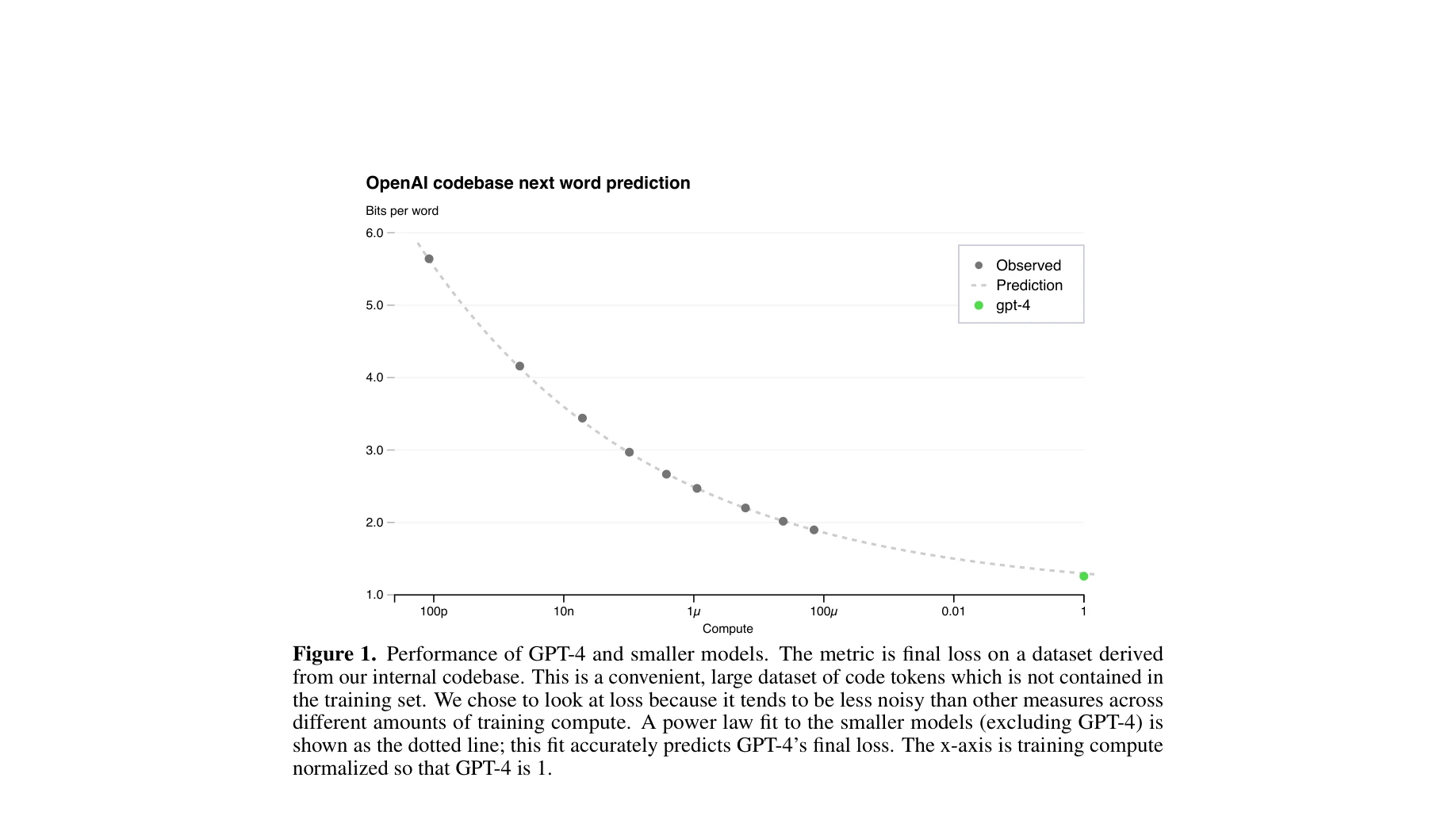
그림 1: GPT-4 및 소규모 모델의 성능. 내부 코드베이스 데이터셋에서의 최종 손실값(bits per word). 소규모 모델로부터의 전력 법칙 적합이 GPT-4의 최종 손실을 정확히 예측.
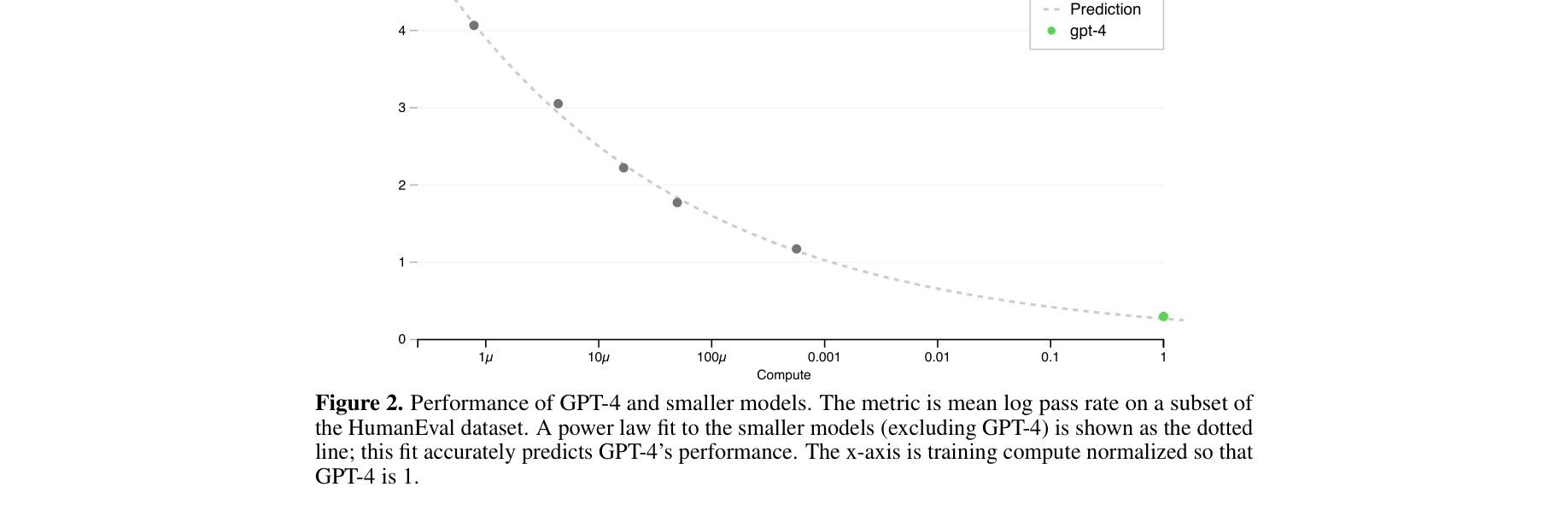
그림 2: HumanEval 부분집합에서의 평균 로그 통과율. 전력 법칙 적합이 GPT-4 성능을 매우 정확히 예측.
- 확장 법칙의 정확한 예측: 손실값(loss) 예측에서 L(C) = aC^b + c 형태의 전력 법칙을 사용하여 GPT-4의 최종 손실을 높은 정확도로 사전 예측. 코딩 능력(HumanEval)도 −E_P[log(pass_rate(C))] = α·C^−k 관계로 1,000배 이상 작은 모델로부터 정확히 예측.
- 인간 수준의 시험 성적: 법학시험(Bar Exam) 상위 10%, LSAT 상위 12%, SAT 수학 상위 11%, GRE 언어 상위 1% 수준의 성능 달성. 기존 GPT-3.5는 법학시험에서 하위 10%였음.
- 다언어 우수성: MMLU 벤치마크 26개 언어 중 24개에서 영어 최고 성능(SOTA) 초과.
- 역확장 현상 해결: Inverse Scaling Prize의 Hindsight Neglect 과제에서 기존 모델은 규모가 클수록 성능 저하를 보였으나, GPT-4는 이 추세를 반전시킴.
- 멀티모달 능력: 이미지와 텍스트를 동시에 처리 가능하며, 비전 기능 제거 후에도 대부분의 시험에서 동일하거나 유사한 성능 유지.