저자: DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bowen Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fengze Dai, Fuli Luo | 날짜: 2024 | DOI: arXiv:2412.19437v2
Essence
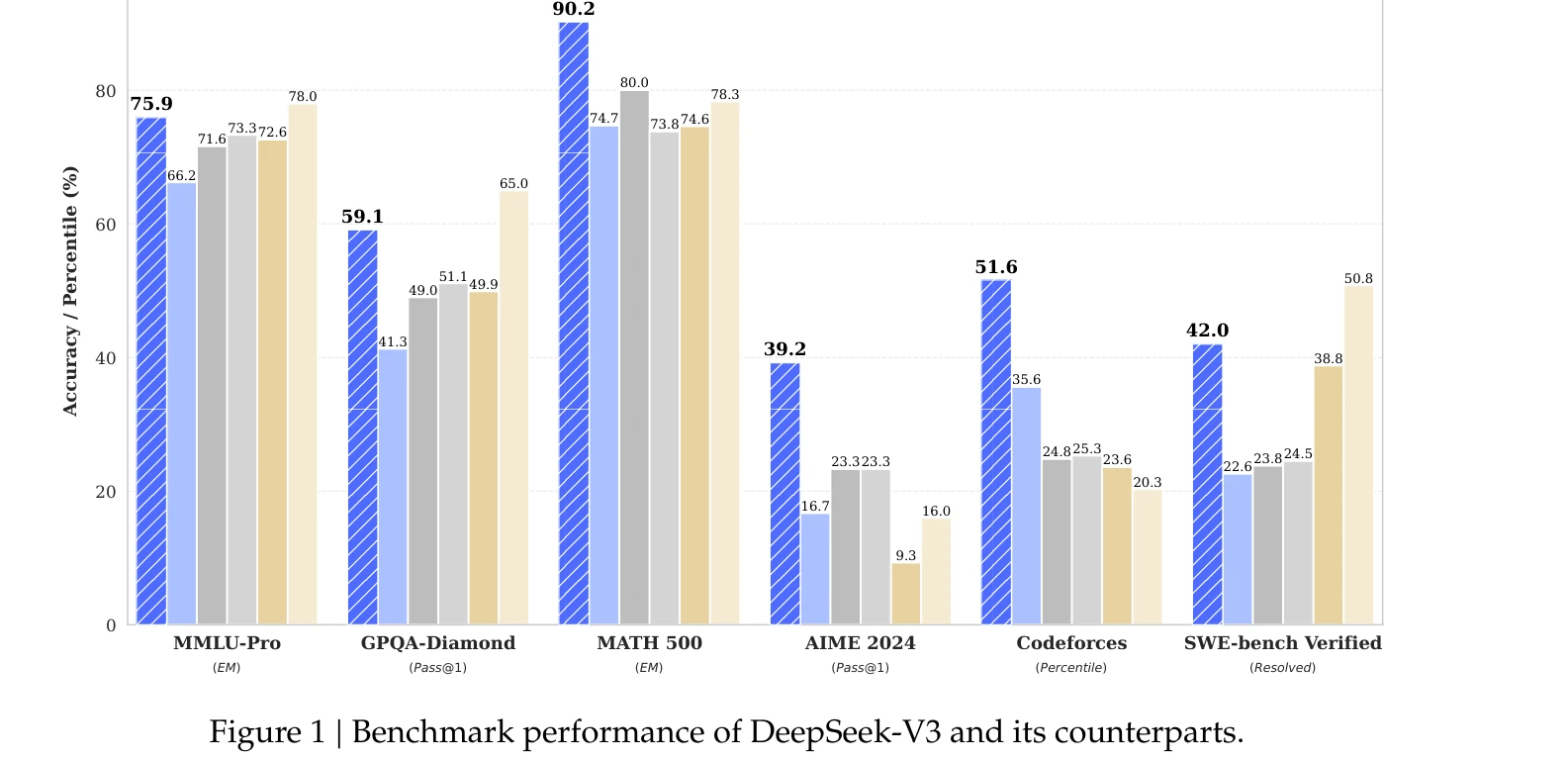
그림 1: DeepSeek-V3와 동종 모델들의 벤치마크 성능 비교
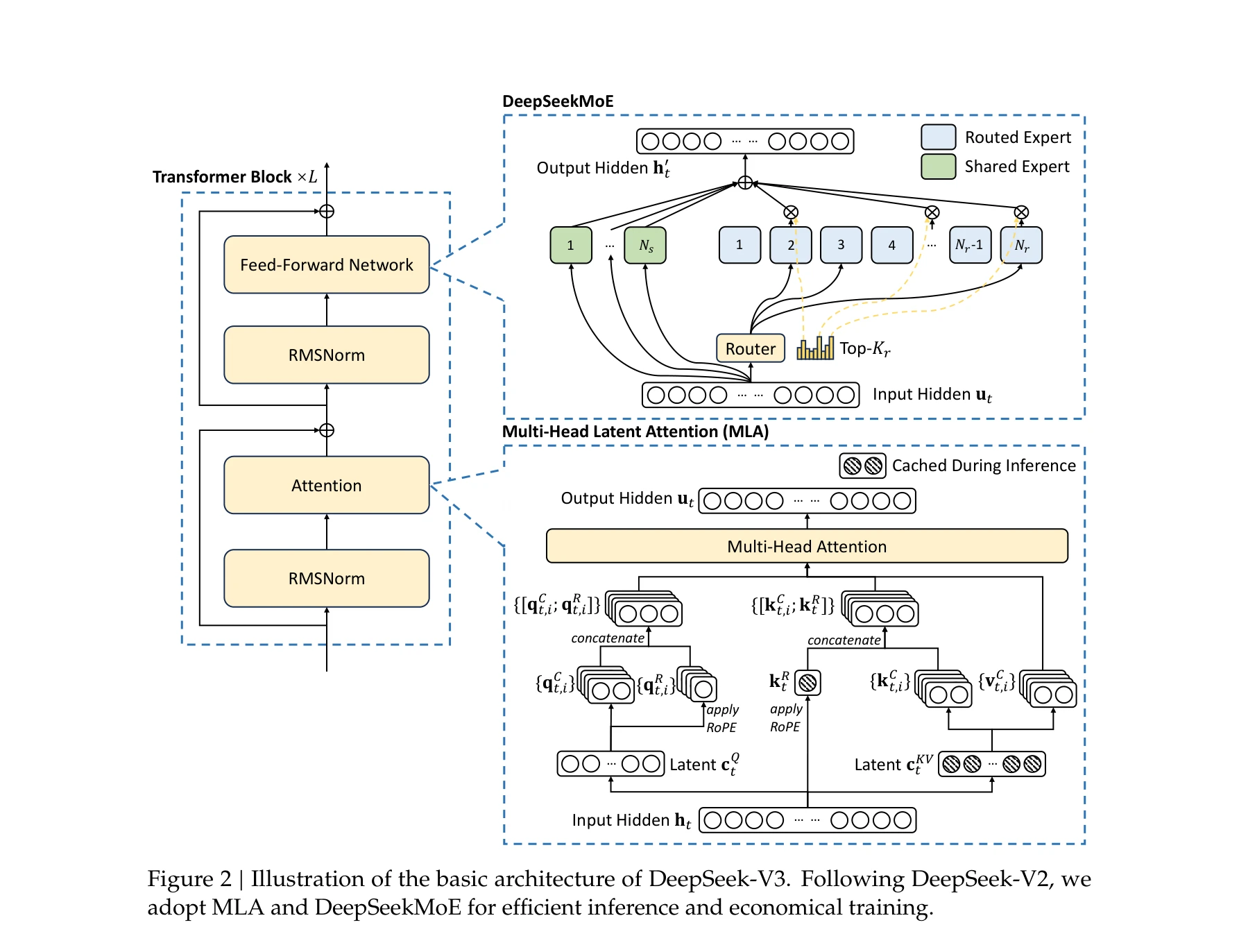
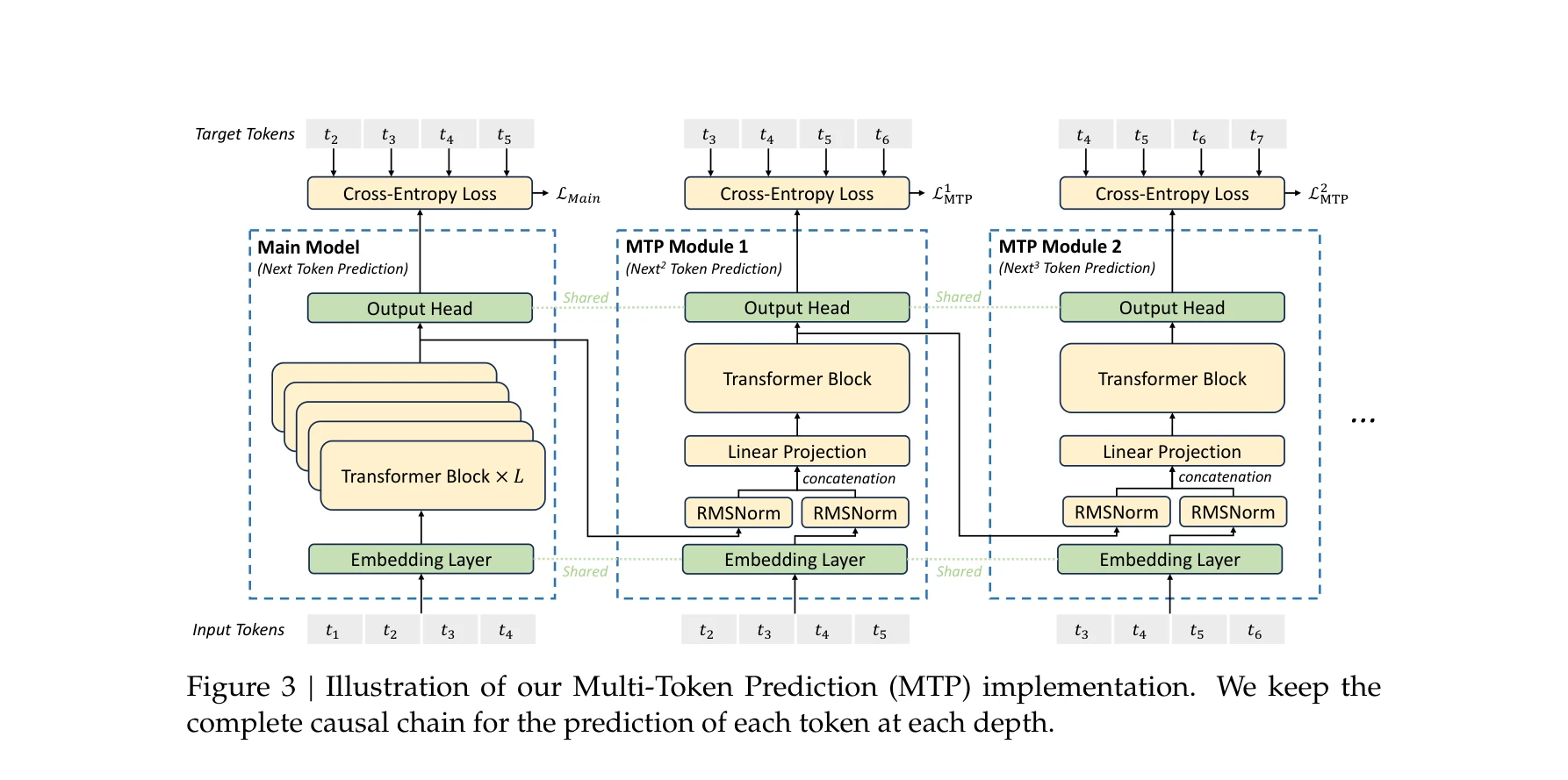
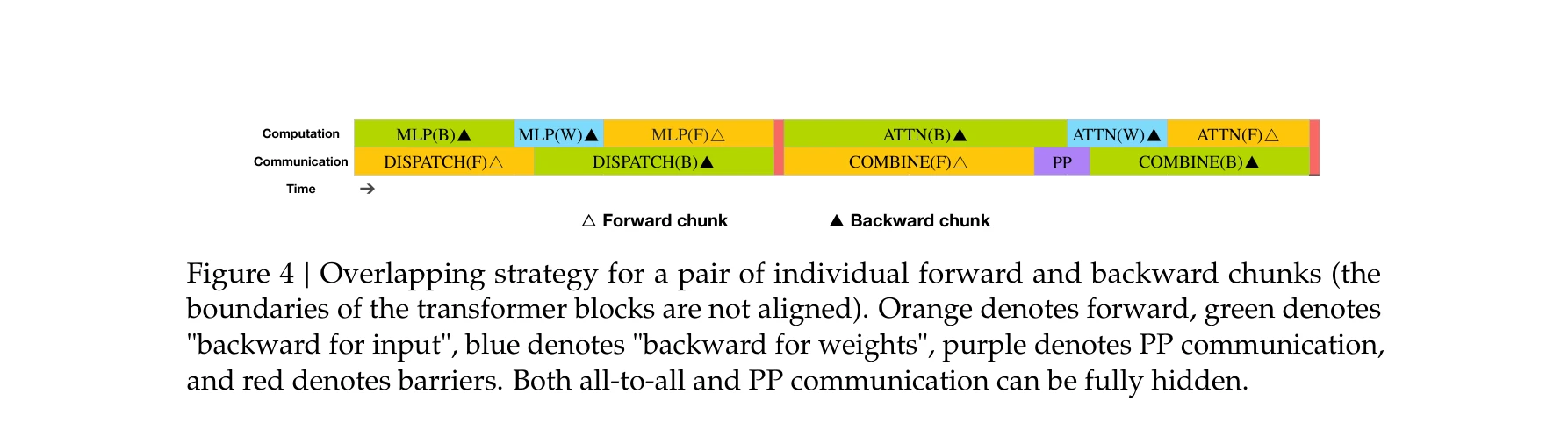
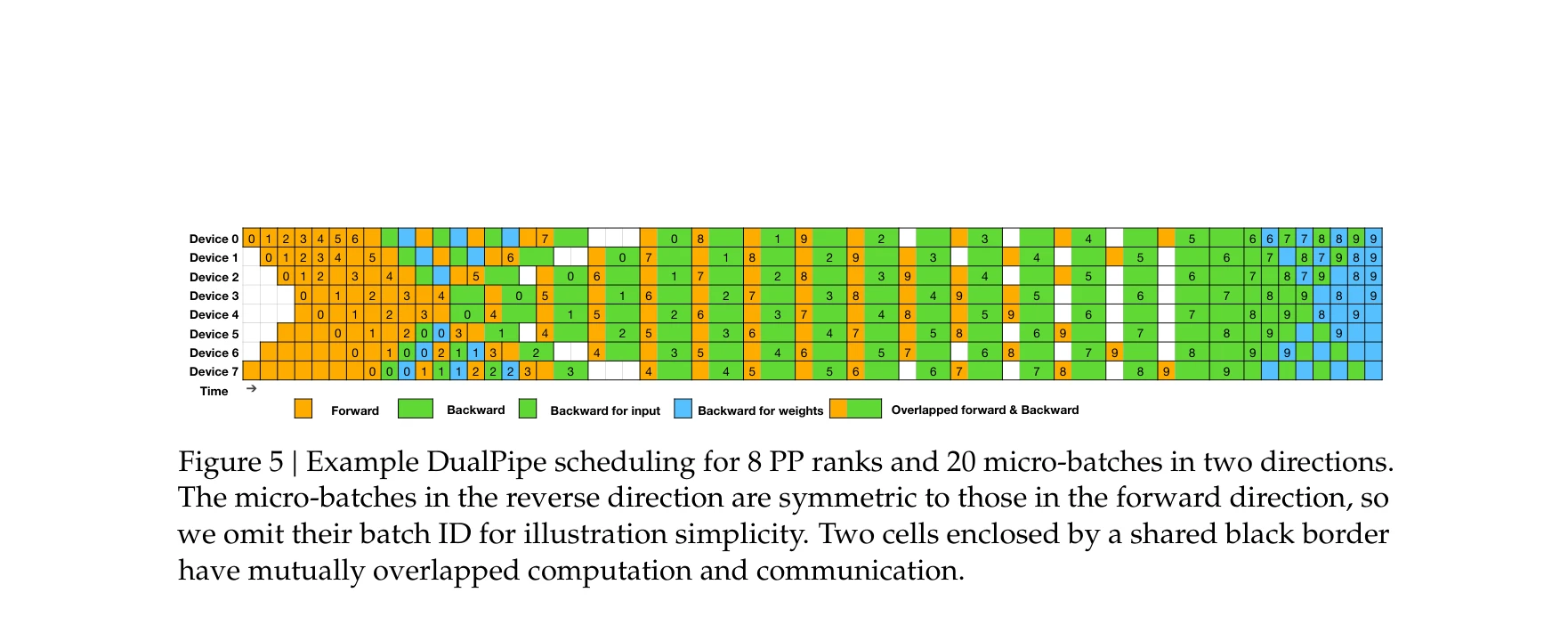
671B 매개변수를 가진 혼합 전문가(Mixture-of-Experts, MoE) 언어 모델 DeepSeek-V3를 제시하며, 토큰당 37B만 활성화되어 효율적 추론을 실현한다. 보조 손실 없는 부하 균형 전략과 다중 토큰 예측(Multi-Token Prediction, MTP) 목표를 도입하여 뛰어난 성능을 달성하면서도 2.788M H800 GPU 시간이라는 경제적 훈련 비용으로 완성했다.
Evaluation
총평: DeepSeek-V3는 아키텍처 혁신(보조 손실 제거, 다중 토큰 예측), 훈련 최적화(FP8, DualPipe, 계산-통신 중첩), 사후 훈련 고도화(R1 증류)를 통해 개방형 모델의 성능 한계를 획기적으로 상향 조정하면서도 훈련 비용을 대폭 절감한 획기적 기여를 달성했다. 다만 데이터 구성 세부 정보 공개 부재와 하드웨어 특화 최적화의 이식성 문제가 향후 과제로 남아있다.