Essence
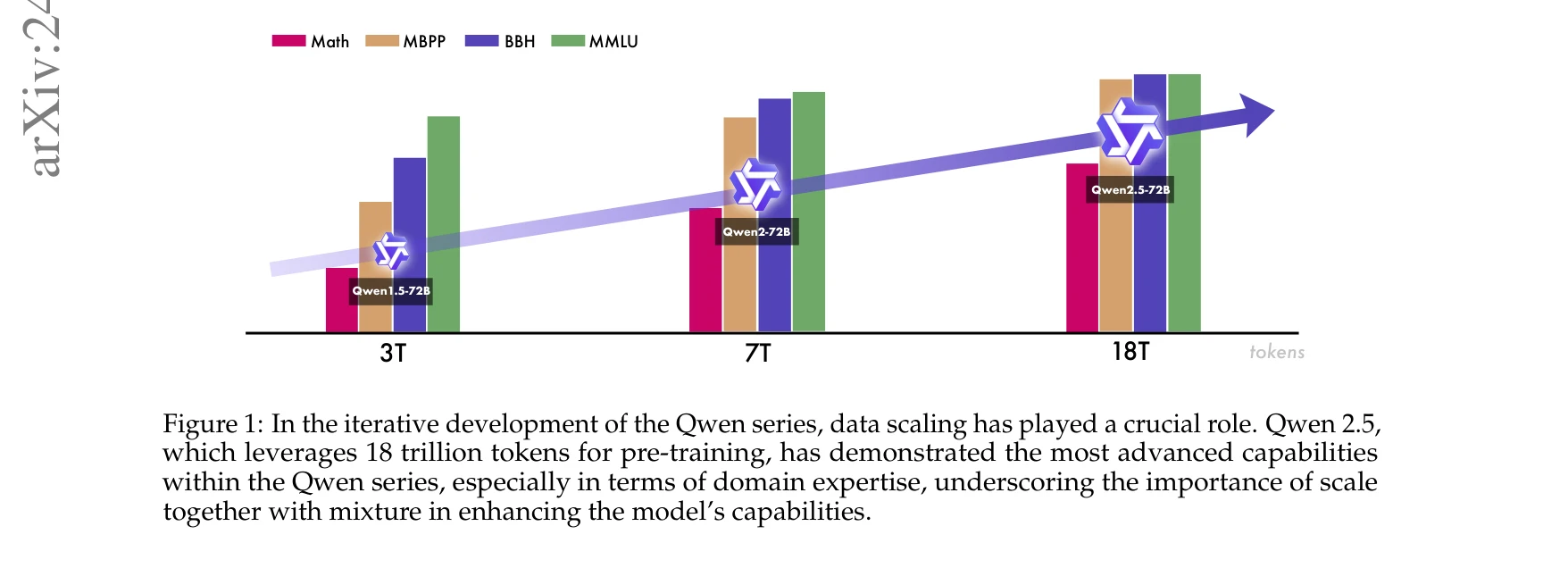
Qwen 시리즈의 반복적 개발 과정에서 데이터 스케일링의 중요성을 시각화. Qwen2.5는 18조 토큰으로 사전학습되어 수학, MBPP, BBH, MMLU 벤치마크에서 우수한 성능을 보임.
본 논문은 Qwen2.5 대규모 언어 모델(LLM) 시리즈를 소개하며, 사전학습 데이터를 7조에서 18조 토큰으로 확대하고, 감독 미세조정(SFT), 직접 선호도 최적화(DPO), 그룹 상대 정책 최적화(GRPO) 등 고도화된 후학습 기법을 적용하여 이전 버전 대비 대폭 향상된 성능을 달성했다.