Essence
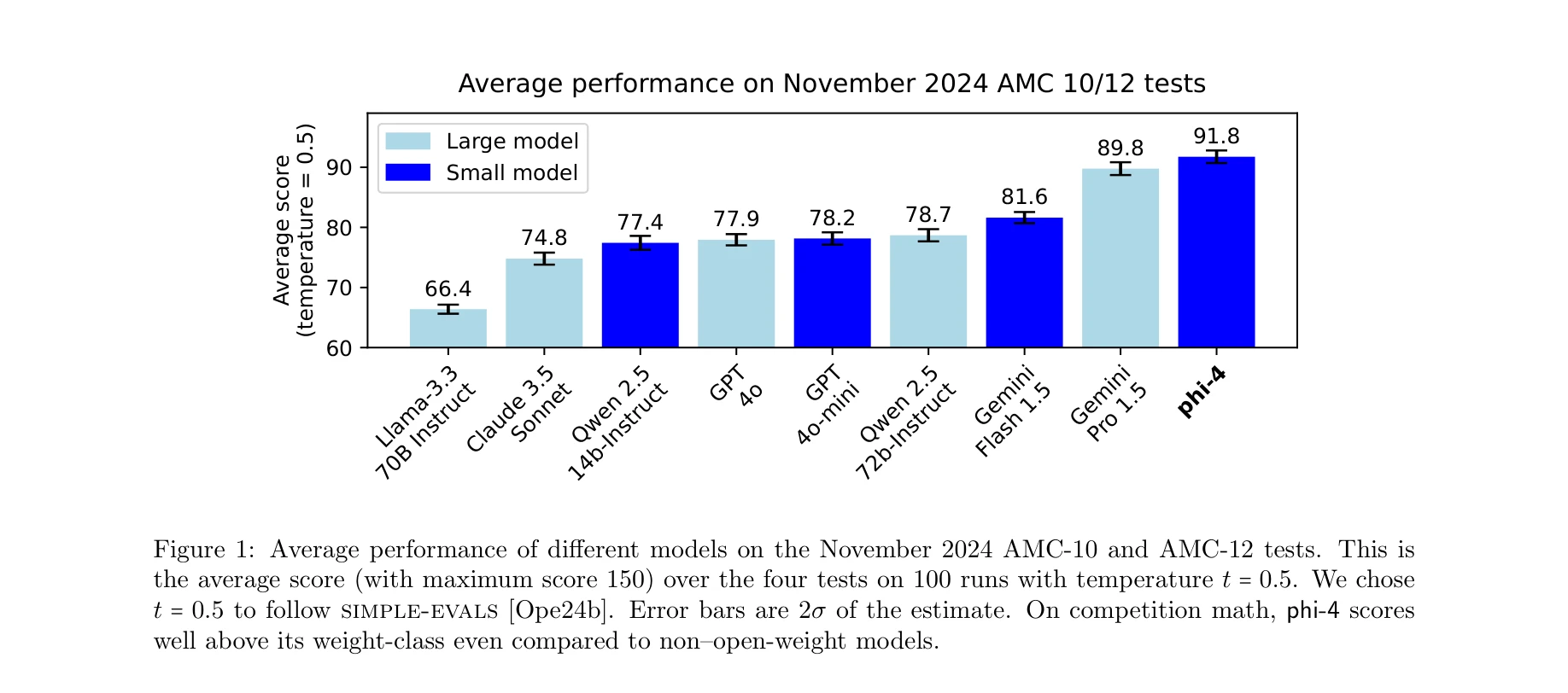
Figure 1: 2024년 11월 AMC-10/12 시험에서 다양한 모델의 평균 성능 비교
Phi-4는 140억 개 파라미터의 언어 모델로, 고품질 합성 데이터 중심의 학습 레시피를 통해 개발되었으며, 교사 모델인 GPT-4o를 STEM 기반 질의응답 벤치마크에서 능가하는 성능을 달성했다. 특히 추론 관련 작업에서 훨씬 큰 모델들과 비슷하거나 우수한 성능을 보인다.
저자: Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael R. Harrison, Russell J. Hewett, Mojan Javaheripi, Piero Kauffmann, James R. Lee, Yin Tat Lee, Yuanzhi Li, Weishung Liu, Caio César Teodorio Mendes, Anh Nguyen, Eric Price, Gustavo de Rosa, Olli Saarikivi, Adil Salim | 날짜: 2024 | DOI: arXiv:2412.08905
Figure 1: 2024년 11월 AMC-10/12 시험에서 다양한 모델의 평균 성능 비교
Phi-4는 140억 개 파라미터의 언어 모델로, 고품질 합성 데이터 중심의 학습 레시피를 통해 개발되었으며, 교사 모델인 GPT-4o를 STEM 기반 질의응답 벤치마크에서 능가하는 성능을 달성했다. 특히 추론 관련 작업에서 훨씬 큰 모델들과 비슷하거나 우수한 성능을 보인다.
Figure 1: Phi-4의 경쟁 수학 문제(AMC-10/12) 성능 비교
총평: Phi-4는 고품질 합성 데이터 중심의 전략적 학습 설계를 통해 소규모 모델의 성능 한계를 획기적으로 극복한 우수한 사례이다. 특히 신선한 경시대회 데이터에서의 검증과 교사 모델 능가의 결과는 데이터 품질의 중요성을 명확히 보여주며, 향후 효율적인 언어 모델 개발의 중요한 방향성을 제시한다. 다만 생성 방법론의 완전한 자동화, 다양한 도메인으로의 확대 적용, 그리고 이론적 기초에 대한 심화 연구가 후속 과제로 남아 있다.