How
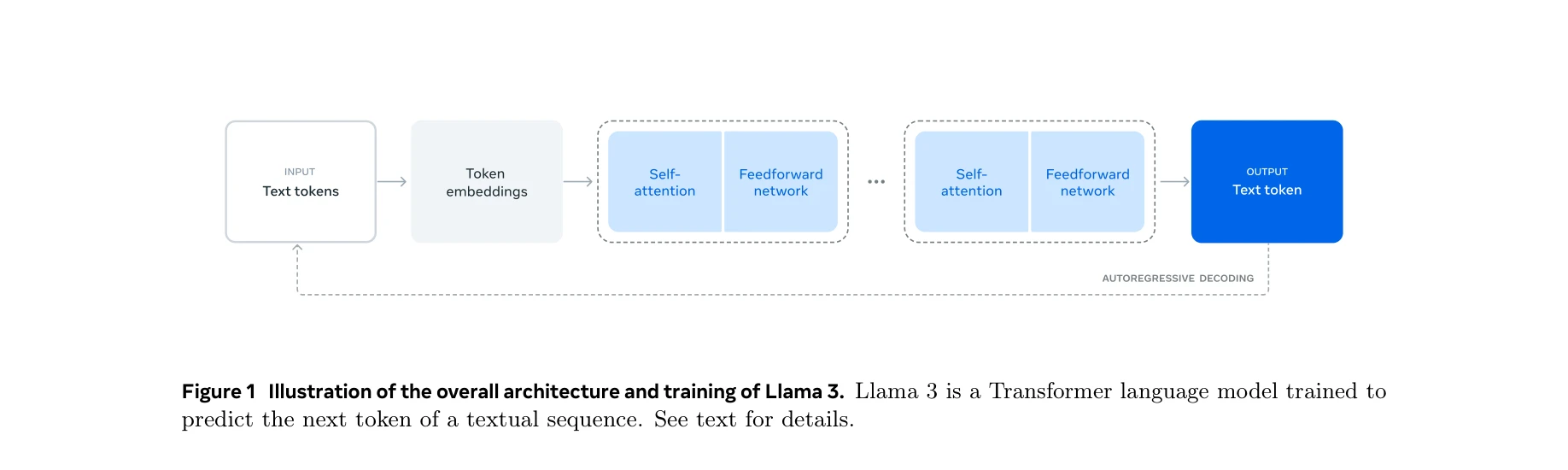
사전학습 (Pre-training)
- 데이터 큐레이션: 웹, 학술 자료, 코드 등 다양한 소스에서 15T 토큰 수집
- PII 및 성인 콘텐츠 제거 필터링
- 맞춤형 HTML 파서로 보일러플레이트 제거 및 콘텐츠 정확도 향상
- 수학/코드 구조 보존 처리
- 모델 아키텍처: 표준 Transformer (밀집형/Dense), 혼합 전문가 모델(MoE) 미채택
- 스케일링: 405B 파라미터, 8K→128K 토큰 윈도우 지속 학습
- 4D 병렬 처리: TP(Tensor Parallelism), CP(Context Parallelism), PP(Pipeline Parallelism), DP(Data Parallelism)
사후학습 (Post-training)
- 지도학습 미세조정(SFT): 지시 튜닝 데이터로 1차 정렬
- 거부 샘플링(RS): 고품질 응답 선별
- 직접 선호도 최적화(DPO): 인간 피드백 기반 정렬 (강화학습 대신 채택)
멀티모달 확장 (미출시)
- 이미지 인코더: 이미지-텍스트 쌍으로 사전학습
- 음성 인코더: 자체 감독 학습(마스킹 기반)
- 어댑터: 크로스-어텐션 레이어로 시각/음성 표현을 언어모델에 정렬