Essence
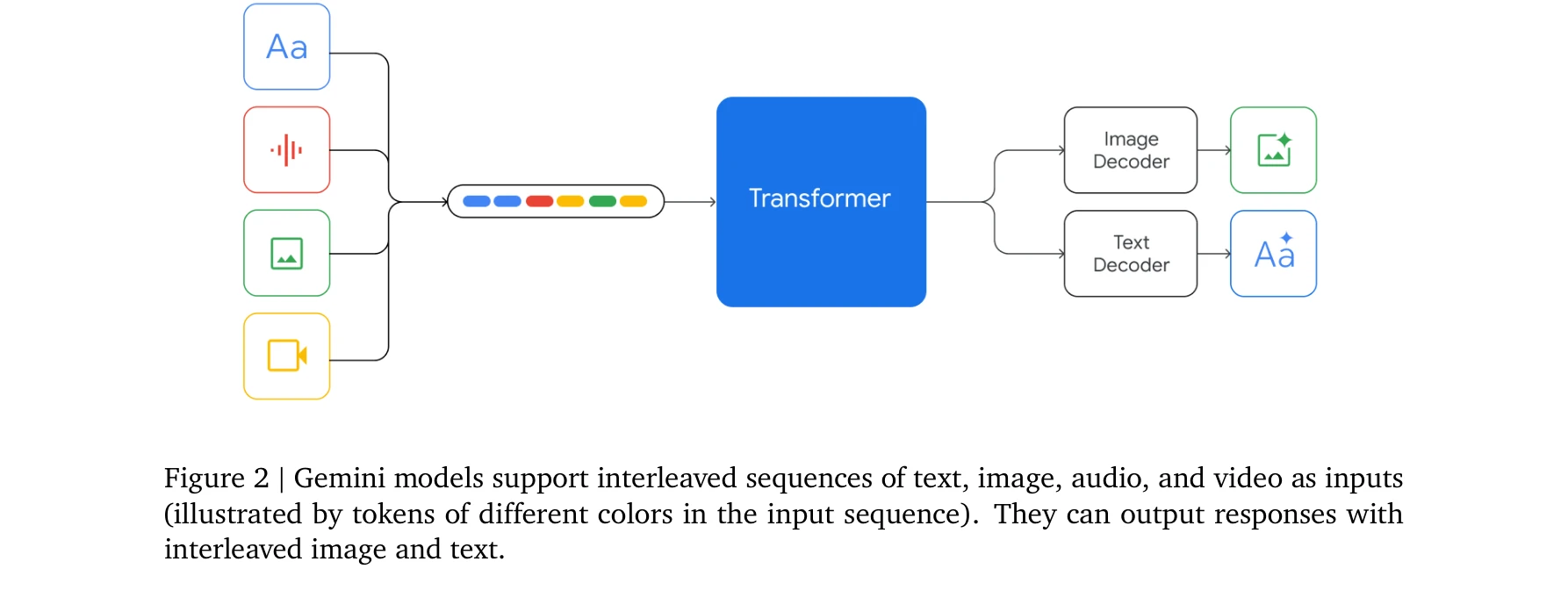
Gemini 모델은 텍스트, 이미지, 오디오, 비디오의 인터리빙된 시퀀스를 입력으로 받아 텍스트와 이미지가 섞인 응답을 생성할 수 있다.
Google이 개발한 Gemini는 이미지, 오디오, 비디오, 텍스트를 네이티브하게 처리하는 멀티모달 대규모 언어 모델 패밀리로, Ultra, Pro, Nano 세 가지 크기로 제공되며 30개의 32개 벤치마크 중에서 최첨단 성능을 달성한다.
저자: Gemini Robotics Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, Katie Millican, David M. Silver, Melvin Johnson, Ioannis Antonoglou, Julian Schrittwieser, Amelia Glaese, Jilin Chen, Emily Pitler, Timothy Lillicrap, Angeliki Lazaridou, Orhan Fırat | 날짜: 2023 | DOI: N/A
Gemini 모델은 텍스트, 이미지, 오디오, 비디오의 인터리빙된 시퀀스를 입력으로 받아 텍스트와 이미지가 섞인 응답을 생성할 수 있다.
Google이 개발한 Gemini는 이미지, 오디오, 비디오, 텍스트를 네이티브하게 처리하는 멀티모달 대규모 언어 모델 패밀리로, Ultra, Pro, Nano 세 가지 크기로 제공되며 30개의 32개 벤치마크 중에서 최첨단 성능을 달성한다.

Gemini 모델이 학생의 물리 문제 풀이를 검증하는 예시로, 필기 인식, 문제 이해, LaTeX 생성 능력을 보여준다.
다양한 모달리티의 입력이 인터리빙된 형태로 처리되는 구조
총평: Gemini는 텍스트, 이미지, 오디오, 비디오를 통합적으로 처리하는 진정한 멀티모달 모델로서, MMLU 인간 전문가 수준 달성 및 30/32 벤치마크 최첨단 성능 기록을 통해 멀티모달 AI의 새로운 기준을 제시하며, 대규모 훈련 인프라 혁신(97% goodput)은 향후 초대형 모델 개발의 모범 사례가 될 것으로 기대된다.