Achievement
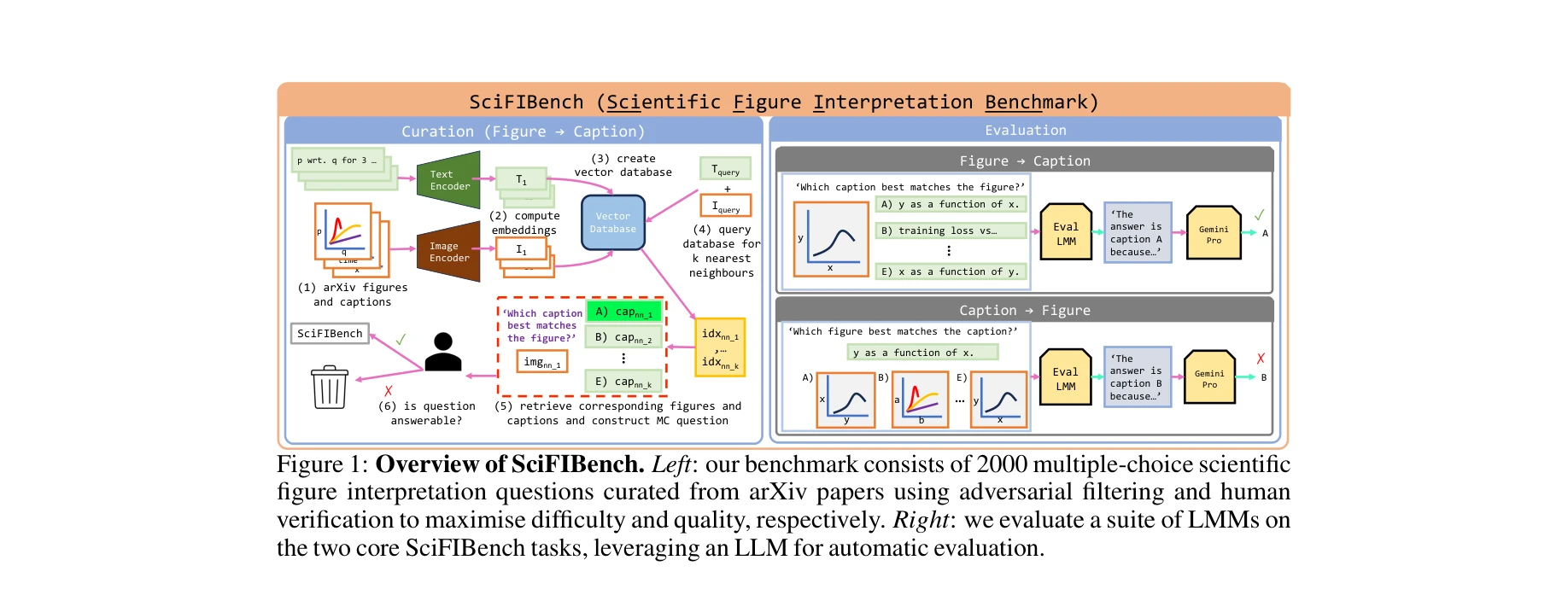
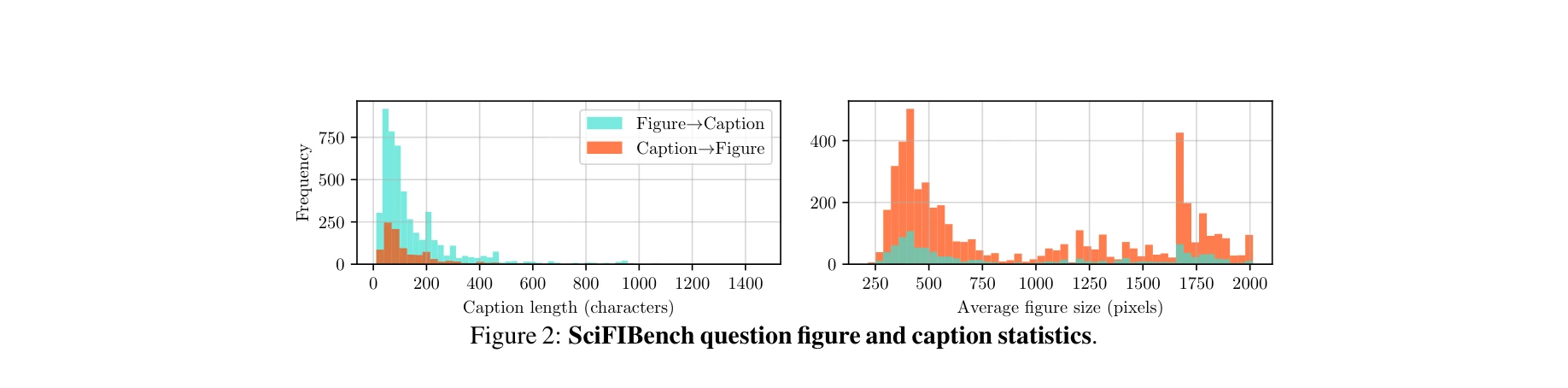
- 벤치마크 구축: arXiv에서 추출한 94k(CS) + 102k(일반) 그림-캡션 쌍으로부터 8개 범주의 2000개 고품질 문제 생성. 모든 문제에 대해 인간 검증 수행하여 응답 가능성 보장
- 포괄적 평가: GPT-4o, Gemini 1.5를 포함한 28개 LMM 평가로 현재 최고 성능 모델도 인간 기준선에 미치지 못함을 확인. 적대적 필터링이 문제 난이도 유의미하게 증가
- 충실성 분석: LLM(Gemini-Pro)을 활용한 자동 평가 방법 개발 및 모델의 추론 일관성(reasoning faithfulness) 프로빙 실시