저자: Leixin Zhang, Steffen Eger, Yinjie Cheng, Weihe Zhai, Jonas Belouadi, Christoph Leiter, Simone Paolo Ponzetto, Fahimeh Moafian, Zhixue Zhao | 날짜: 2024 | DOI: arXiv:2412.02368
Essence
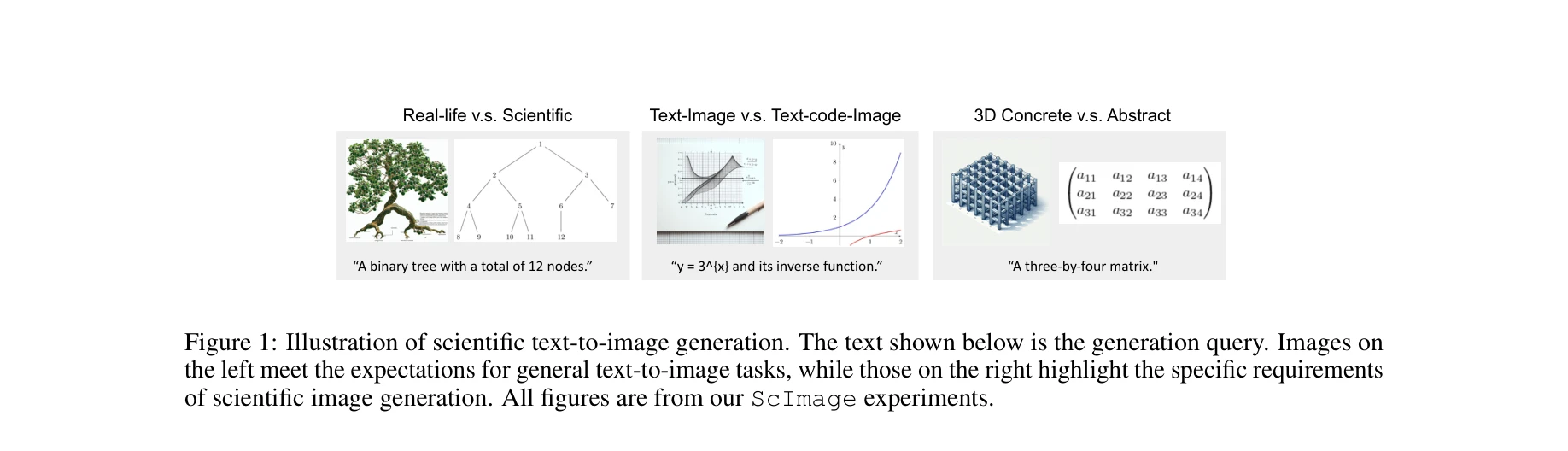
과학적 텍스트-이미지 생성의 예시. 일반 이미지(좌측)와 달리 과학 이미지는 정확한 공간 배치, 수치 표현, 객체 속성의 정확성을 요구한다.
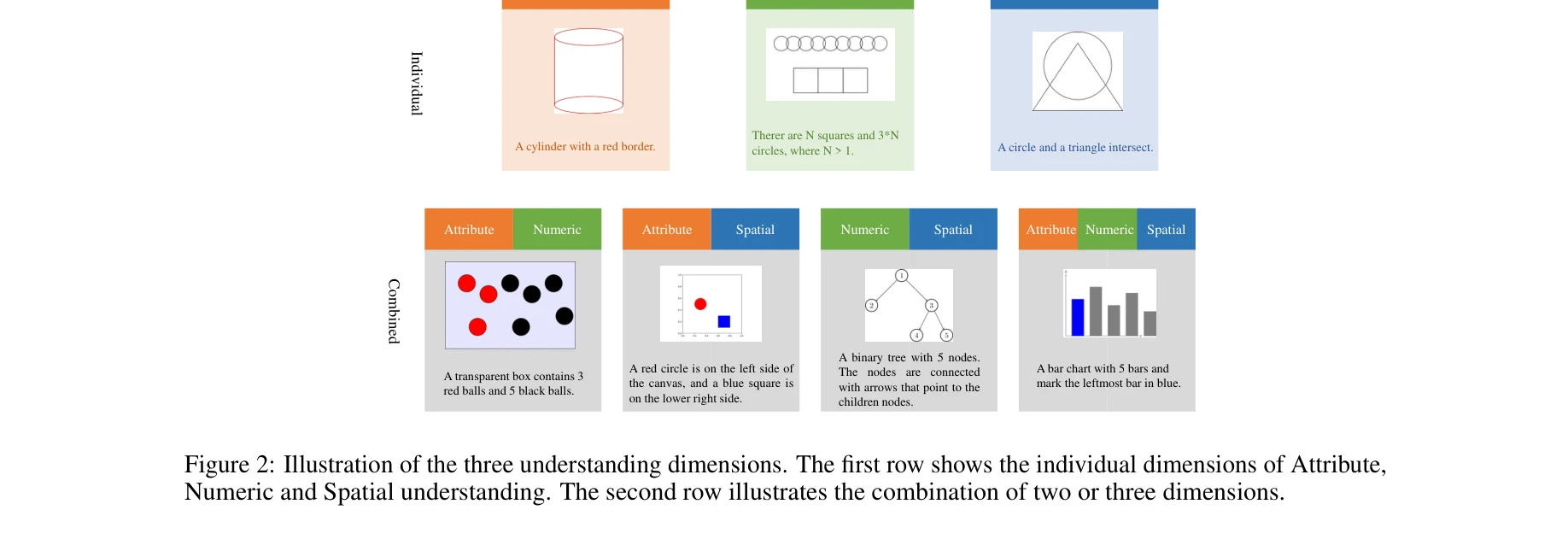
본 논문은 멀티모달 대규모 언어모델(LLM)의 과학적 이미지 생성 능력을 평가하기 위한 ScImage 벤치마크를 제시한다. 5가지 모델(GPT-4o, Llama, AutomaTikZ, DALL-E, StableDiffusion)을 공간(spatial), 수치(numeric), 속성(attribute) 이해 차원에서 평가한 결과, 모든 모델이 특히 복합 프롬프트에서 상당한 어려움을 겪는 것으로 나타났다.
Evaluation
총평: 본 논문은 과학 이미지 생성이라는 중요하면서도 미탐색된 영역에 처음으로 체계적이고 광범위한 벤치마크를 제시한 점에서 가치있는 기여이다. 특히 현재의 멀티모달 LLM들이 복잡한 과학 이미지 생성에서 여전히 상당한 어려움을 겪고 있음을 명확히 보여줌으로써, 향후 연구의 방향성을 제시한다는 점에서 의미있다. 다만 인간 평가 규모 확대와 더 광범위한 과학 도메인 포함을 통한 벤치마크 보강이 필요할 것으로 보인다.