저자: Yucheng Han, Chi Zhang, Xin Chen, Xu Yang, Zhibin Wang, Gang Yu, Bin Fu, Hanwang Zhang | 날짜: 2023 | DOI: 10.48550/ARXIV.2311.16483
Essence
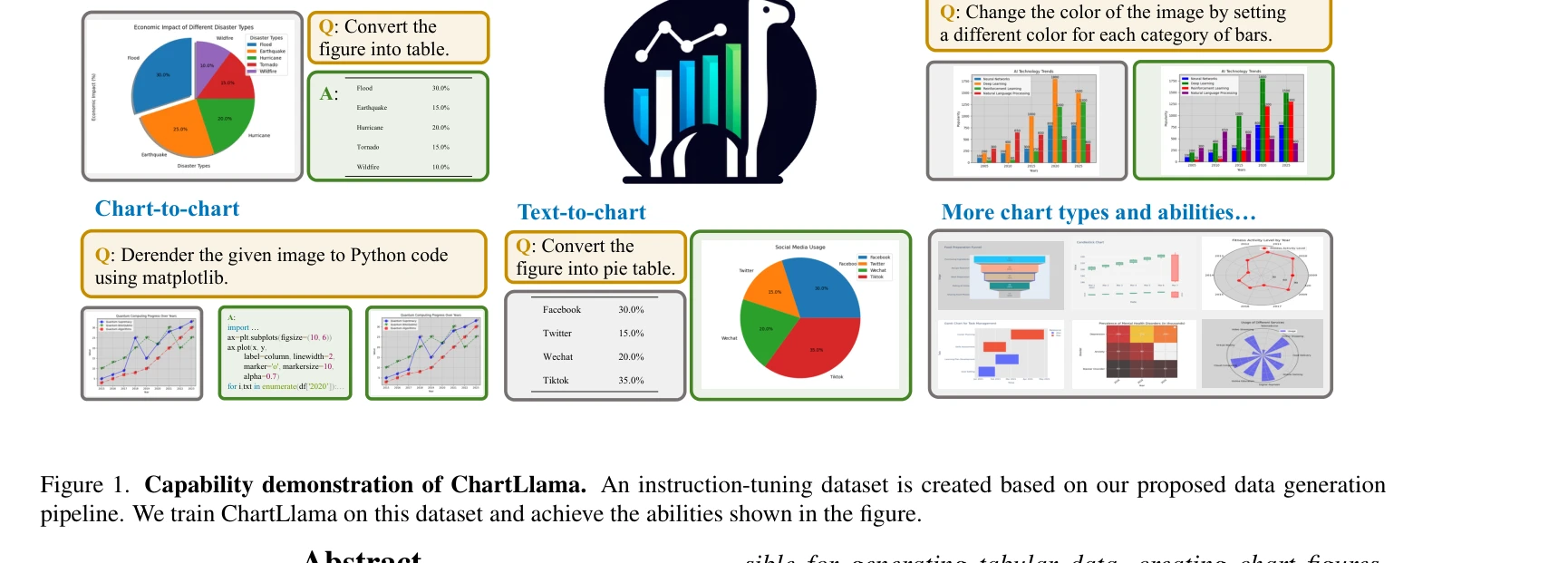
그림 1: ChartLlama의 다양한 능력 시연. 제안된 데이터 생성 파이프라인을 기반으로 한 instruction-tuning 데이터셋을 구축하고, 이를 통해 차트 이해 및 생성 능력 획득
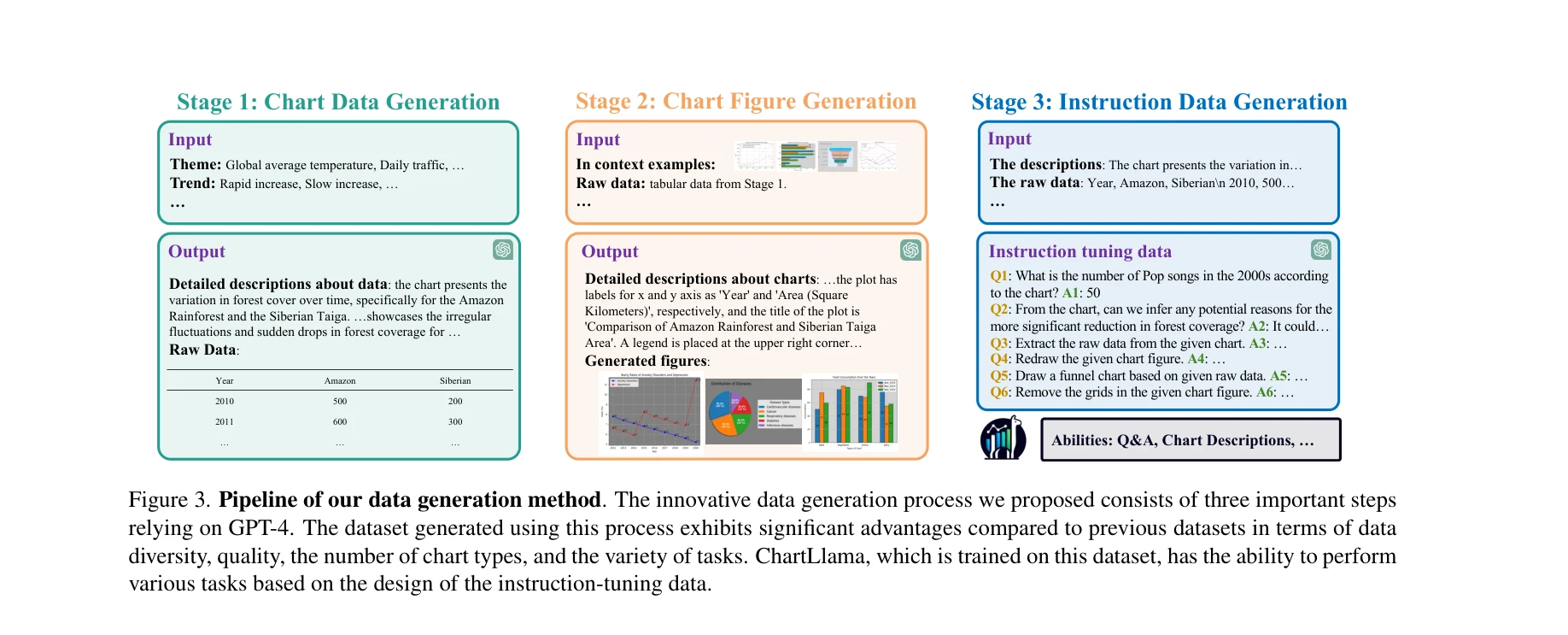
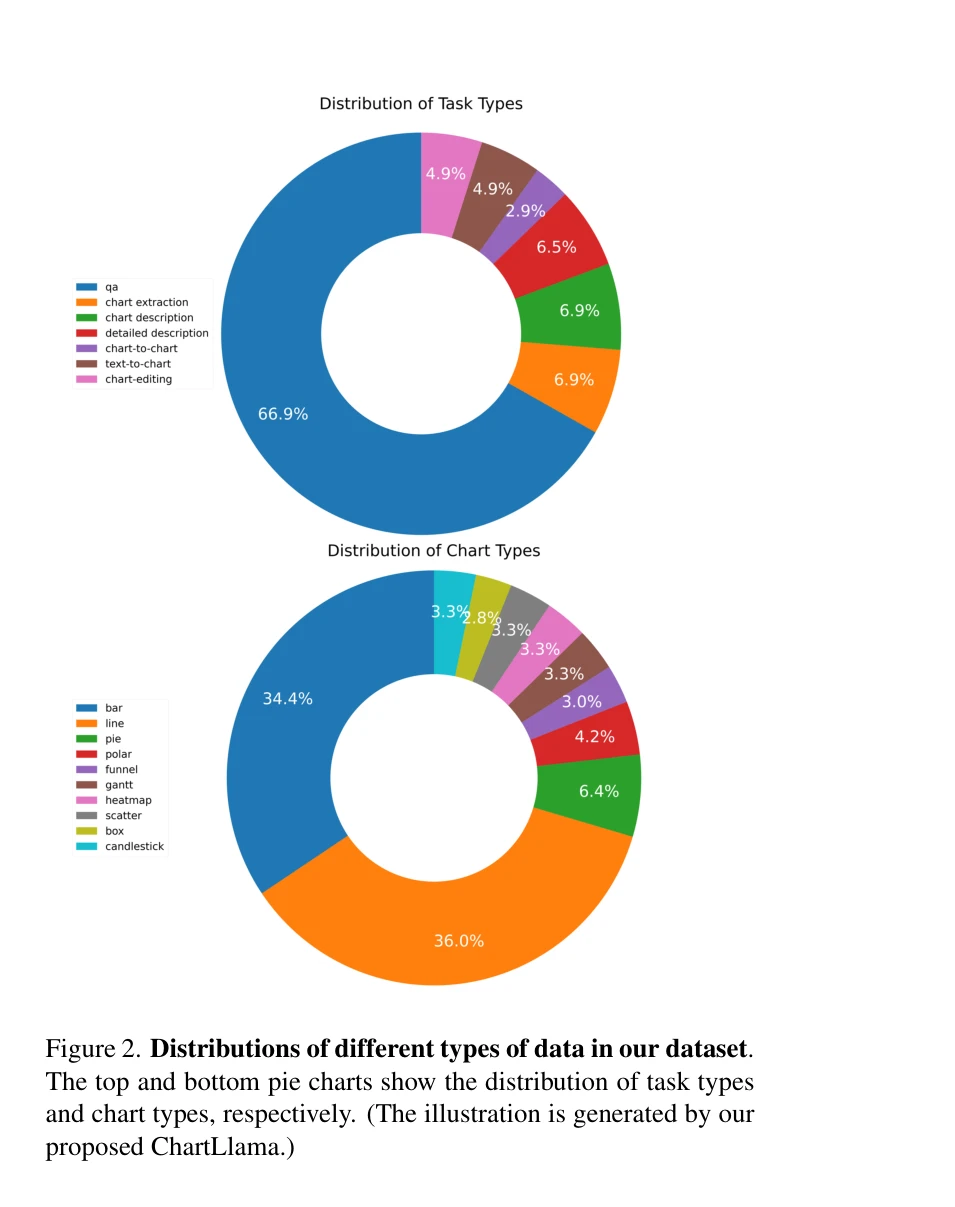
기존 멀티모달 대형언어모델(LLM)들이 일반적인 시각-언어 작업에서는 우수하나, 차트 해석 같은 특정 도메인 데이터 이해에는 크게 부족하다는 문제를 해결하기 위해, GPT-4 기반의 자동화된 3단계 데이터 생성 파이프라인을 제안하고, 이로부터 학습한 ChartLlama가 기존 벤치마크에서 최고 성능을 달성한 연구다.
Evaluation
Novelty: 4.5/5 Technical Soundness: 4.5/5 Significance: 4.5/5 Clarity: 4/5 Overall: 4.5/5
총평: 차트 이해에 특화된 멀티모달 LLM 개발이라는 명확한 목표 하에, GPT-4 기반의 체계적이고 유연한 데이터 생성 파이프라인을 제시하고, 이로부터 기존 벤치마크에서 우수한 성능을 달성한 의미 있는 연구다. 다만 합성 데이터 의존도, 실제 데이터 일반화, 규모 한계 등에 대한 추가 검증이 필요하며, 공개된 데이터셋과 모델이 차트 AI 연구 커뮤니티에 미칠 파급력은 클 것으로 예상된다.