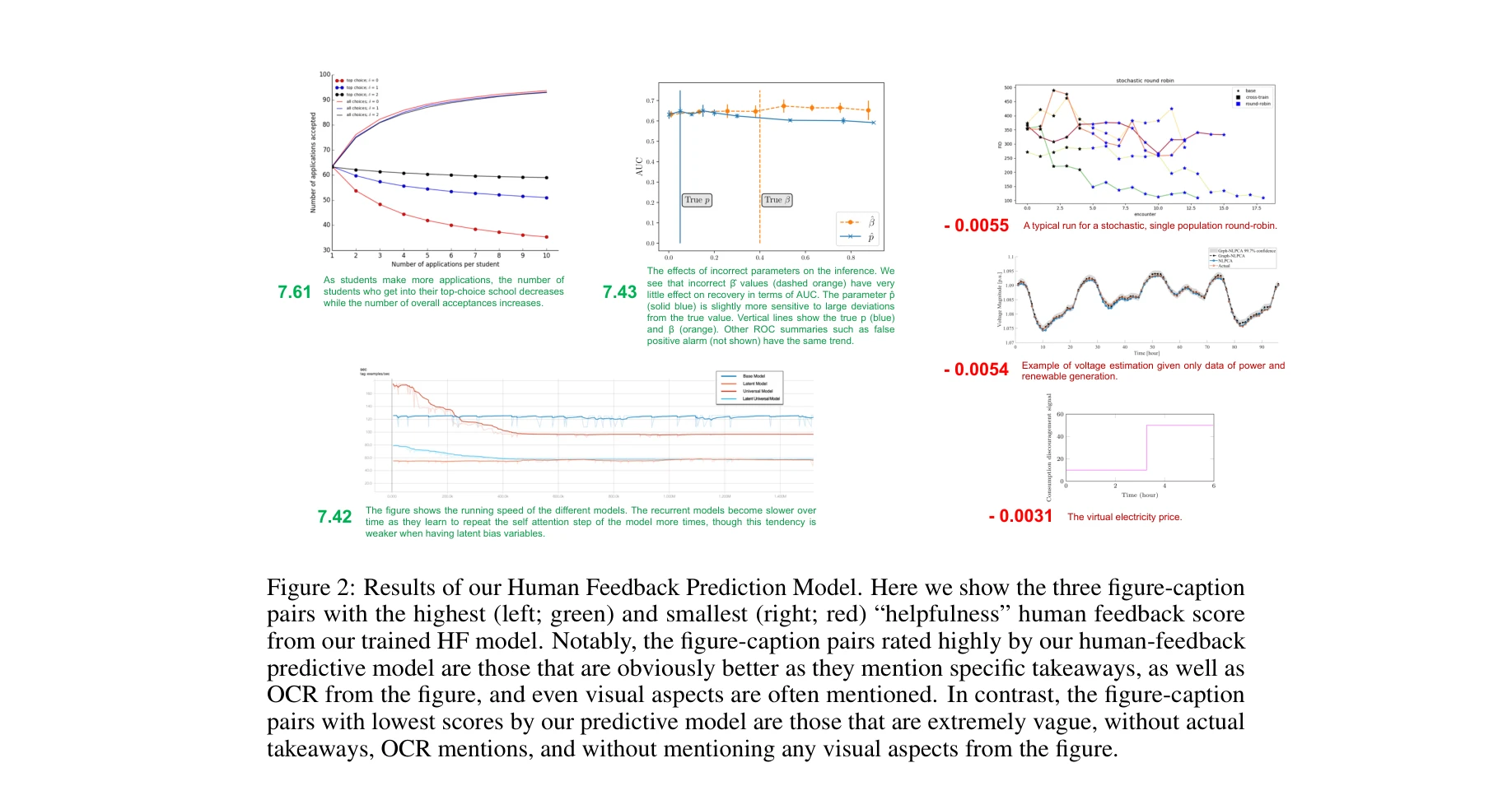
Achievement
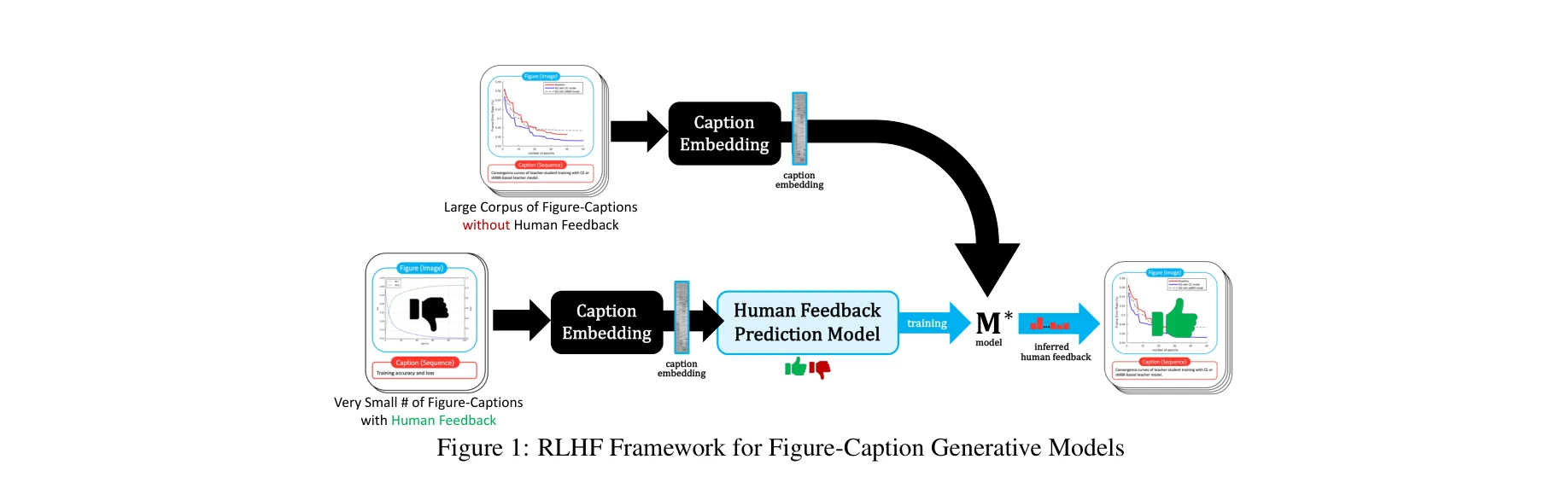
Figure 1: RLHF Framework for Figure-Caption Generative Models - 소수의 인간 피드백 그림-캡션 쌍에서 학습한 피드백 예측 모델을 통해 대규모 학습 코퍼스에 대한 피드백 추론
- 성능 향상: BLIP을 기반 모델로 사용할 때, ROUGE에서 35.7%, BLEU에서 16.9%, METEOR에서 9% 평균 성능 향상 달성
- 확장 가능한 피드백 생성: 작은 규모의 인간 주석 데이터(M ≪ N, 예: N=100,000일 때 M=100)로부터 대규모 학습 데이터셋에 대한 자동 피드백 점수 예측 가능
- 보정된 보상 모델: 훈련된 보상 모델이 잘 보정되어 있으며, 지면 진실 주석 통계가 추론된 주석 통계와 일치함을 실증적으로 입증
- 공개 벤치마크: 향후 RLHF 기술 개발을 위한 대규모 벤치마크 데이터셋 공개