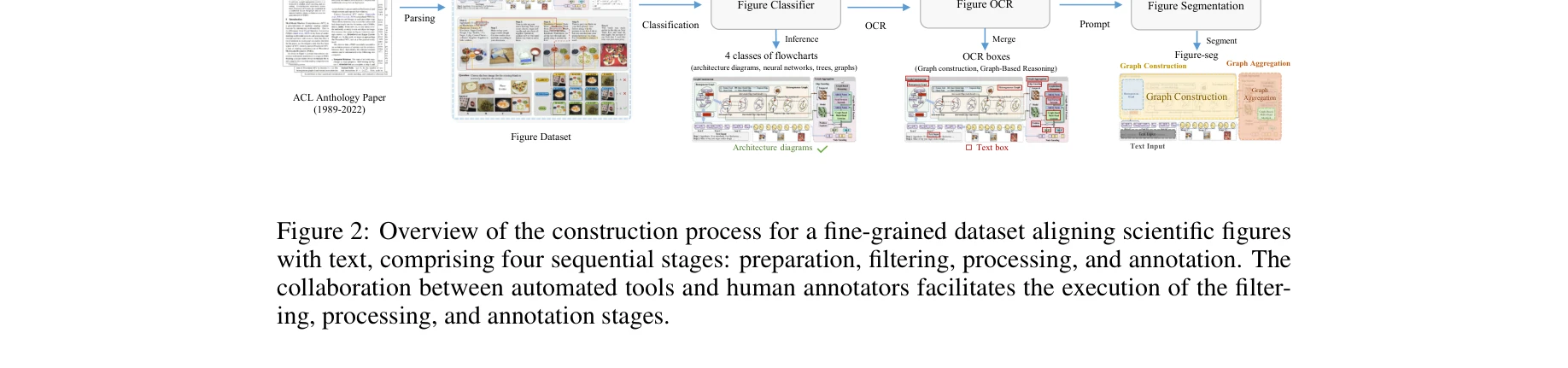
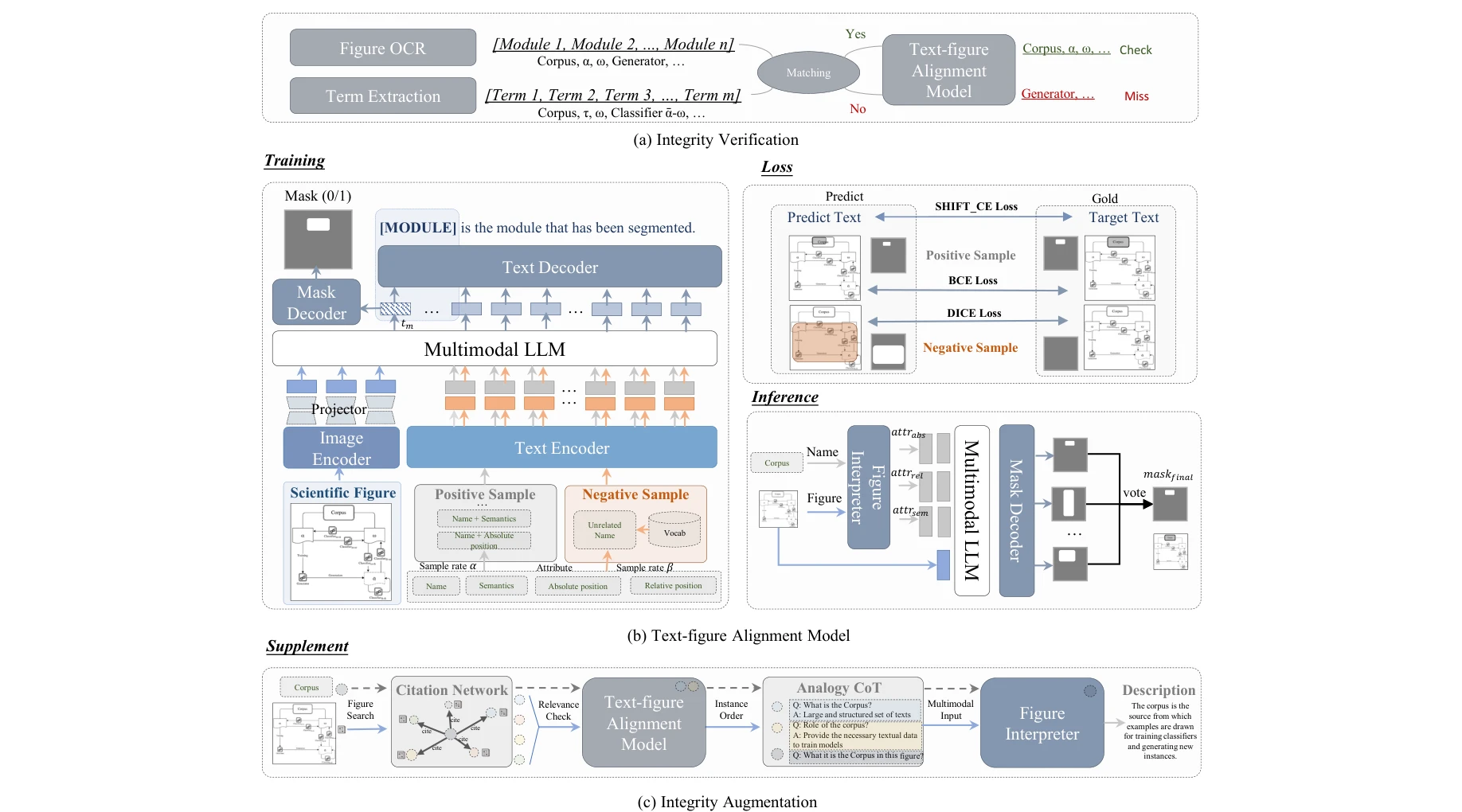
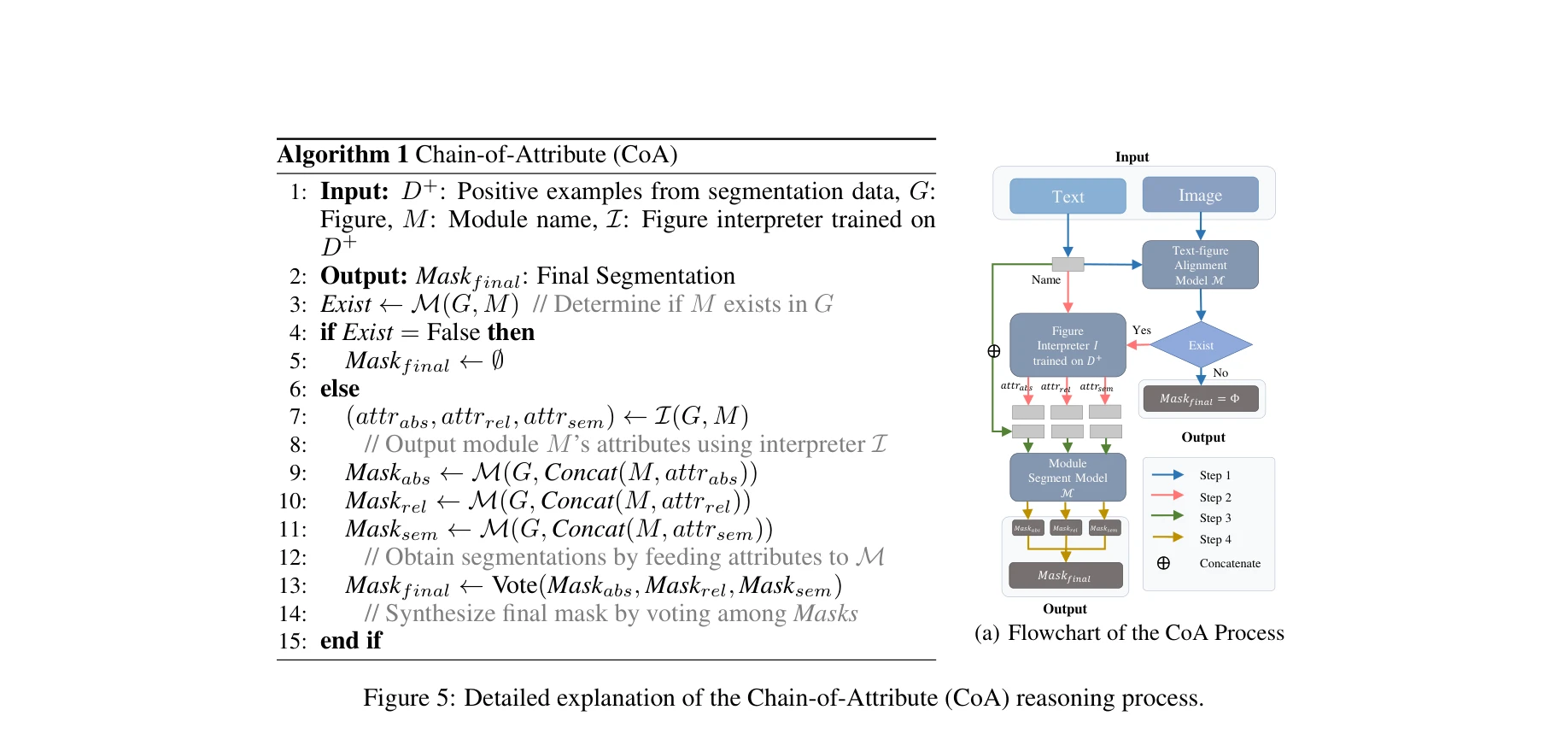
Essence
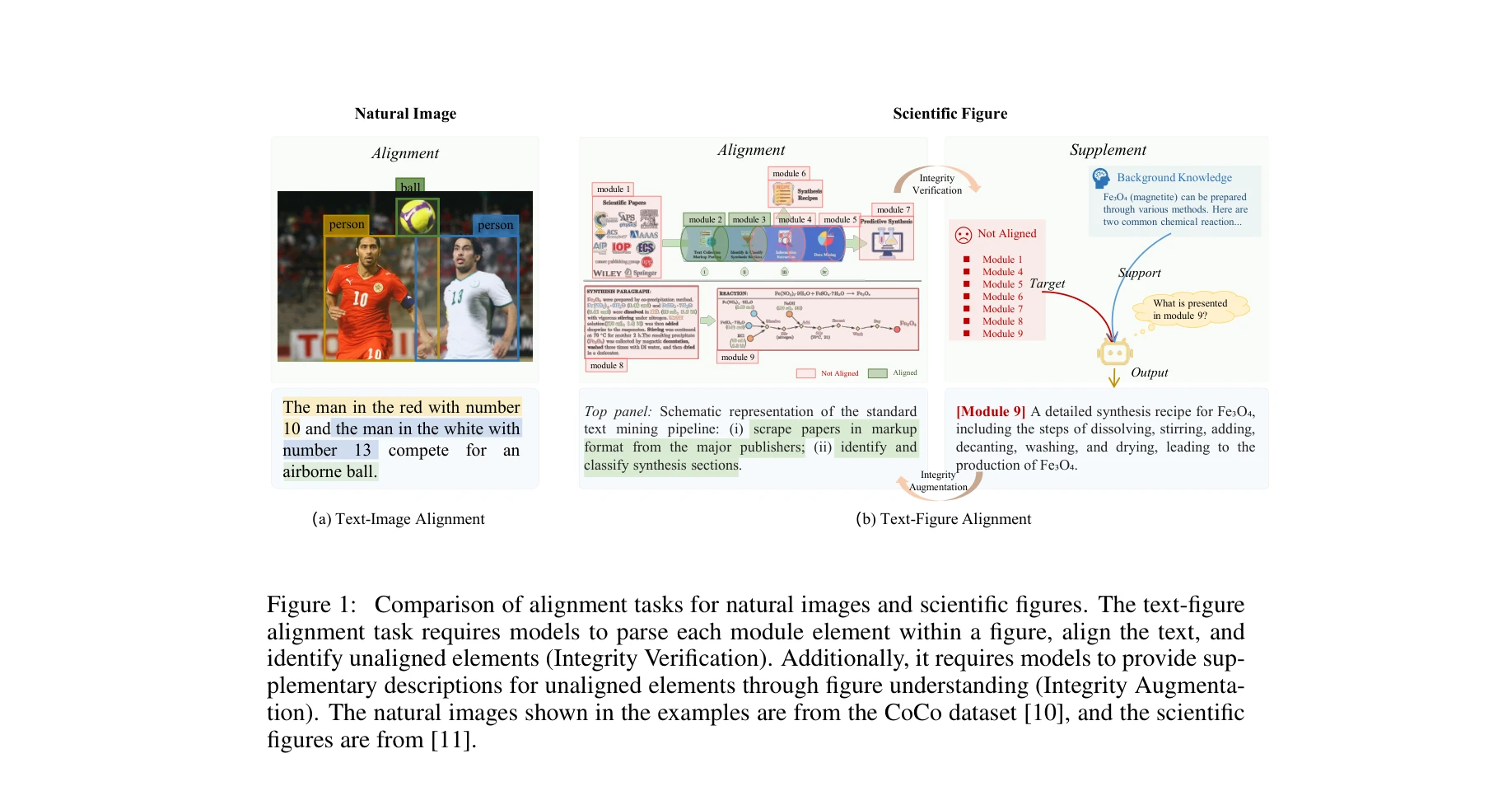
그림 1: 자연 이미지와 과학 논문 그림의 텍스트-이미지 정렬 작업 비교. 과학 그림의 텍스트-정렬 작업은 각 모듈 요소를 파싱하고, 텍스트를 정렬하며, 정렬되지 않은 요소를 식별하는 것을 요구함.
본 연구는 과학 논문의 그림에서 텍스트와 시각 요소의 세밀한 정렬을 위한 새로운 작업인 "Figure Integrity Verification"을 제안하며, 이를 지원하기 위해 Figure-seg 데이터셋과 Every Part Matters (EPM) 프레임워크를 개발했다. 이는 복잡한 도메인-특화 과학 그림의 이해와 검증을 크게 개선한다.