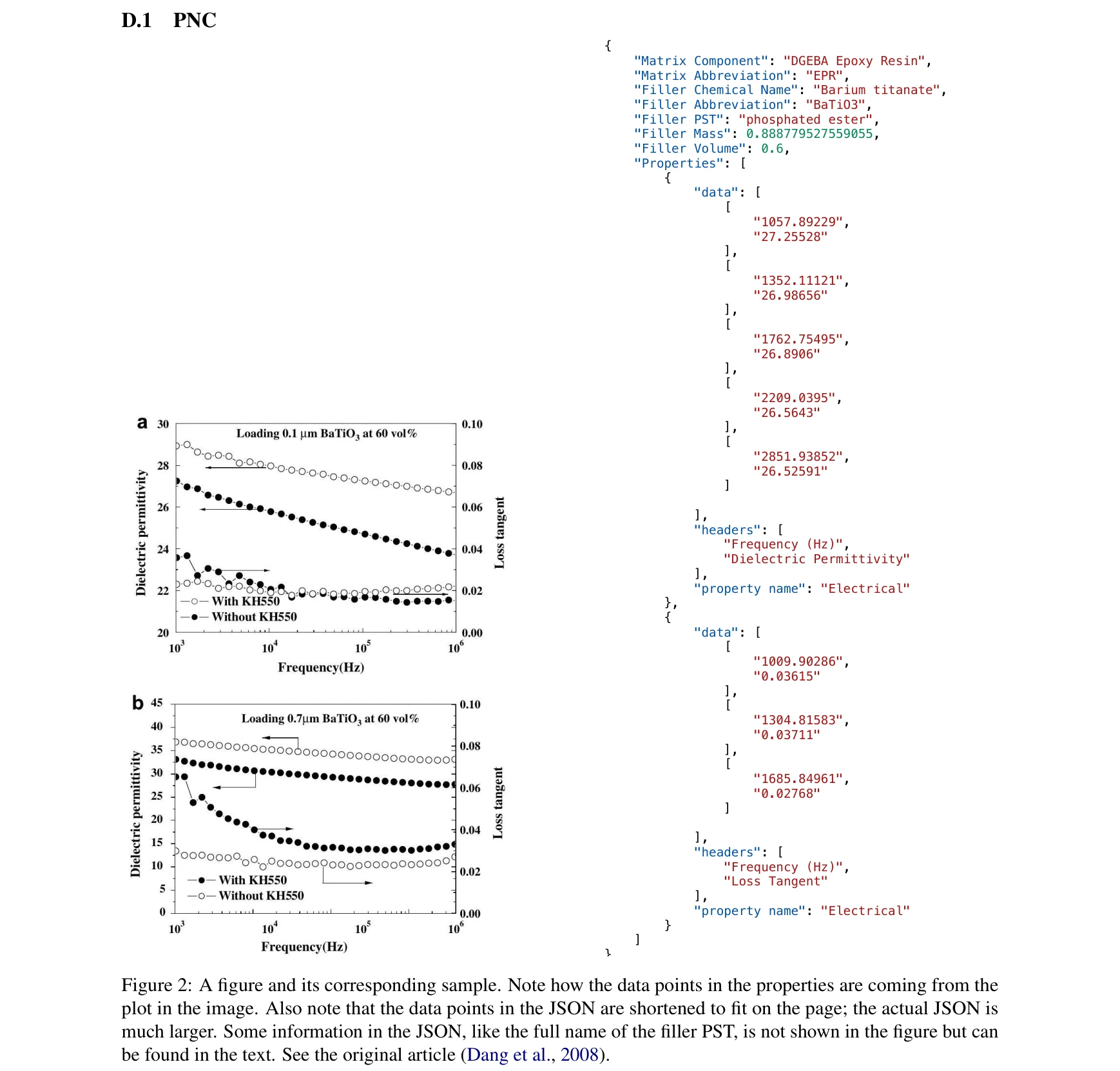
Essence
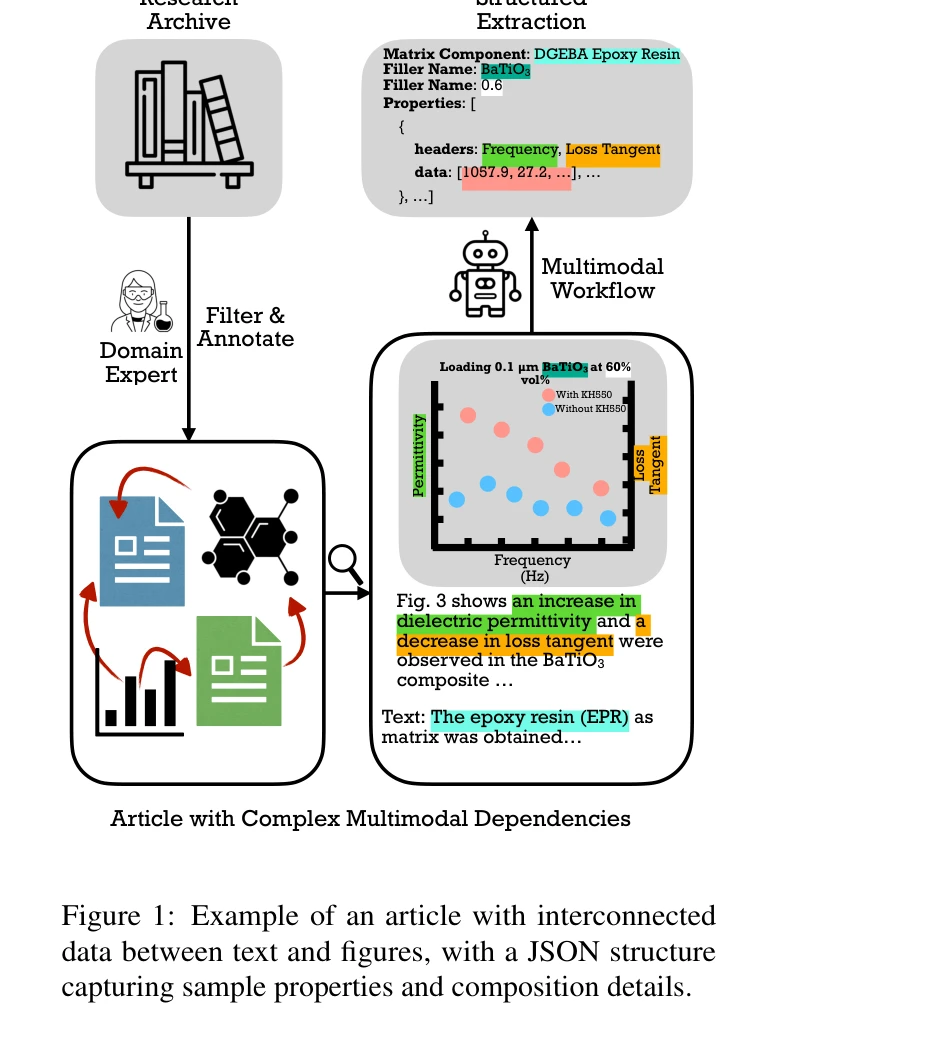
그림 1: 텍스트와 그림 간의 상호연결된 데이터를 포함하는 논문의 예시 및 샘플 특성과 구성 세부사항을 캡처하는 JSON 구조
재료과학 분야의 과학 논문에서 텍스트, 표, 그림에 분산된 구조화된 정보를 추출하는 멀티모달 정보 추출(Multimodal Information Extraction, MIE) 벤치마크를 제시한다. 324개의 전문가 주석 논문과 1,688개의 복잡한 구조화된 JSON 파일로 구성된 MATVIX 데이터셋을 소개하며, 비전-랭귀지 모델(Vision-Language Models, VLMs)의 성능을 평가한다.