Essence
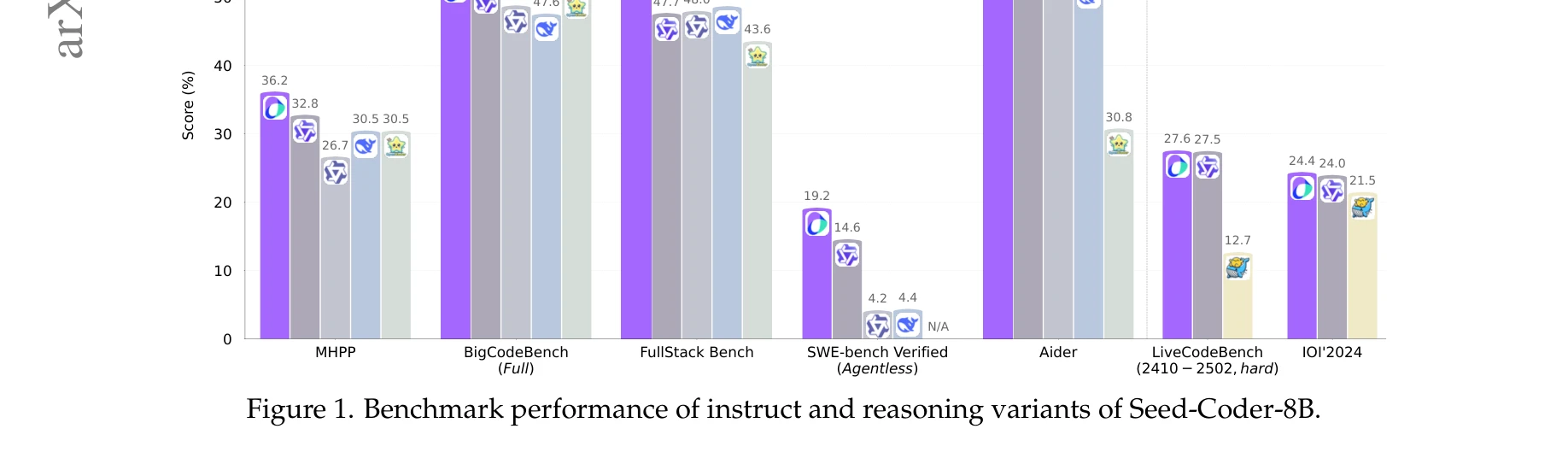
그림 1. Seed-Coder-8B 지시어(Instruct)와 추론(Reasoning) 변형의 벤치마크 성능 비교
본 논문은 코드 데이터 전처리 과정에서 인간의 수작업 필터링 규칙에 의존하지 않고, LLM 기반 자동 필터링을 활용하여 6조 토큰의 고품질 코드 사전학습 데이터를 구축한 Seed-Coder 모델 시리즈를 제시한다. 동일 규모의 오픈소스 모델을 능가하고 더 큰 모델과도 경쟁력 있는 성능을 달성한다.
저자: ByteDance Seed, Yuyu Zhang, Jing Su, Yifan Sun, Chenguang Xi, Xia Xiao, Zheng Shen, A. Q. Zhang, Kaibo Liu, Daoguang Zan, Tao Sun, J. Zhu, Shijie Xin, Dong Huang, Y. Bai, Lixin Dong, C. J. Li, Jianchong Chen, Hao Zhou, Yifan Huang | 날짜: 2025 | DOI: arXiv:2506.03524
그림 1. Seed-Coder-8B 지시어(Instruct)와 추론(Reasoning) 변형의 벤치마크 성능 비교
본 논문은 코드 데이터 전처리 과정에서 인간의 수작업 필터링 규칙에 의존하지 않고, LLM 기반 자동 필터링을 활용하여 6조 토큰의 고품질 코드 사전학습 데이터를 구축한 Seed-Coder 모델 시리즈를 제시한다. 동일 규모의 오픈소스 모델을 능가하고 더 큰 모델과도 경쟁력 있는 성능을 달성한다.
그림 2. 사전학습 데이터 처리 파이프라인. GitHub와 웹 아카이브에서 수집한 데이터를 네 가지 범주(파일 수준, 저장소 수준, 커밋, 웹 데이터)로 분류하고 LLM 기반 품질 필터와 최소한의 규칙을 적용
그림 3-5. LLM 기반 품질 평가 파이프라인 및 예시
총평: Seed-Coder는 코드 데이터 큐레이션의 근본적인 방식을 재정의하여, 인간의 수작업 규칙 대신