저자: Qiang Zhang, Keyang Ding, Tianwen Lyv, Xinda Wang, Qingyu Yin, Yiwen Zhang, Jing Yu, Yuhao Wang, Xiaotong Li, Zhuoyi Xiang, Kehua Feng, Xiang Zhuang, Zeyuan Wang, Ming Qin, Mengyao Zhang, Jinlu Zhang, Jiyu Cui, Tao Huang, Pengju Yan, Renjun Xu | 날짜: 2024-01-26
Essence

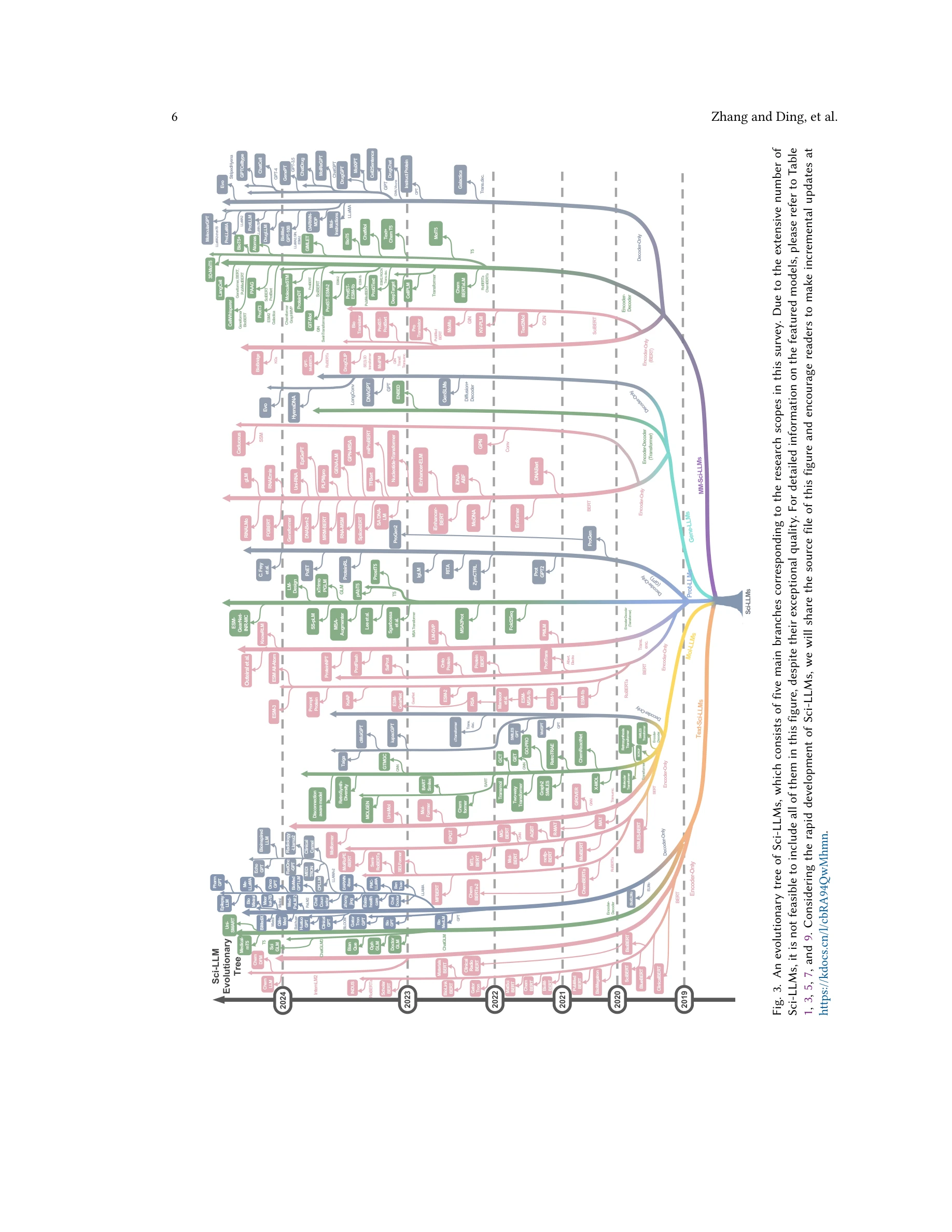
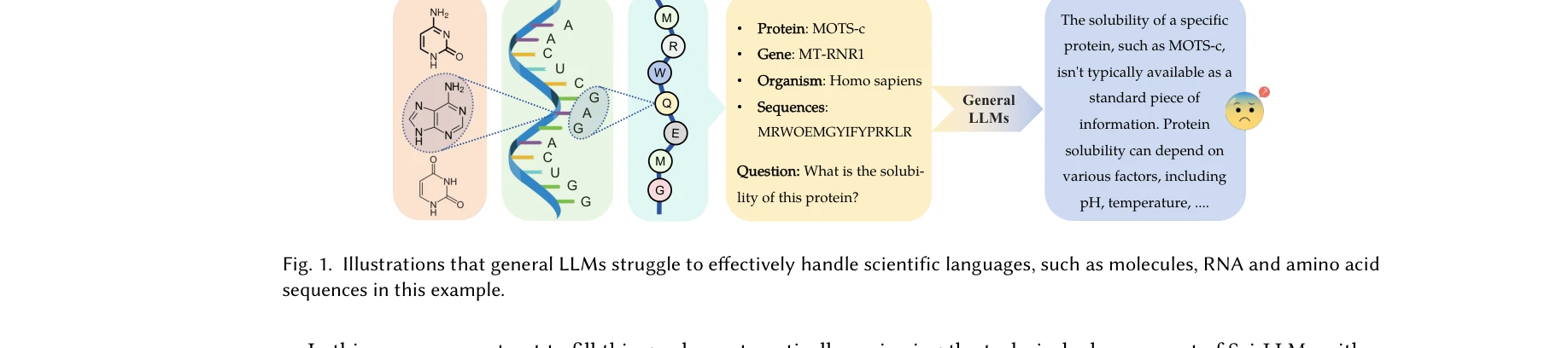
생물 및 화학 영역의 과학적 언어(분자, 단백질, 게놈, 텍스트) 및 멀티모달 조합을 포괄하는 과학 LLM의 연구 범위
본 논문은 생물학 및 화학 분야의 특화된 과학 언어를 처리하도록 설계된 대규모 언어 모델(과학 LLM)에 대한 최초의 포괄적 조사연구다. 텍스트, 분자(SMILES, SELFIES), 단백질(아미노산 서열), 게놈(DNA 서열) 및 이들의 멀티모달 조합을 다루며, 모델 아키텍처, 학습 데이터셋, 평가 방법론을 상세히 분석한다.
Evaluation
Novelty: 4.5/5 Technical Soundness: 4/5 Significance: 4.5/5 Clarity: 4.5/5 Overall: 4.4/5
총평: 본 논문은 빠르게 성장하는 과학 LLM 분야의 첫 포괄적 리뷰로, 분자·단백질·게놈·멀티모달 영역을 통합 분석한 점에서 기여도가 크다. 다만 이론적 혁신보다는 기존 모델들의 체계적 종합에 가까우며, 도메인 간 비교 분석 및 실제 과학적 임팩트 검증은 향후 과제로 남아있다.
같이 보면 좋은 논문
기반 연구
생의학 도메인 특화 BERT의 선구적 연구로서 과학 분야 대형언어모델 발전의 기초가 되었다
기반 연구
과학 분야 언어모델의 전반적인 발전 과정에서 SciBERT의 위치와 기여를 이해할 수 있다
기반 연구
과학 분야 특화 언어모델 발전에서 DeepSeek-V3의 기술적 기여를 이론적 맥락에서 이해할 수 있다
기반 연구
자연언어처리에서 LLM의 기본적 이해가 생물학/화학 특화 과학 LLM 개발의 기반이 된다.
기반 연구
생물학과 화학 분야 과학 LLM 서베이가 응용 사례 분석의 이론적 기반을 제공함
기반 연구
생물학과 화학 분야 과학 대규모 언어모델 서베이가 LLM4SR의 도메인별 적용 부분의 이론적 기반이다.
기반 연구
생성형 AI와 파운데이션 모델의 전반적 이해가 과학 특화 LLM 개발의 기반이 된다.
다른 접근
생물의학 분야에서 BERT 기반 접근법과 대규모 언어모델 기반 접근법의 비교 관점을 제공한다.
다른 접근
과학 분야 대규모 언어모델에서 수학/물리학과 생물/화학이라는 서로 다른 도메인 관점입니다.
다른 접근
과학 LLM 서베이에서 004는 포괄적 조사, 720은 생물학과 화학 분야에 특화된 접근법을 사용한다
후속 연구
일반 LLM 서베이에서 과학 분야 특화 LLM으로 확장된 종합 연구
후속 연구
27억 매개변수 바이오메디컬 모델을 생물학 및 화학 분야의 더 대규모 과학 언어모델로 확장한 발전된 연구임
후속 연구
일반적인 NLP 분야 LLM 조사를 생물학/화학 특화 도메인으로 확장한 전문화된 연구이다.
후속 연구
생물학과 화학 분야의 과학적 대규모 언어모델 조사가 본 논문의 물리학 중심 접근을 다른 과학 분야로 확장한 사례이다.
응용 사례
생성형 AI와 파운데이션 모델의 전반적 발전이 생물학/화학 특화 과학 LLM 개발에 직접 적용된다.