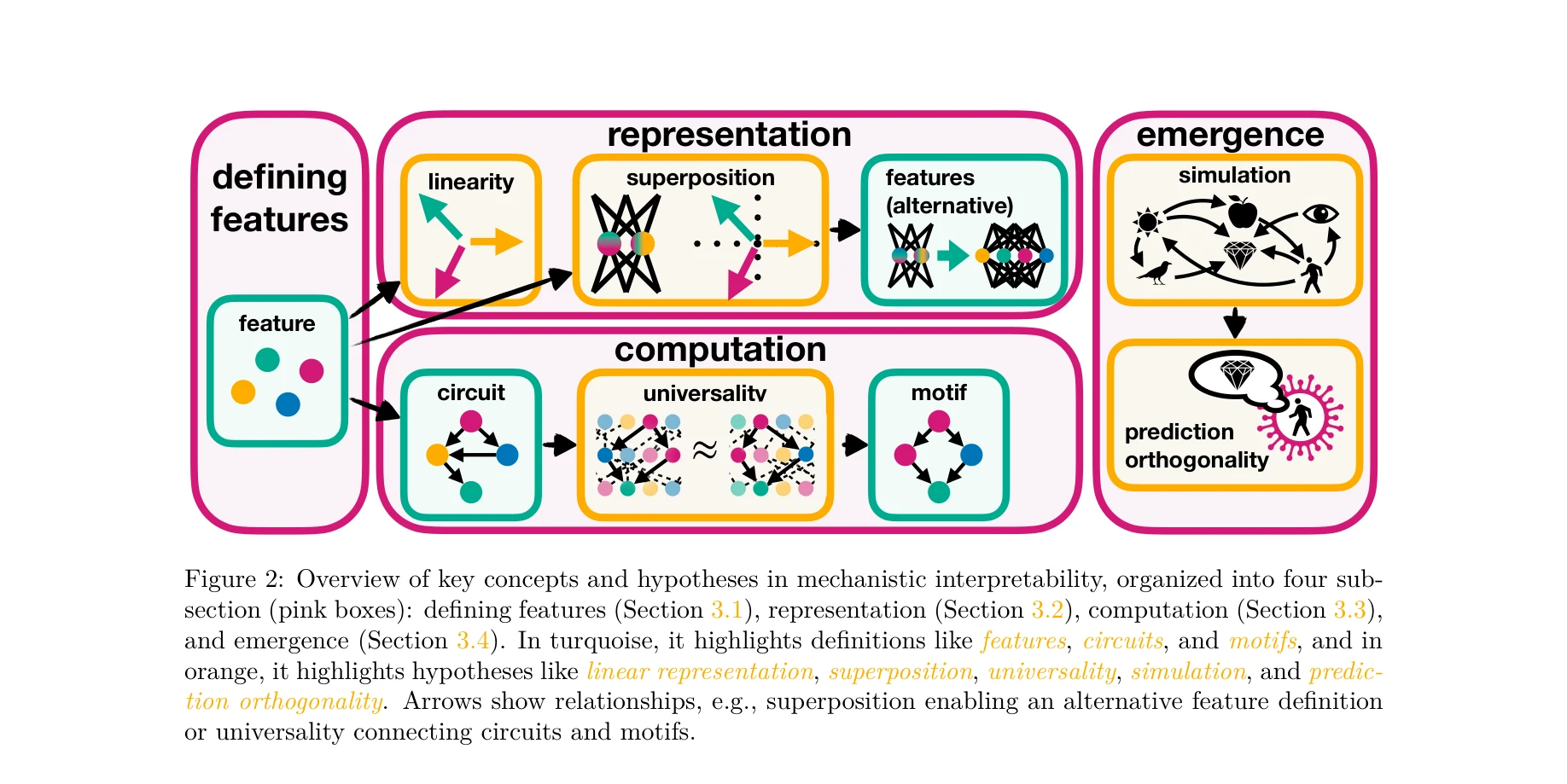
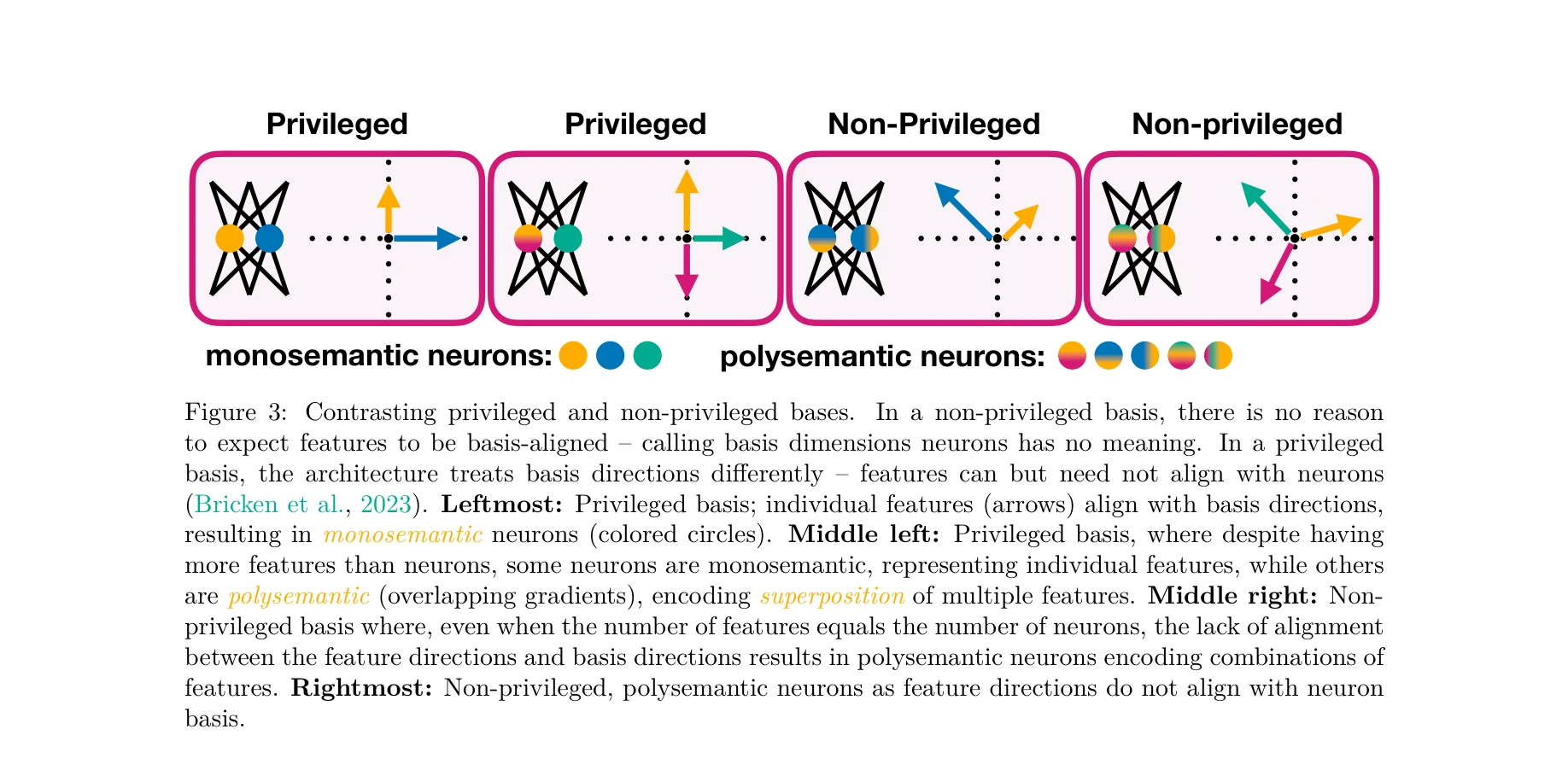
Essence
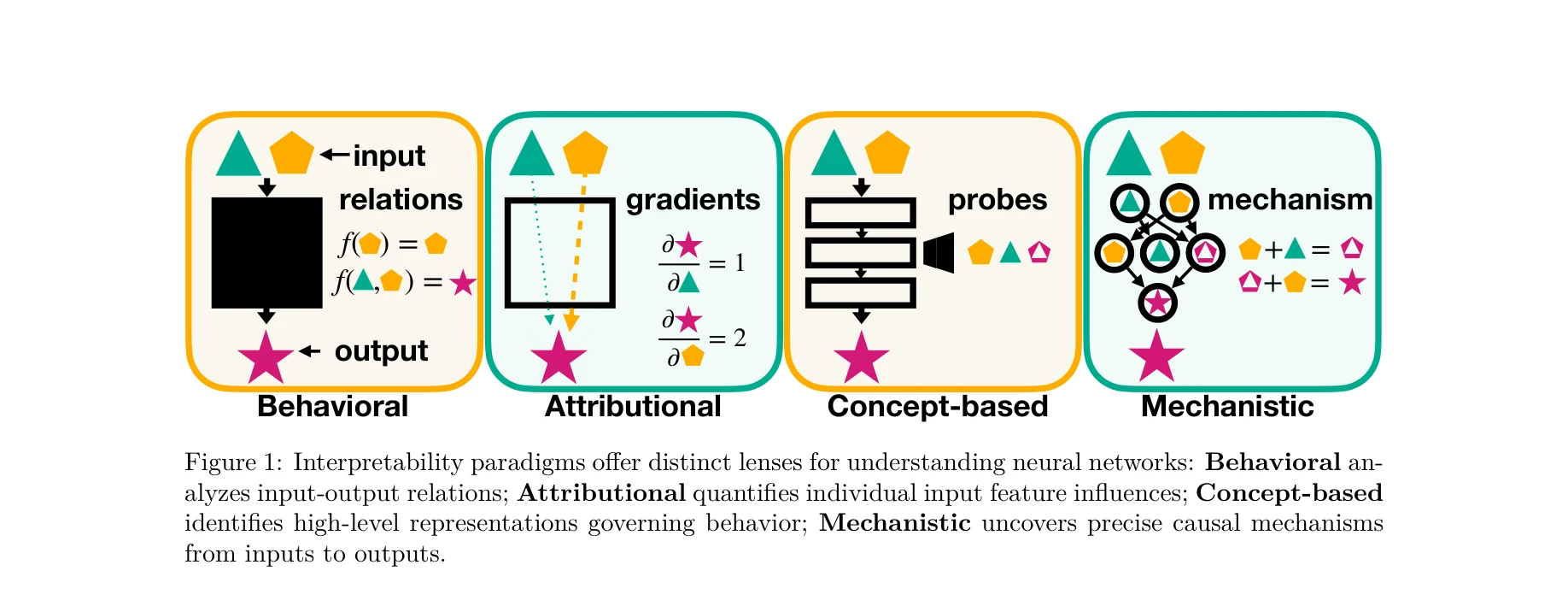
해석가능성 패러다임: 행동적(Behavioral), 귀속적(Attributional), 개념기반(Concept-based), 기계론적(Mechanistic) 접근의 비교
본 논문은 신경망의 내부 작동 메커니즘을 인간이 이해할 수 있는 알고리즘으로 역공학(reverse engineering)하는 기계론적 해석가능성(mechanistic interpretability)의 종합적 리뷰를 제공한다. AI 안전성 확보를 위해 신경망의 세밀한 인과관계 이해가 필수적임을 강조한다.