Essence
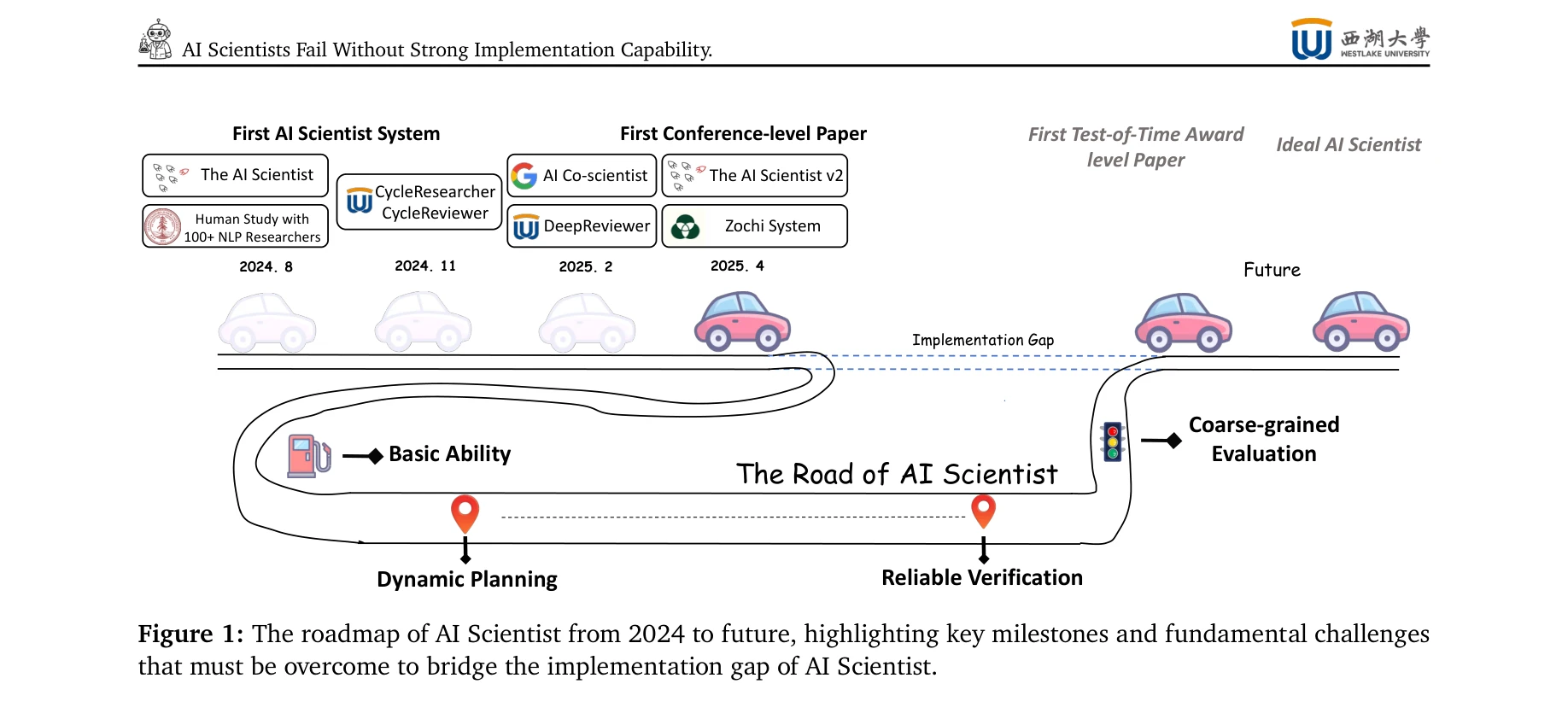
AI Scientist의 발전 로드맵(2024~미래)에서 구현 격차(Implementation Gap) 해결의 중요성을 강조
대규모 언어모델(LLM) 기반 AI Scientist는 우수한 아이디어 생성 능력을 보유했으나, 실제 과학적 검증과 실험 구현 능력이 심각하게 부족하여 진정한 자동화 과학 연구 달성에 실패하고 있다는 입장 논문이다.
저자: Min Zhu, Qiujie Xie, Yixuan Weng, Jian Wu, Zhen Lin, Linyi Yang, Yue Zhang | 날짜: 2025 | DOI: 미제공
AI Scientist의 발전 로드맵(2024~미래)에서 구현 격차(Implementation Gap) 해결의 중요성을 강조
대규모 언어모델(LLM) 기반 AI Scientist는 우수한 아이디어 생성 능력을 보유했으나, 실제 과학적 검증과 실험 구현 능력이 심각하게 부족하여 진정한 자동화 과학 연구 달성에 실패하고 있다는 입장 논문이다.
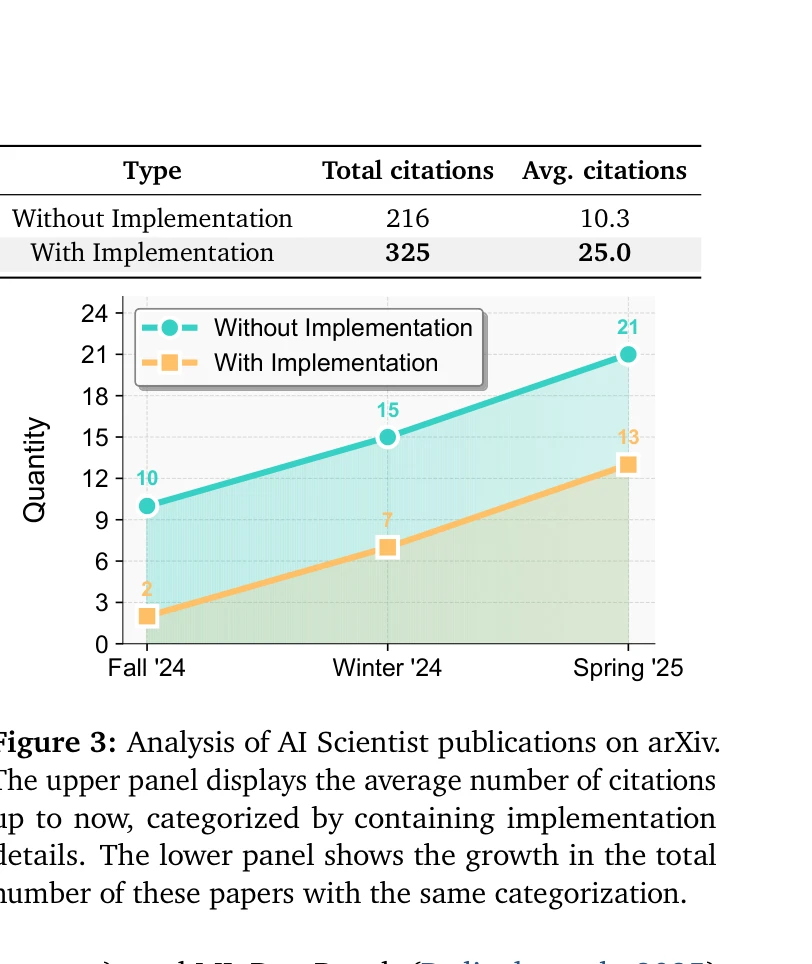
arXiv AI Scientist 논문 분석: 구현 세부사항 포함 논문의 인용도가 2.4배 높음(25.0 vs 10.3)
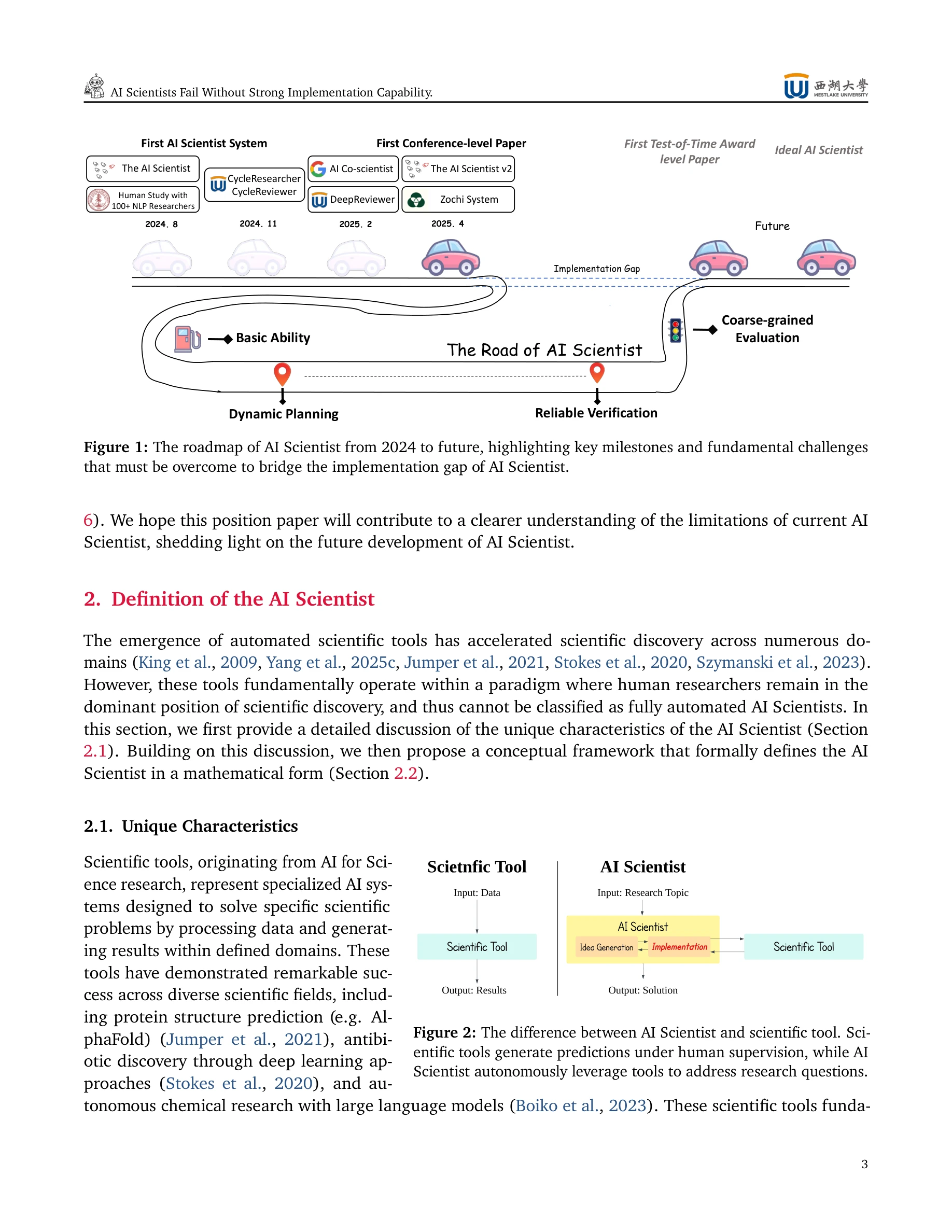
과학 도구 vs AI Scientist: 과학 도구는 인간 감독 하에 데이터→결과 처리, AI Scientist는 자율적으로 연구 질문→솔루션 도출
방법론 및 평가 기법:
총평: 이 논문은 AI Scientist의 현주소를 객관적 데이터로 진단한 중요한 비판적 분석 연구로, 아이디어 생성의 성공이 실행의 실패로 귀결되는 근본 문제를 명확히 드러낸다. 커뮤니티가 과장된 낙관론을 벗고 기술적 현실을 직시하게 하는 값진 기여이나, 해결책 제시 강화로 더욱 건설적 영향력을 발휘할 수 있을 것으로 기대된다.