Essence

대규모 언어모델이 연구논문을 읽고 미래 연구 아이디어를 제안하는 과정
본 논문은 대규모 언어모델(LLM)이 과학 논문으로부터 새로운 미래 연구 아이디어를 생성할 수 있는지를 체계적으로 평가한다. 이를 위해 자동 평가 메트릭(IAScore, Idea Distinctness Index)을 제안하고 인간 평가를 병행하여 LLM의 아이디어 생성 능력과 한계를 분석한다.
저자: Sandeep Kumar, Tirthankar Ghosal, Vinayak Goyal, Asif Ekbal | 날짜: 2024 | DOI: N/A
대규모 언어모델이 연구논문을 읽고 미래 연구 아이디어를 제안하는 과정
본 논문은 대규모 언어모델(LLM)이 과학 논문으로부터 새로운 미래 연구 아이디어를 생성할 수 있는지를 체계적으로 평가한다. 이를 위해 자동 평가 메트릭(IAScore, Idea Distinctness Index)을 제안하고 인간 평가를 병행하여 LLM의 아이디어 생성 능력과 한계를 분석한다.
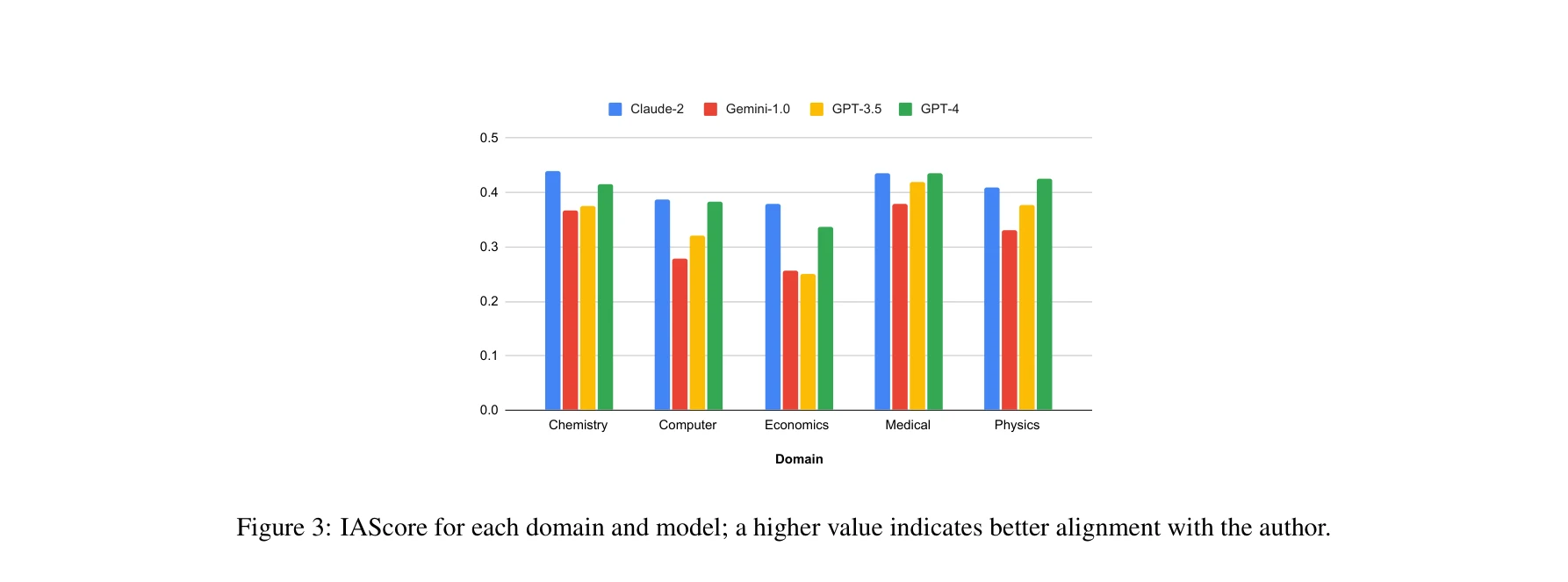
도메인별 및 모델별 IAScore 비교; 높은 값은 저자의 아이디어와 더 나은 정렬을 의미
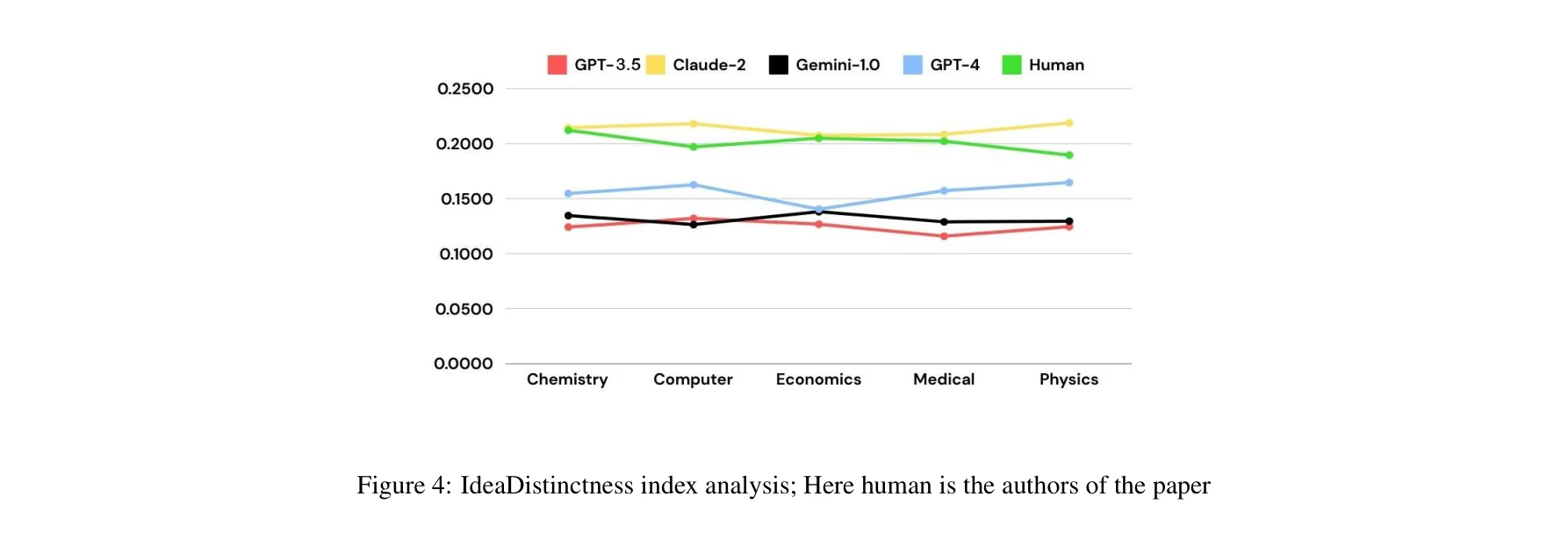
아이디어 다양성 지수 분석; 인간은 논문의 저자

도메인별 논문 내 평균 단어 수 비교 (미래연구 섹션 포함/제외)
총평: 본 논문은 LLM의 아이디어 생성 능력을 체계적으로 평가하기 위한 첫 시도로 의의가 있으나, 제안된 IAScore의 근본적 한계(저자 아이디어와의 정렬도만 측정)로 인해 완전한 평가 프레임워크로 보기 어렵다. 다양한 도메인에 걸친 광범위한 인간 평가와 더불어 진정한 참신성을 감지할 수 있는 개선된 메트릭 개발이 필요하다.