Essence
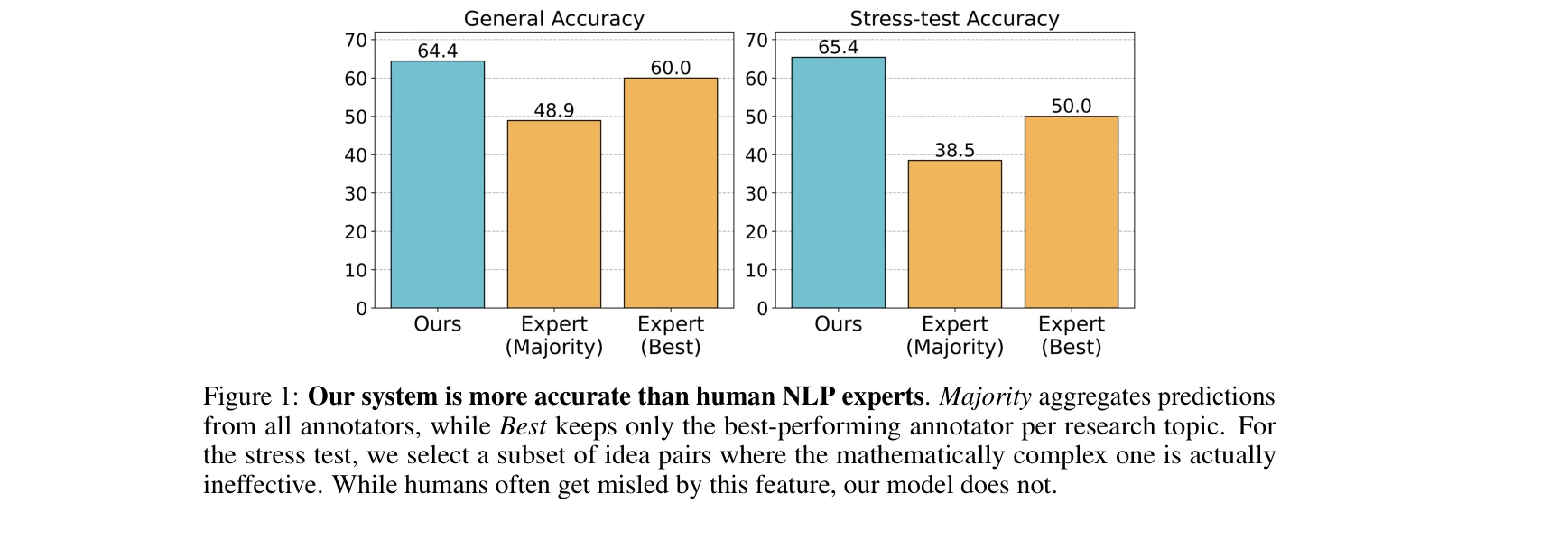
인간 NLP 전문가 대비 시스템의 예측 정확도 비교
본 논문은 AI 연구 아이디어의 실험 성공 가능성을 사전에 예측하는 최초의 벤치마크와 언어 모델 기반 시스템을 제시한다. 두 개의 경쟁하는 연구 아이디어 중 어느 것이 벤치마크에서 더 좋은 성능을 보일지 예측하는 과제에서, 미세조정된 GPT-4.1과 검색 에이전트를 결합한 시스템이 인간 전문가를 큰 폭으로 능가함을 보여준다.
저자: Jiaxin Wen, Chenglei Si, Chen Yueh-Han, He He, Shi Feng | 날짜: 2025 | DOI: N/A
인간 NLP 전문가 대비 시스템의 예측 정확도 비교
본 논문은 AI 연구 아이디어의 실험 성공 가능성을 사전에 예측하는 최초의 벤치마크와 언어 모델 기반 시스템을 제시한다. 두 개의 경쟁하는 연구 아이디어 중 어느 것이 벤치마크에서 더 좋은 성능을 보일지 예측하는 과제에서, 미세조정된 GPT-4.1과 검색 에이전트를 결합한 시스템이 인간 전문가를 큰 폭으로 능가함을 보여준다.
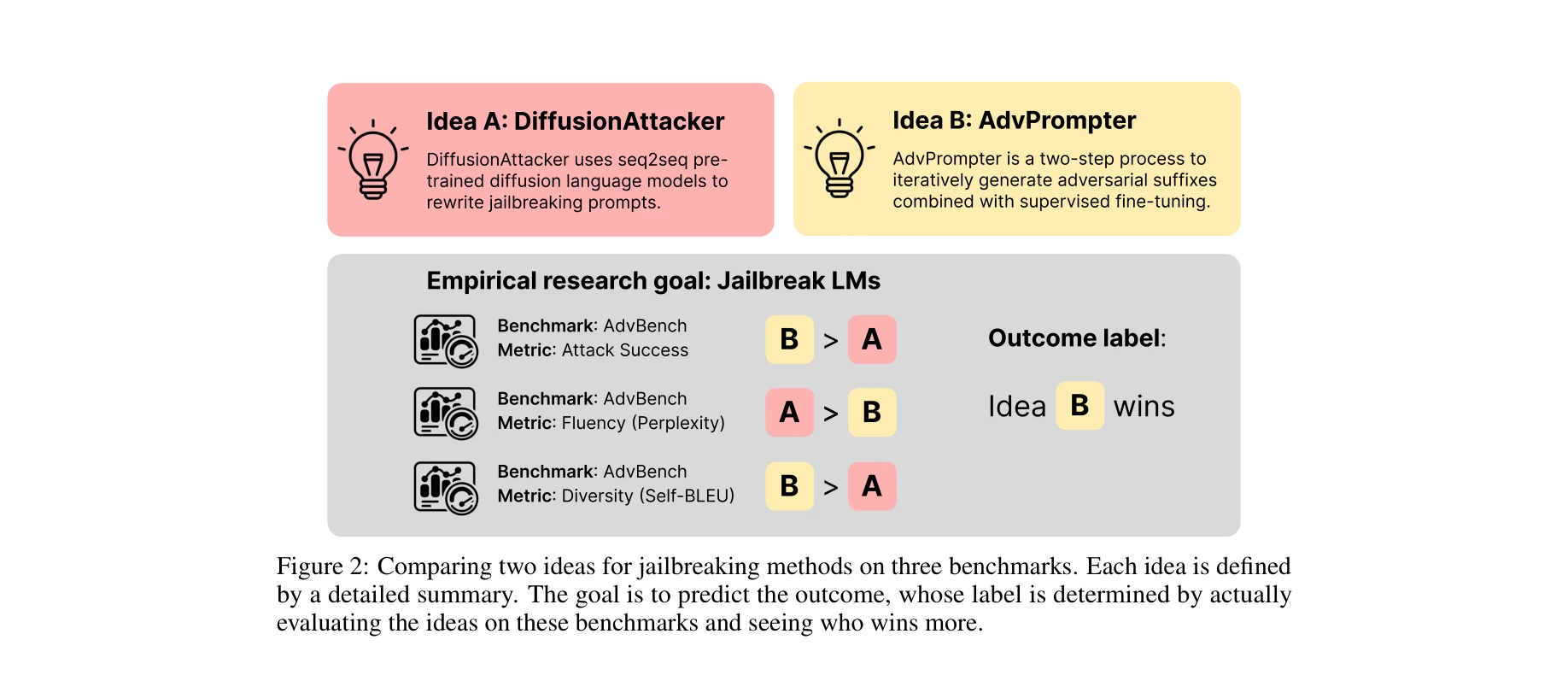
두 개의 jailbreaking 방법을 여러 벤치마크에서 비교하는 예시

자동 평가 결과
벤치마크 구성 파이프라인:
검색 강화 시스템:
미세조정 및 평가:
총평: 본 논문은 실증적 AI 연구 성과 예측이라는 중요하면서도 미개척된 문제에 대해 엄격한 벤치마크 구축과 강력한 시스템 개발을 제시한 우수한 연구이다. 특히 인간 전문가를 능가하는 성능과 미발표 아이디어에 대한 일반화 가능성은 주목할 만하나, 도메인 간 성능 격차 분석과 왜 최신 대형 언어 모델들이 이 과제에서 실패하는지에 대한 심층적 이해가 향상되면 영향력이 더욱 커질 수 있다.