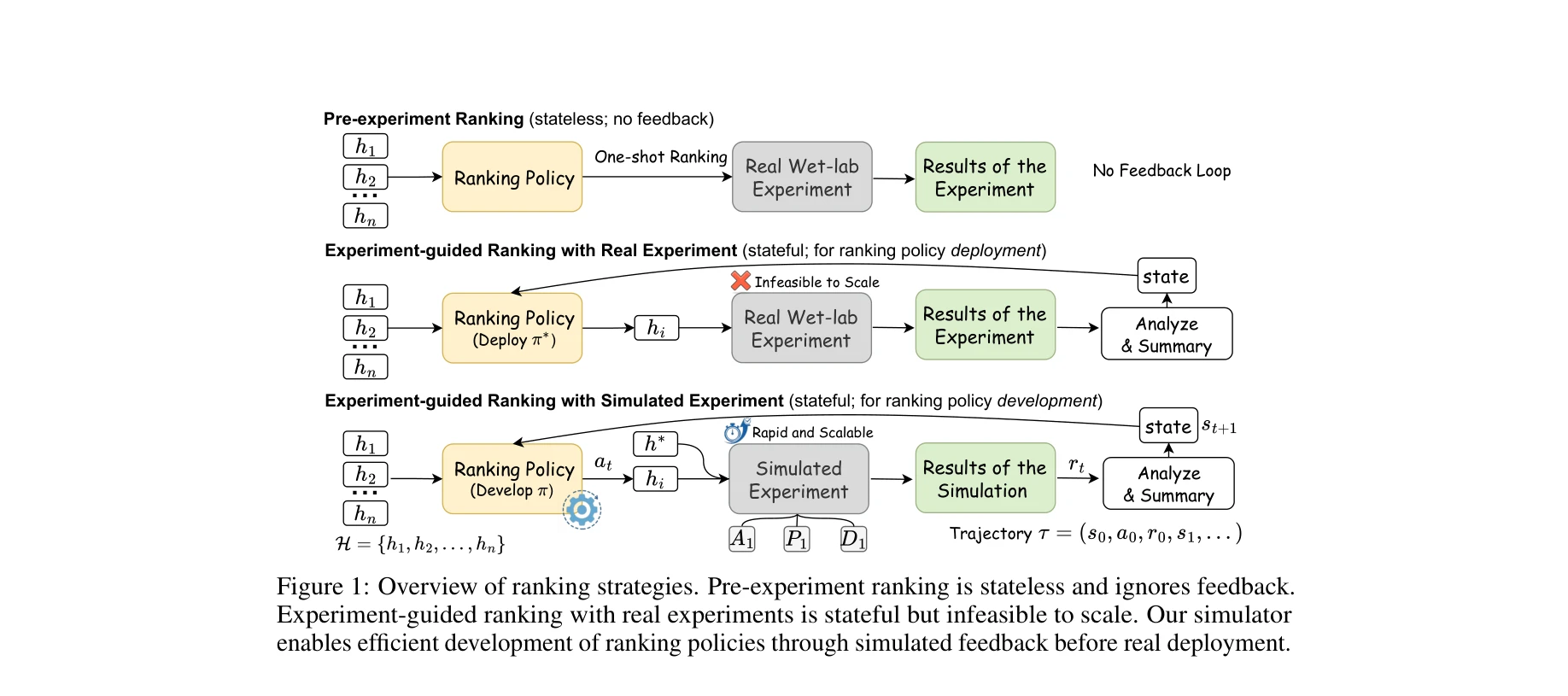
그림 1: 랭킹 전략의 개요. 사전 실험 랭킹(pre-experiment ranking)은 피드백이 없으며, 실제 실험 기반 랭킹은 상태 의존적이지만 확장 불가능하고, 시뮬레이터 기반 접근은 신속하고 확장 가능함
본 논문은 자동 과학 발견(automated scientific discovery)에서 가설 순위 지정(hypothesis ranking)을 위해 시뮬레이션된 실험 피드백(simulated experimental feedback)을 활용하는 새로운 과제를 제안한다. 실험실 실험이 비싸고 처리량이 제한적인 자연과학 영역에서, 실제 실험을 반복 수행하지 않으면서도 실험 기반 순위 지정 정책을 개발할 수 있는 고충실도(high-fidelity) 시뮬레이터와 맥락 내 강화학습(in-context reinforcement learning, ICRL) 프레임워크를 제시한다.
Motivation
Known: 기존 가설 순위 지정 연구들(Yang et al., 2025; Si et al., 2024)은 언어 모델의 내부 추론에만 의존하는 사전 실험 랭킹(pre-experiment ranking)에 초점을 맞추고 있음. 이는 효율적이지만 실제 실험의 반복적이고 피드백 기반의 성질을 간과함.
Gap: 실제 과학적 발견은 이전 실험 결과에 기반하여 다음 실험할 가설을 동적으로 조정하는 실험 기반 순위 지정(experiment-guided ranking)이 필요하나, 화학, 재료과학, 생물학 등 자연과학 영역에서는 높은 비용, 긴 소요 시간, 제한된 처리량으로 인해 반복적 실험을 대규모로 수행하기 불가능함.
Why: 실험의 본질적 목적은 단순히 정답 가설 검증이 아니라, 그 주변의 가설들에 대한 피드백을 제공하여 정답 가설로의 경로(path)를 형성하는 것. 이 원리를 활용하면 가설 공간의 국소 근처에서 실험 피드백을 근사할 수 있음.
Approach: 세 가지 개념적 기초(A1: 국소 최적점 가정, P1: 과학 원리, D1: 논리적 추론)를 바탕으로 정답 가설과의 거리에 기반한 가설 성능 시뮬레이터를 구축하고, 이를 통해 실험 기반 순위 지정 정책을 개발할 수 있는 환경 제공.
Achievement
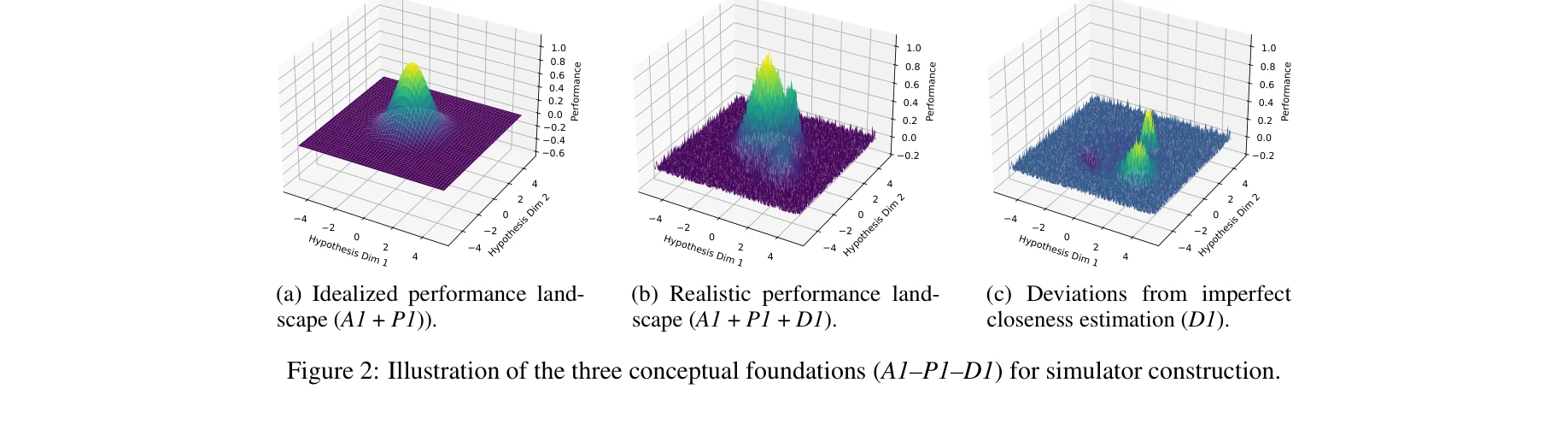
그림 2: 세 개념적 기초(A1–P1–D1)의 예시. (a) 이상적 성능 경관, (b) 실제 성능 경관, (c) 불완전한 유사도 추정으로 인한 편차
시뮬레이터 개발 및 검증: 문헌에서 실험 결과가 보고된 124개 가설로 구성된 데이터셋을 수집하여 시뮬레이터를 검증. 실제 실험 결과와 높은 추세 정렬(trend alignment)을 달성하며, 그 편차가 습식 실험실(wet-lab) 노이즈와 유사함을 확인. 기존 기준선들(Yang et al., 2025에서 개작된 강력한 기준선 포함)을 능가함.
실험 기반 순위 지정 과제 정식화: 상태 의존적이고 동적인 가설 순위 지정이라는 새로운 과제를 형식화하고, 사전 실험 랭킹의 한계를 명확히 함.
클러스터링 기반 에이전트 정책: 가설을 기능적 요소(functional elements)로 분해하고, 공유된 기계적 역할(mechanistic roles)로 그룹화한 뒤, 피드백에 기반하여 유망한 요소의 재조합(recombination)을 우선순위 지정. 사전 실험 기준선 및 제거 연구(ablation) 변형들을 현저히 능가함.
How
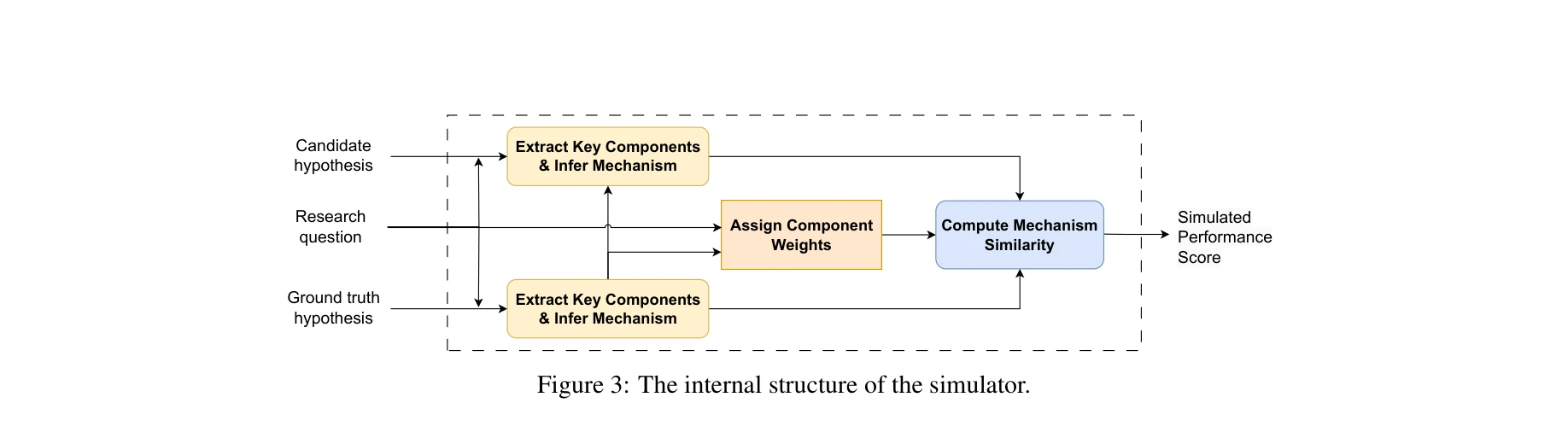
그림 3: 시뮬레이터의 내부 구조
시뮬레이터 구축
개념적 기초 형식화:
A1 (국소 최적점 가정): 정답 가설은 충분히 국소적인 이웃 내에서 우세한 국소 최적점
P1 (과학 원리): 구조나 기능이 유사한 가설들은 더 유사한 실험 결과를 산출
D1 (논리적 추론): 실제의 유사도 표현은 불완전하므로 성능 경관이 편차를 포함 (노이즈, 허위 국소 최적점, 예상 외 계곡 등)
수학적 형식화 (식 1):
```
f(h, h; q, φ(·)) = 1/(2πσ²)^(d/2) · exp(-||φ(h|q) - φ(h*|q)||²/(2σ²))
```
h: 가설, h: 정답 가설, φ: 오라클 임베딩 함수
가우시안 함수로 정답 가설 중심의 일봉형(unimodal) 경관 모델링
실제 성능 함수: 측정된 유사도 φ̂(·)의 불완전성으로 인한 편차를 포함
```
f_real(h) = f(h, h; q, φ) + noise_distortion
```
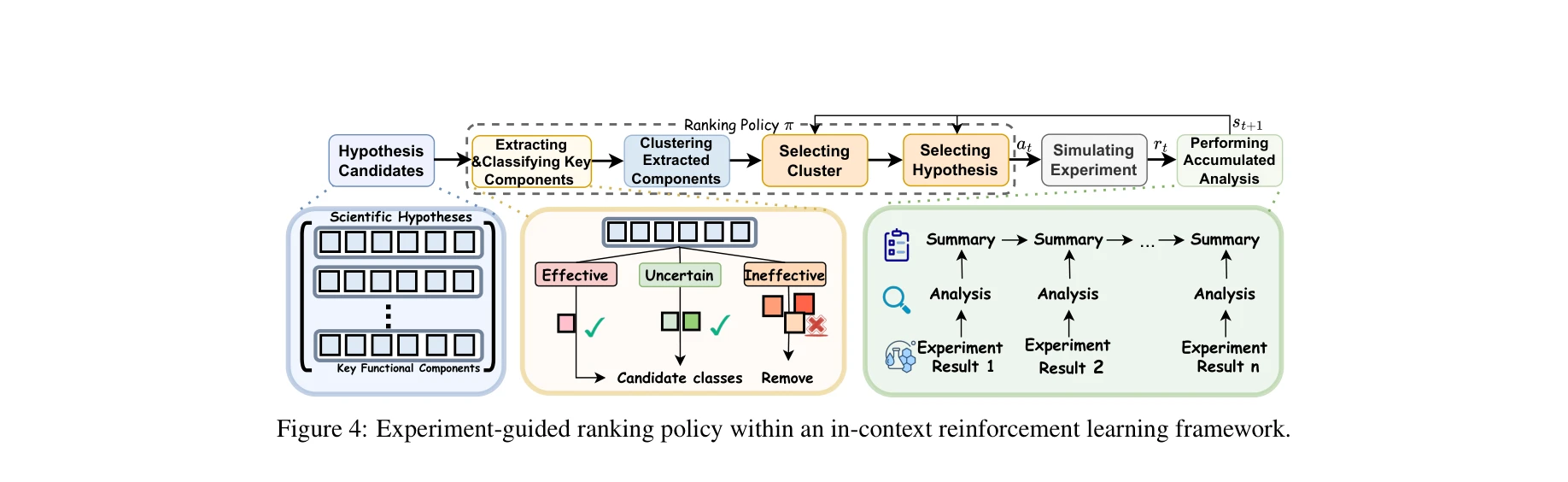
그림 4: 맥락 내 강화학습(in-context RL) 프레임워크 내 실험 기반 순위 지정 정책
실험 기반 순위 지정 정책 (ICRL 프레임워크)
가설 분해(Decomposition): 가설을 기능적 성분으로 분해하여 표현
기계적 역할 클러스터링: 공유된 작용 메커니즘에 따라 성분들을 그룹화
피드백 분석 및 우선순위 지정:
각 시험 가설 결과 분석 → 어느 성분이 성능에 기여했는지 추론
아직 시험하지 않은 가설 중 유망한 성분의 재조합을 포함한 가설 우선순위 지정
순차적 의사결정(sequential decision-making) 문제로 형식화
LLM 에이전트: 맥락 내 예시(in-context examples)를 통해 강화학습 신호 활용
Originality
새로운 과제 정의: 실험 피드백을 활용한 동적 순위 지정(experiment-guided ranking)의 명시적 형식화. 기존 연구는 모두 정적 사전 실험 랭킹에 중점.
시뮬레이터의 원리적 기초: "실험의 목적은 정답 뿐만 아니라 주변 가설에도 피드백 제공"이라는 통찰을 바탕으로 수학적으로 엄밀한 시뮬레이터 개발. 국소 최적점 가정과 구조-성질 대응 원리를 정식화.
ICRL 프레임워크와 정책: 가설 분해 및 기능 성분 클러스터링을 통한 체계적 일반화(generalization). 제한된 피드백으로부터 학습하는 에이전트 설계.
실증적 검증 데이터셋: 문헌에서 실제 실험 결과와 함께 수집한 124개 가설의 큐레이션된 데이터셋 공개로 재현성과 추후 연구 기반 제공.
Limitation & Further Study
A1의 제한성: 국소 최적점 가정(A1)이 항상 성립하지 않을 수 있음. 레이블된 정답 가설이 실제로는 같은 지역 내 다른 더 좋은 가설이 존재할 수 있음. 다만 저자들은 실제 배포 시 더 우수한 가설은 직접 실험을 통해 드러나므로 문제없다고 주장.
시뮬레이터의 완전성: 가우시안 모델이 모든 과학 도메인의 성능 경관을 정확히 포착하지 못할 수 있음. 예를 들어 다봉형(multimodal) 경관이나 비등방(anisotropic) 구조를 가진 문제에서 한계 존재.
도메인 특이성: 현재 데이터셋이 특정 과학 영역(화학, 재료과학 등)에 편중되어 있을 가능성. 생물학, 물리학 등 다른 자연과학 영역에서의 일반화 가능성 검토 필요.
확장성: 시뮬레이터는 높은 차원의 가설 공간에서의 정확성, 다목적 최적화(multi-objective optimization) 상황, 복잡한 상호작용 항(interaction terms)이 있는 가설에 대한 성능 평가 필요.
후속 연구 방향:
도메인별 맞춤형 시뮬레이터 개선
실제 실험과의 통합 파이프라인 구축
더 정교한 LLM 기반 가설 분해 및 클러스터링 기법 개발
다중 정답(multiple ground truths) 상황에서의 확장
Evaluation
총평: 본 논문은 실험 피드백의 불가용성이라는 자동 과학 발견의 핵심 병목을 창의적으로 인식하고, 원리적으로 타당한 시뮬레이터 설계와 함께 동작하는 ICRL 정책을 제시한다. 공개된 데이터셋과 재현 가능한 프레임워크는 커뮤니티에 즉각적인 기여를 제공할 것으로 판단되나, 시뮬레이터의 가우시안 가정과 A1의 현실적 한계에 대한 보완과 더 광범위한 도메인 검증이 필요하다.