Essence
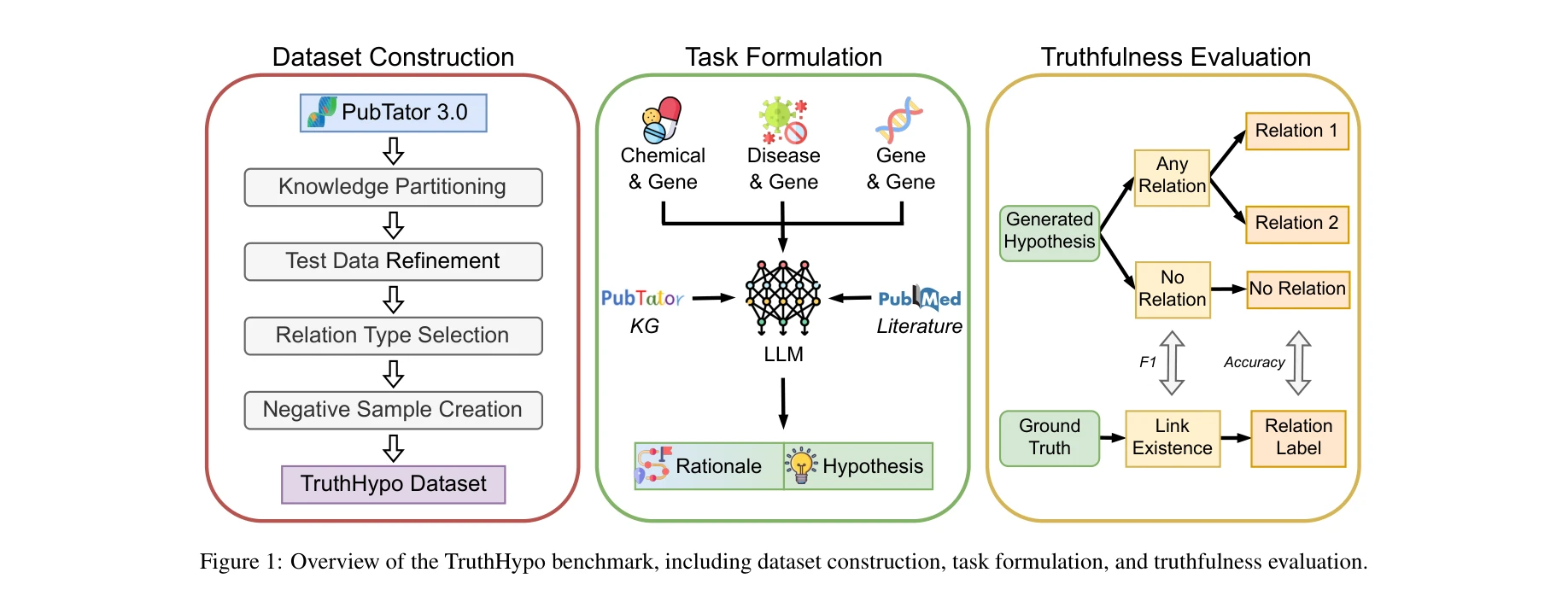
TruthHypo 벤치마크 개요: 데이터셋 구성, 작업 수식화, 진실성 평가를 포함
대규모 언어 모델(LLM)의 생의학 가설 생성 능력을 평가하기 위해 TruthHypo 벤치마크와 KnowHD 할루시네이션 탐지 프레임워크를 제안했으며, LLM이 진실한 가설 생성에서 상당한 어려움을 겪음을 입증하고 지식 기반 접지(groundedness) 점수를 통한 검증 방법을 제시했다.
저자: Guangzhi Xiong, Eric Xie, Corey Williams, Myles Kim, Amir Hassan Shariatmadari, Sikun Guo, Stefan Bekiranov, Aidong Zhang (University of Virginia) | 날짜: 2025 | DOI: 10.24963/ijcai.2025/873
TruthHypo 벤치마크 개요: 데이터셋 구성, 작업 수식화, 진실성 평가를 포함
대규모 언어 모델(LLM)의 생의학 가설 생성 능력을 평가하기 위해 TruthHypo 벤치마크와 KnowHD 할루시네이션 탐지 프레임워크를 제안했으며, LLM이 진실한 가설 생성에서 상당한 어려움을 겪음을 입증하고 지식 기반 접지(groundedness) 점수를 통한 검증 방법을 제시했다.
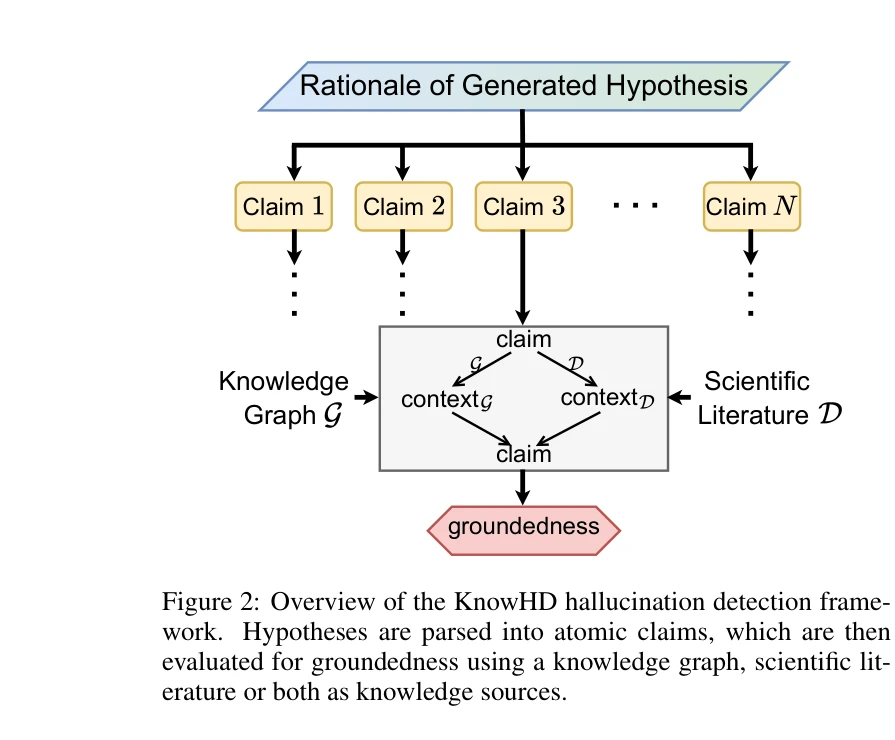
KnowHD 할루시네이션 탐지 프레임워크 개요
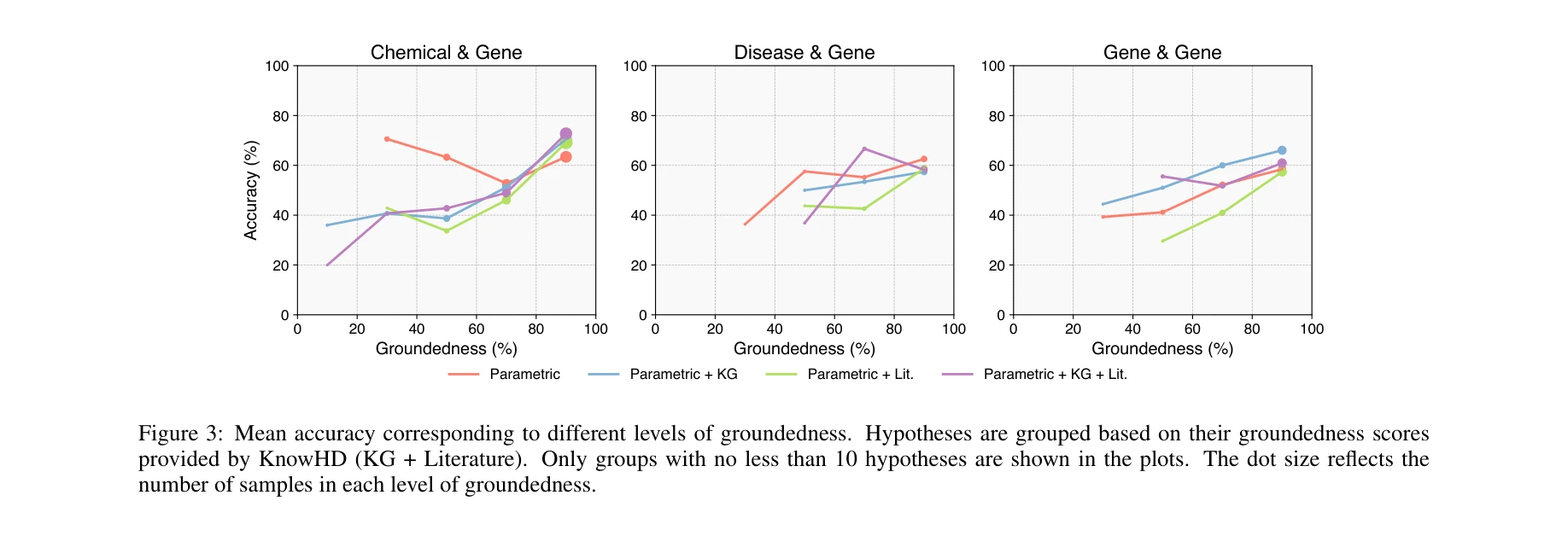
접지도(groundedness) 수준에 따른 평균 정확도. 가설들이 접지도 점수별로 그룹화됨
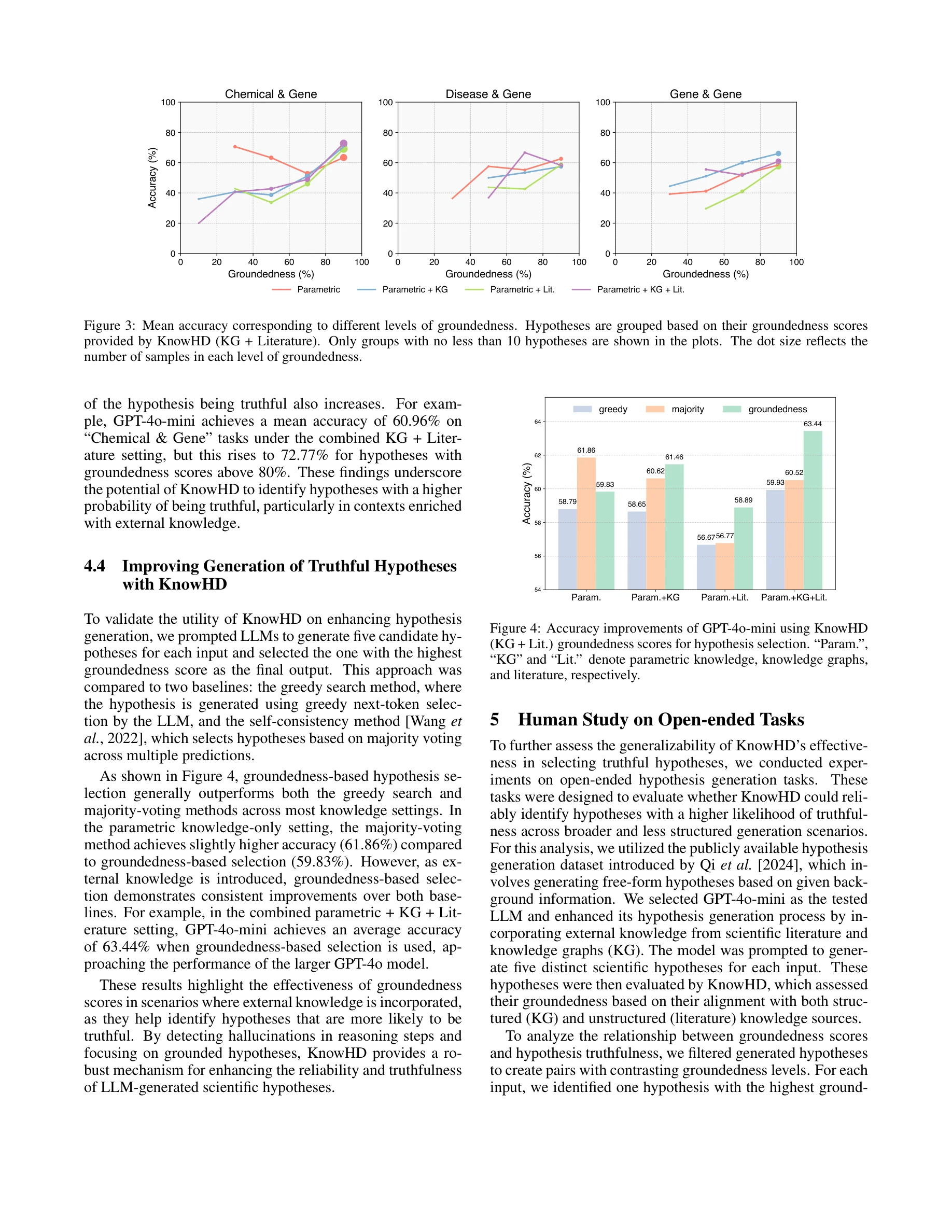
GPT-4o-mini를 사용한 KnowHD의 정확도 개선. 접지도에 따른 필터링 효과 시각화
TruthHypo 벤치마크:
지식 증강 설정:
KnowHD 할루시네이션 탐지:
평가 지표:
한계:
후속 연구:
총평: 본 논문은 LLM 기반 과학 가설 생성의 신뢰성 평가라는 중요한 문제를 체계적으로 다루었으며, 실용적 벤치마크와 할루시네이션 탐지 프레임워크를 제시한 고가치 연구이다. 다만 평가 범위 확대와 KnowHD의 자동화 정도 개선이 향후 과제이다.