Essence
본 논문은 대규모 언어 모델(LLM)을 이용하여 데이터 기반 과학적 가설(hypothesis)을 자동으로 생성하고 개선하는 HypoGeniC 알고리즘을 제안한다. 다중 슬롯 머신(multi-armed bandit) 이론에 영감을 받아 탐색-활용(exploration-exploitation) 균형을 조절하며 반복적으로 가설 풀을 업데이트하여, 소수 샘플 프롬프팅을 크게 능가하는 해석 가능한 가설 기반 분류기를 구현한다.
How
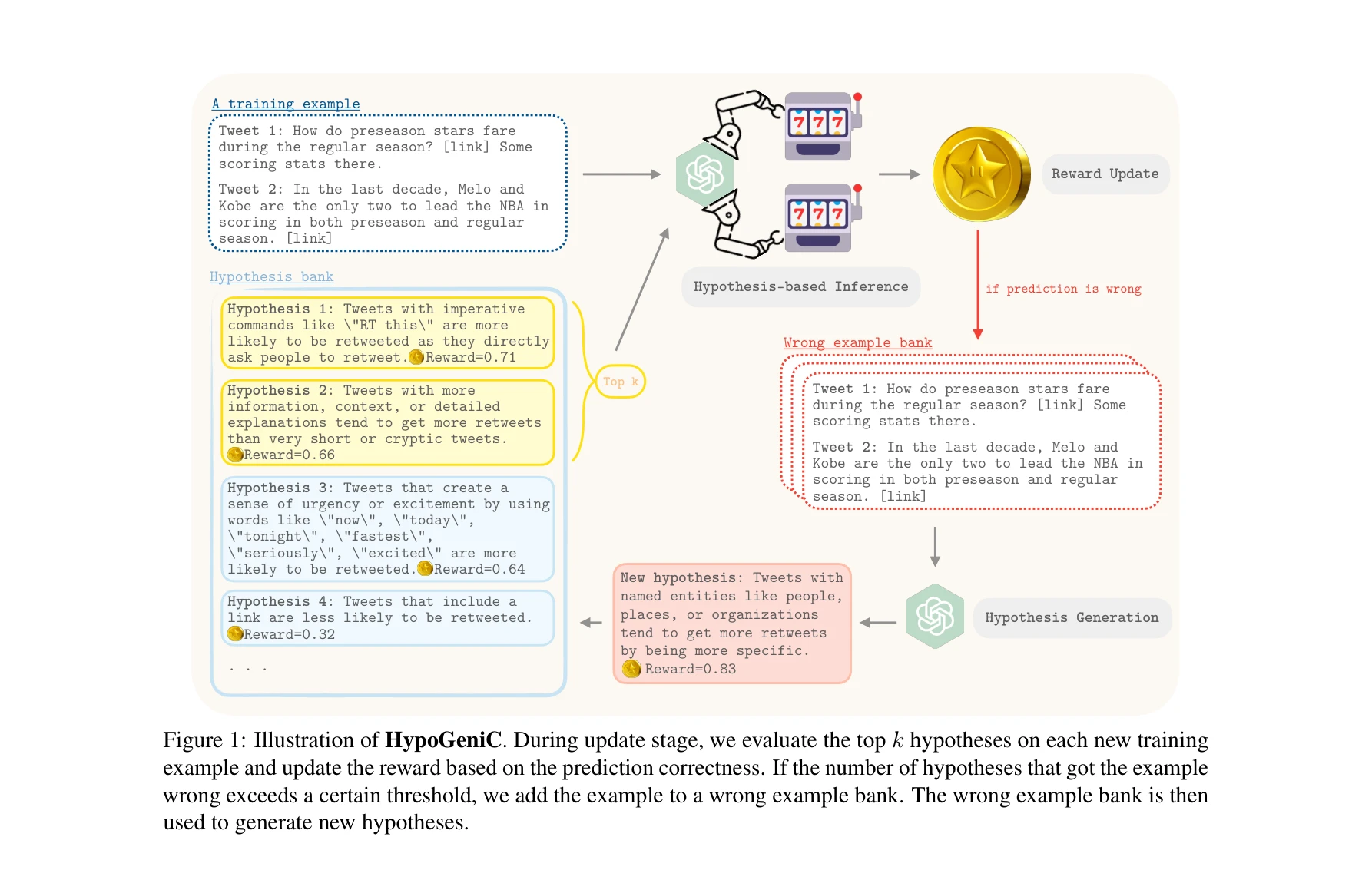
- 초기 가설 생성(Initialization): 훈련 집합 S의 부분집합 S_init에 대해 LLM에 프롬프트하여 고수준의 가설들 생성 → 초기 가설 은행 H 구성
- 반복적 가설 업데이트(Iterative Update):
- 각 훈련 예제 s에 대해 현재 가설 풀에서 보상이 높은 상위 k개 가설 선정
- 각 가설으로 s를 예측하고 정확성 평가 후 보상 업데이트
- 오예측 가설 수가 임계값 이상이면 s를 틀린 예제 은행 W에 추가
- |W|이 최대값 w_max에 도달하면 W의 예제들로부터 새 가설 생성 및 통합
- UCB 기반 보상 함수:
```
r_i = [정확도 항] + α√(log t / |S_i|)
```
첫 번째 항은 가설의 훈련 정확도, 두 번째 항은 탐색 보너스로 선택 빈도가 낮은 가설을 장려
- 다양한 추론 전략:
- Best-accuracy hypothesis: 가장 높은 정확도의 단일 가설 사용
- Filter and weighted vote: 관련 가설들 필터링 후 가중 투표
- Single-step adaptive inference: 한 번의 장문 프롬프트로 가장 적절한 가설 선정
- Two-step adaptive inference: 적절한 가설 선정과 예측을 두 단계로 분리
Evaluation
Novelty: 4.5/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 LLM을 과학적 가설 생성에 활용하는 새로운 시도로, 다중 슬롯 머신 이론에 기반한 체계적이고 실용적인 알고리즘을 제시하며 실증적으로 강력한 결과를 도출했다. 특히 생성된 가설의 모델 간 호환성과 해석 가능성은 LLM의 일반화 능력을 시사하는 중요한 발견이다. 다만, 더 깊은 이론적 분석과 실제 과학 커뮤니티와의 협력을 통한 가설 품질의 검증이 이루어진다면 더욱 설득력 있는 기여가 될 것으로 기대된다.