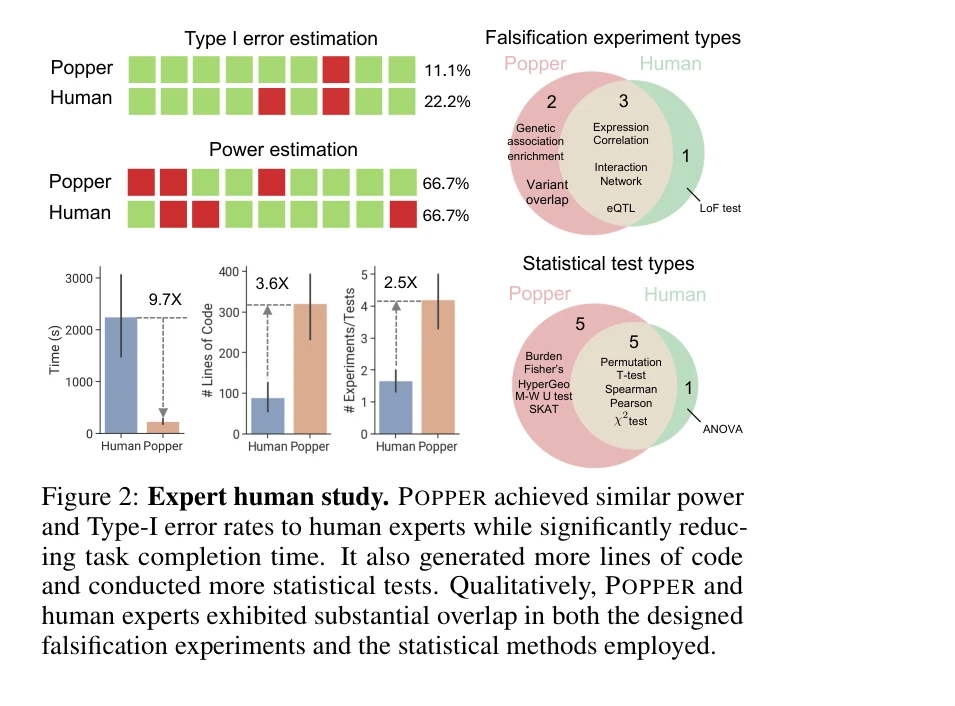
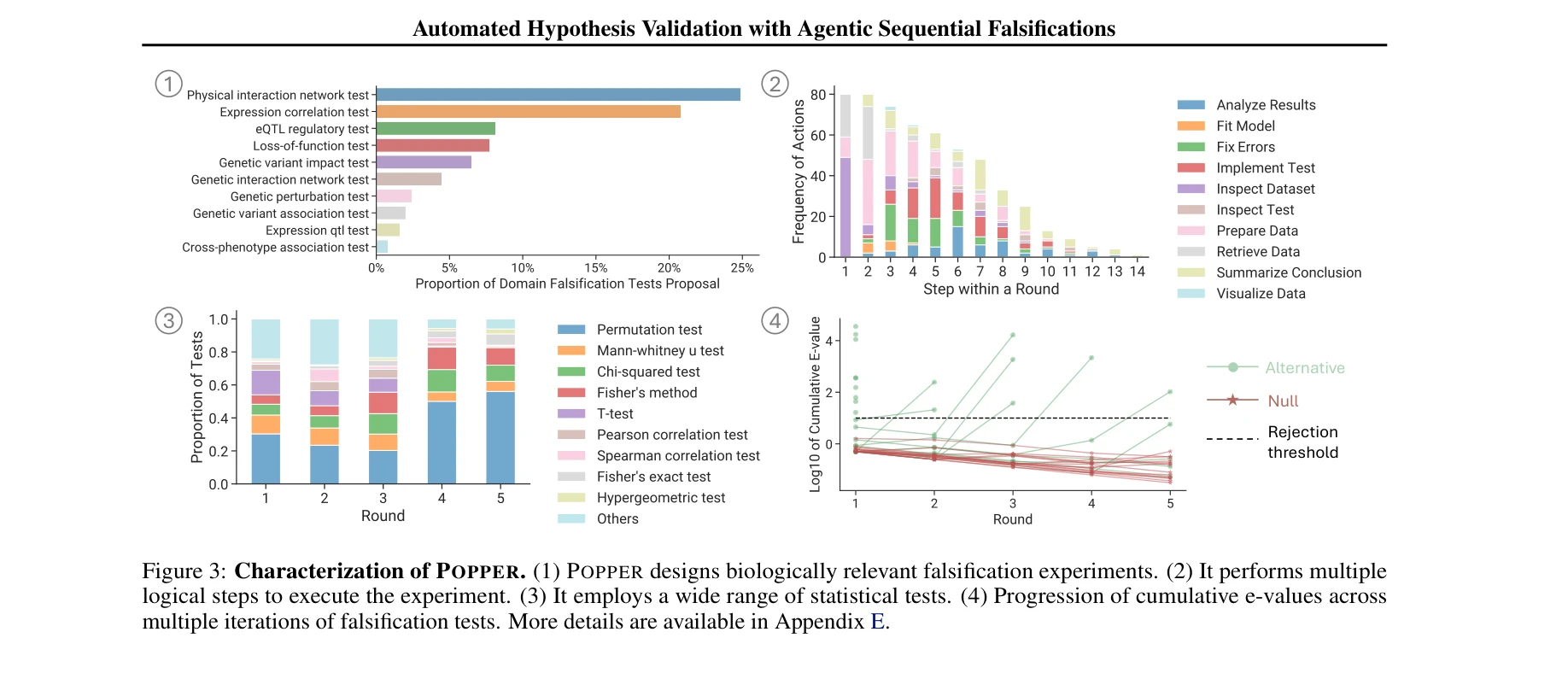
Essence

POPPER 프레임워크 개요: 실험 설계 에이전트가 반박 실험을 제안하고, 실행 에이전트가 p-값을 생성하며, 순차적 검정 프레임워크가 누적 증거를 집계
대규모 언어모델(LLM)이 생성하는 자유형식 가설을 자동으로 검증하기 위해 칼 포퍼의 반박 원칙(falsification principle)을 활용한 POPPER 프레임워크를 제안한다. 엄격한 제1종 오류 제어(Type-I error control)와 순차적 e-값 집계를 통해 통계적으로 타당한 가설 검증을 대규모로 수행 가능하게 한다.